在过去的几个月里,我在数据科学领域里遇到一个术语:马尔可夫链蒙特卡罗(MCMC)。在博客或文章里,每次看到这个语,我都会摇摇头,有几次我试着学习MCMC和贝叶斯推理,但每次一开始,就很快放弃了。我学习新技术的方式都是把它应用到一个实际问题上。
通过使用一些数据和一本应用实战的书(Bayesian Methods for Hackers),我终于通过一个实际项目弄懂了MCMC。像往常一样,当把这些技术概念应用到实际问题中时,理解它们要比阅读书上的抽象概念更容易。本文通过介绍Python中的MCMC实现过程,最终教会了我使用这个强大的建模和分析工具。
本项目的完整代码和相关数据在GitHub上可以找到。本文重点讨论了应用程序和结果,涵盖了很多有深度的内容。
介绍
实际生活中的数据永远不是完美的,但我们仍然可以通过正确的模型从噪音数据中提取有价值的信息。
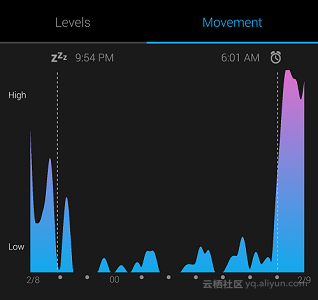
典型睡眠数据
本项目的目的是使用睡眠数据创建一个模型,该模型指定了睡眠的后验概率作为一个时间函数。由于时间是一个连续变量,因为指定整个后验分布是比较困难的,所以我们转向接近于分布的方法-MCMC。
概率分布的选择
在使用MCMC之前,我们需要确定适当的函数来给睡眠的后验概率分布建模。最简单方法是通过可视化的方式进行数据检查,入睡的时间函数的观察结果如下图所示:
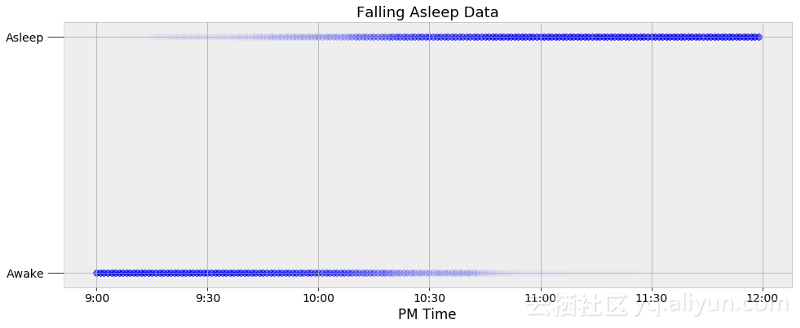
睡眠数据
在图上,每个数据节点被标记为一个点,点的强度表明了在指定时间的观测次数。我的表只记录入睡的时间,所以为了扩大数据量,我在时间点两边的每一分钟都加上了节点。如果手表记录我在晚上10:05分睡着了,那么之前的每分钟都被表示为0(清醒),之后的每分钟都表示为1(入睡)。这将会把大约60个晚上的观测扩展到11340个数据节点。
可以看到,我总是于晚上10:00之后入睡,我们想要创建一个获取从醒到睡的概率转换的模型。当模型在一个精确的时间从清醒(0)到入睡(1)转换的时候,我们可以给模型用一个简单的阶梯函数,因为我不会每晚都在同一时间入睡,所以我们需要一个函数来把转换过程建模为渐变过程。给定数据的最佳选择是一个在0和1之间平稳转换的逻辑函数。以下是入睡概率作为时间函数的逻辑方程。
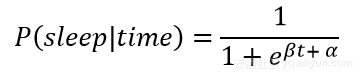
