前几天一个客户数据库主实例告警,诊断过程中发现是由一个慢SQL导致的数据库故障,而在排查逐步深入之后却发现这个现象的不可思议。
问题描述
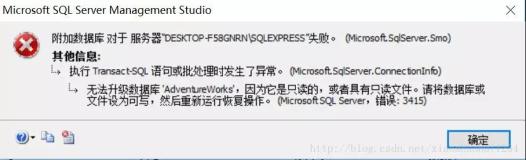
2016年12日09日,大概9点26分左右,一个客户的生产库主实例发出告警,告警信息如下:
MySQL实例超过五分钟没有更新。这个告警信息简单解释下就是持续五分钟无法获取该实例的信息。
同时开发人员还反映,从12月09日凌晨1点开始,已经出现一些数据库请求超时的现象,直到出现告警信息之后业务恢复正常。
问题排查
1、监控进程排查
该数据库系统使用袋鼠云EasyDB进行性能监控以及告警,easydb服务端无法获取agent方的信息,那么首要任务,就是检查easydb agent是否存活。
从上图可见,easydb进程工作正常。那么接下来就要从数据库以及服务器层面去排查
2、MySQL error log
先看下MySQL error日志有没有报错信息的记录。登陆主机,首先了解MySQL的安装情况:
| [root@XXXXXX ~]# ps -ef|grep mysqld|egrep -v mysqld_safe ... ... /home/my3304/bin/mysqld --defaults-file=/home/my3304/my.cnf --basedir=/home/my3304 --datadir=/home/my3304/data --plugin-dir=/home/my3304/lib/plugin --log-error=/home/my3304/log/alert.log --open-files-limit=65535 --pid-file=/home/my3304/run/mysqld.pid --socket=/home/my3304/run/mysql.sock --port=3304 ... ... |
通过查看进程状态信息,我们可以看到本地启动的mysql实例和mysql的一些配置信息,可以找到日志存放路径。
查看了服务器上告警实例的MySQL error log,发现12月09日上午09点16分开始出现大量这样的报错,一直持续到09点48分
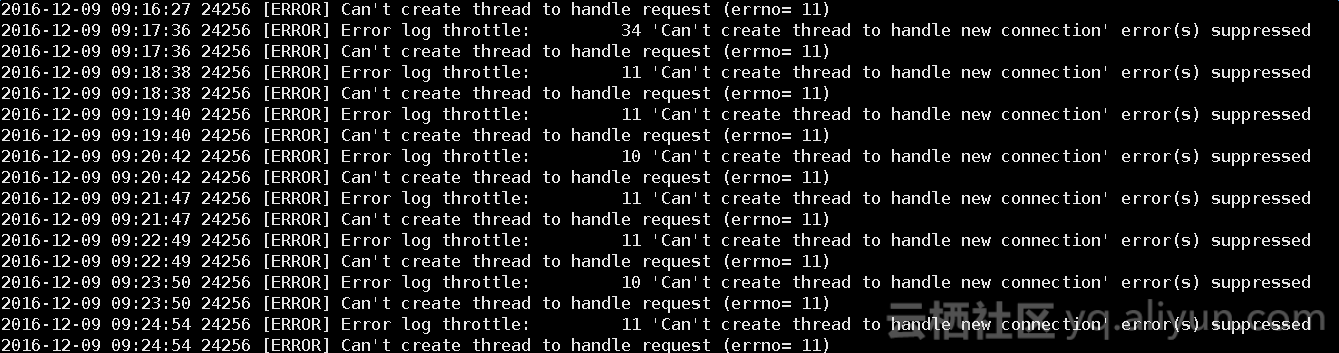
简单分析一下报错信息的含义:
[root@XXXXXX bin]# ./perror 11
OS error code 11: Resource temporarily unavailable
报错的信息大致意思是,资源暂时不可用,那么这个资源指的是什