β(beta)和α(alpha)是我们在MCMC过程中必须学习的模型参数。如下所示具有不同参数的逻辑函数:
逻辑函数适合这些数据,因为入睡转换的概率是逐渐的,同时获取了我的睡眠样本的变化。我们希望能为函数增加一个时间变量t,并找出入睡的概率,它必须在0和1之间。为了创建这个模型,我们通过一个分类的技术作为MCMC,用数据来找到最佳的α和β参数。
马尔可夫链蒙特卡罗(MCMC)
MCMC是从概率分布中抽样以构造最可能分布的一类方法。我们不能直接计算逻辑分布,所以我们为函数的参数(α和β)生成数千个称为样本的数值,以创建分布的近似值。MCMC背后的思想是,随着生成更多的样本,近似值会越来越接近实际的分布。
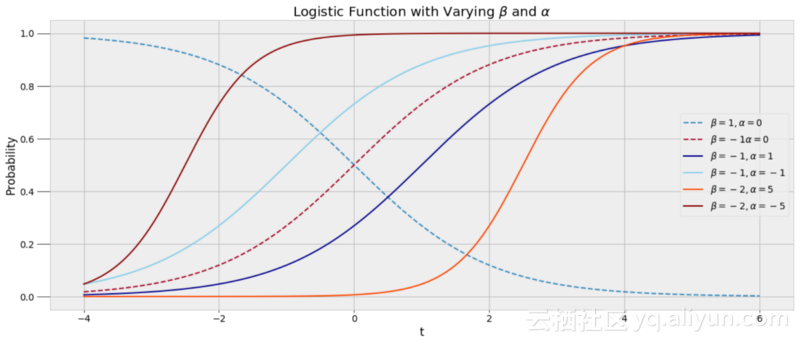
MCMC方法有两个部分,蒙特卡罗(Monte Carlo)是指使用重复随机样本来获得数值结果的通用技术。蒙特卡罗可以被认为是进行很多次的实验,每次改变模型中的变量并观察反应。通过选择随机值,我们可以研究参数空间的一大部分,可能的变量值的范围。参数空间,如下图所示:
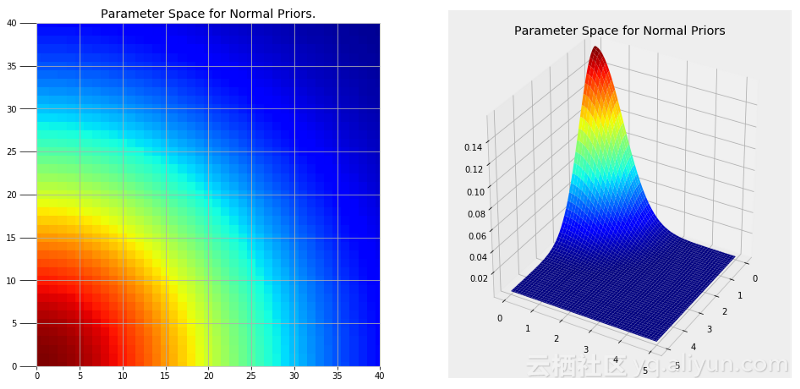
很显然,我们不能尝试图中的每个点,但是通过从较高概率(红色)的区域随机抽样,我们可以创建最可能的模型。
马尔可夫链(Markov Chain)
马尔可夫链是当前状态被下一个状态所依赖的过程。马尔可夫链是不记录状态的,因为只有当前的状态才是重要的,而它如何到达那个状态并不重要。如果这有点难以理解,那么考虑一个日常现象,天气。如果我们想预测明天的天气,只能根据今天的天气来进行一个合理的预测。如果今天下雪了,我们查看一下下雪后第二天的天气分布的历史数据,以预测明天是什么天气的概率。马尔可夫链的概念是,我们不需要一定知道一个过程的整个历史数据来预测下一个输出,相似的现象在许多现实情况中都能很好地预测。
MCMC结合了马尔可夫链和蒙特卡罗的思想,是一种基于当前值对分布的参数重复抽取随机值的方法。每个值的样本都是随机的,但是这些值的选择受到当前状态和参数的假定先验分布的限制。MCMC可以看作是逐渐收敛到实际分布的随机游动。
为了抽取α和β的随机值,我们需要假设这些值的先验分布。由于我们没有预先给参数假设,所以可以使用一个正态分布。正态分布或高斯分布由平均值定义,表明了数据的位置、方差和分布范围。下图是具有不同平均值和范围的几个正态分布:
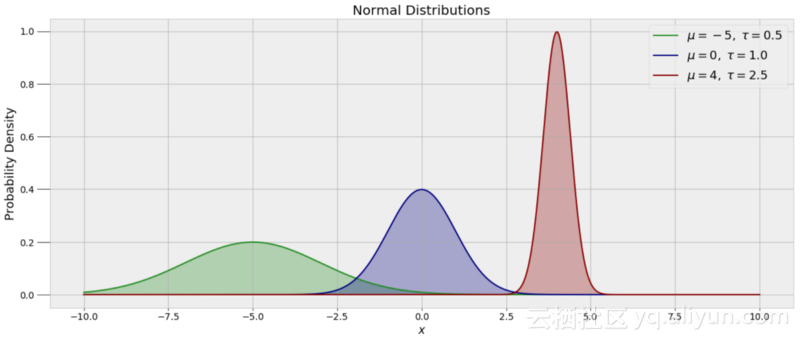
我们使用的特定MCMC算法称为Metropolis Hastings。为了将观测数据与模型联系起来,每次绘制一组随机值时,该算法都会根据数据进行评估。如果这些随机值与数据不一致,则会被拒绝,并且模型保持在当前状态。反之,如果与数据一致,则将这些随机值分配给参数并变成当前状态。这个过程持续一定数量的迭代,那么模型的精确度就会随着迭代数量的增加而提高。
综上所述,用MCMC解决问题的基本步骤如下:
(1)选择α和β以及逻辑函数的参数初始值集合;
(2)根据当前状态给α和β随机分配新的值;
(3)检查新的随机值是否符合观测值。如果不符合,则拒绝这些随机值,并返回到先前状态,反之,要是符合,则接受,并更新为新的当前状态;
(4)如需迭代,则重复步骤2和3;
算法返回其生成的所有α和β的值。然后,我们可以使用这些值的平均值作为逻辑函数中最有可能的α和β最终值。MCMC不能返回“True”值,而是返回一个分布的近似值。由已有数据得到的睡眠概率,其最终模型是具有α和β平均值的逻辑函数。
Python的实现
为了在Python中实现MCMC,我们将使用贝叶斯推理库PyMC3,它对大部分细节进行了抽象,使我们能够创建模型而不是空有理论。
下面的代码创建了具有参数α和β、概率p和观察值的完整模型。步骤变量引用特定的算法,并且变量sleep_trace保存了由模型生成的所有参数值。
withpm.Model() as sleep_model:
# Create the alpha and beta parameters
# Assume a normal distribution
alpha=pm.Normal('alpha', mu=0.0, tau=0.05, testval=0.0)
beta=pm.Normal('beta', mu=0.0, tau=0.05, testval=0.0)
# The sleep probability is modeled as a logistic function
p=pm.Deterministic('p', 1. / (1. +tt.exp(beta * time + alpha)))
# Create the bernoulli parameter which uses observed data to inform the algorithm
observed=pm.Bernoulli('obs', p, observed=sleep_obs)
# Using Metropolis Hastings Sampling
step=pm.Metropolis()
# Draw the specified number of samples
sleep_trace=pm.sample(N_SAMPLES, step=step);为了更好地了解代码的运行,我们可以看下所有的模型运行过程中所产生的α和β值。
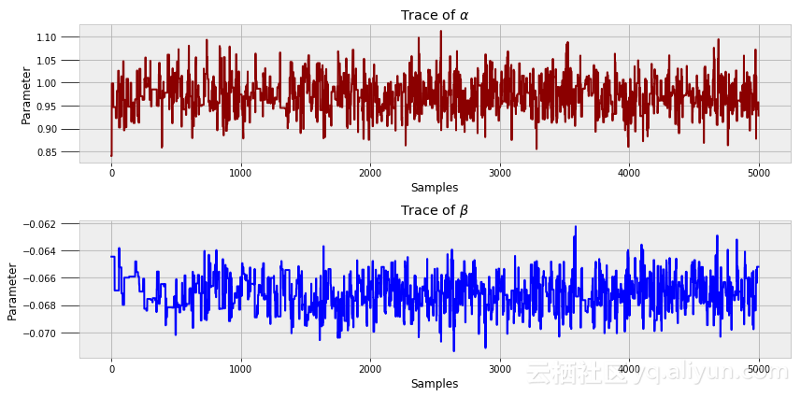
上图被称为轨迹图。我们可以看到,每个状态都与先前的马尔可夫链相关,但其值在蒙特卡罗抽样中振荡明显。
在MCMC中,很常见的做法是丢弃多达90%的轨迹。算法不立即收敛到真实分布,而且初始值往往也不准确。之后的参数值通常会更好一些,这意味着应该用它们来构建模型。我们使用了10000个样本,并丢弃了前面的50%,但是在企业级应用中可能会使用成百上千个或数百万个样本。
MCMC收敛到真实值,但评估收敛可能是很困难的。如果我们想要最精确的结果,这是一个重要的因素。PyMC3库已经创建了用于评估模型质量的函数,包括轨迹图和自相关图。
pm.traceplot(sleep_trace, ['alpha', 'beta'])pm.autocorrplot(sleep_trace, ['alpha', 'beta'])
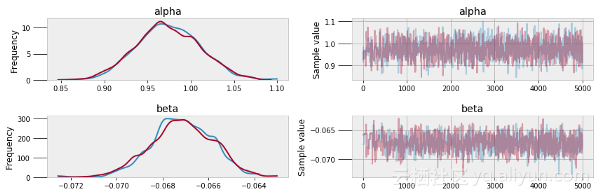
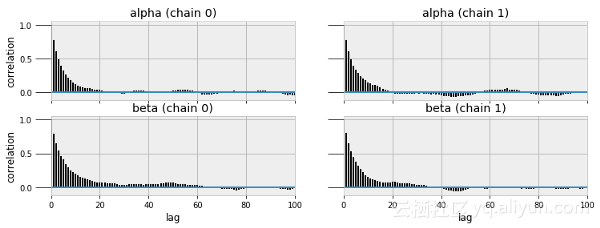
轨迹图(上) 和自相关图(下)
睡眠模型
在最终建立和运行模型之后,现在应该使用了。我们将最后5000个α和β样本的平均值作为最有可能的参数值,这允许我们创建单个曲线图来模拟指定时间之后的入睡概率:
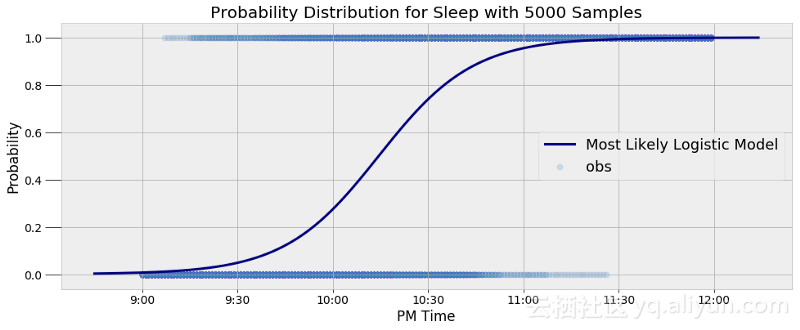
该模型能很好地表示数据,还获取了我入睡模式固有的变化,它不是给出一个结果,而是给出一个概率。例如,可以查询该模型以找出我在指定时间入睡的概率,并找到概率超过50%的时间点:
晚上9点半入睡概率: 4.80%.
晚上9点半入睡概率: 27.44%.
晚上10点入睡概率: 73.91%.
在晚上10点14分,入睡概率提高到了50%以上。
可以看到我入睡的平均时间是晚上10点14分左右。
这些值是给定数据的最可能的估计值。然而,会有这些概率相关的不确定性,因为模型是近似的。为了表示这种不确定性,我们可以在一个给定的时间点使用所有α和β的样本来进行入睡概率预测,然后根据结果绘制柱状:
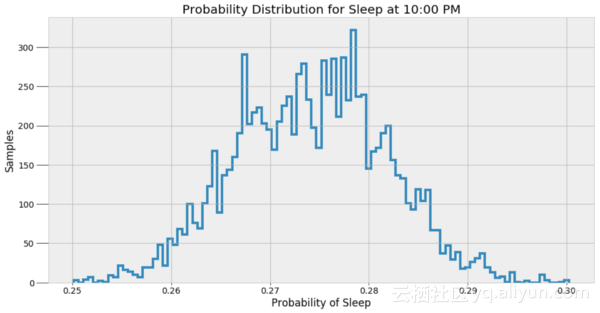
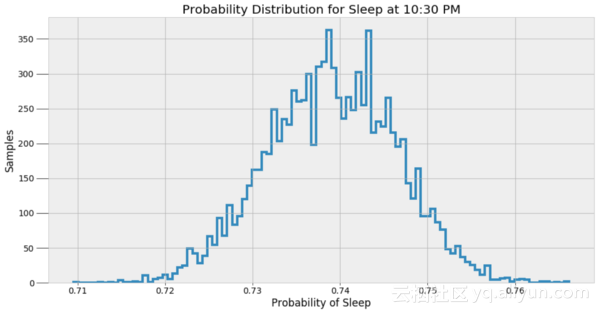
上述结果给出了一个更好的MCMC模型能实际做到的指标。这个方法并没有找到一个正确答案,而是可能值的一个样本。贝叶斯推理是有实际用处的,因为它以概率的形式表示预测的结果。我们可以说得到一个最有可能的答案,但是更准确的说法应该是任何预测都是一系列值的范围。
睡醒模型
可以用我早上睡醒的相关数据来找到一个类似的模型。我通常在早上6点起床,下图根据观察结果显示了从睡觉到睡醒的最终模型。
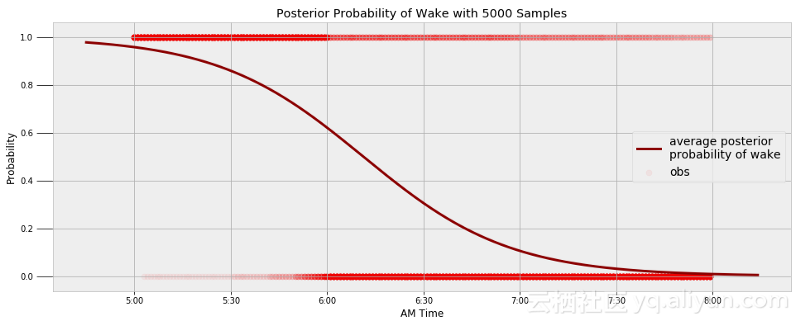
可以通过模型来发现我在某一指定时间入睡的概率和最有可能睡醒的时间。
早上5点半睡醒的概率: 14.10%.
早上6点睡醒的概率: 37.94%.
早上6点半睡醒的概率: 69.49%.
在早上6点11分睡醒的概率超过50%。
入睡持续时间
最后一个我想创建的是入睡时间模型。首先,我们需要找到一个函数来模拟数据的分布,但只能通过检查数据来找到。
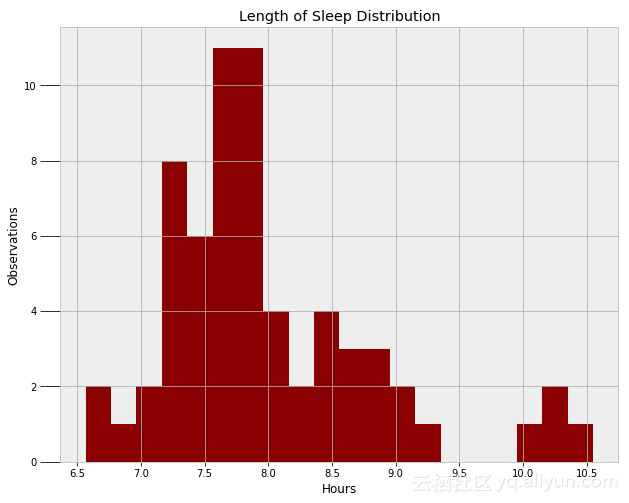
一个普通的分布即可实现,但它不会获取右边的离群点。可以使用两个相互独立的正态分布来表示这两种模式,但是,我会使用一个偏态分布。偏态分布有三个参数,平均值、方差、偏差,并且这三个参数必须从MCMC算法中进行学习。下面的代码创建模型并实现Metropolis Hastings抽样:
withpm.Model() asduration_model:
# Three parameters to sample
alpha_skew=pm.Normal('alpha_skew', mu=0, tau=0.5, testval=3.0)
mu_ =pm.Normal('mu', mu=0, tau=0.5, testval=7.4)
tau_ =pm.Normal('tau', mu=0, tau=0.5, testval=1.0)
# Duration is a deterministic variable
duration_ =pm.SkewNormal('duration', alpha=alpha_skew, mu= mu_,
sd=1/tau_, observed= duration)
# Metropolis Hastings for sampling
step=pm.Metropolis()
duration_trace=pm.sample(N_SAMPLES, step=step)现在,我们可以使用三个参数的平均值来构造最有可能的分布。下图表示数据的最终偏态分布:
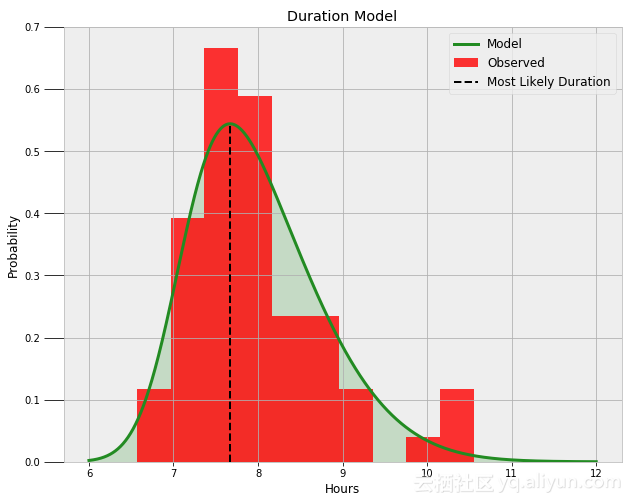
上图看起来很合乎实际情况,通过查询模型可以发现我至少获得一定的入睡持续时间,和最可能的入睡时间范围的概率:
入睡至少持续6.5小时的概率= 99.16%.
入睡至少持续8小时的概率= 44.53%.
入睡至少持续9小时的概率= 10.94%.
入睡最可能持续的时间是7.67小时
结论
通过完成这个项目,告诉我们解决问题的重要性是最好解决实际生活中的问题。数据科学需要不断地进行知识积累,最有效的方法就是有了问题尽快开始。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Markov Chain Monte Carlo in Python》
作者:William Koehrsen
译者:奥特曼,审校:袁虎。
文章为简译,更为详细的内容,请查看原文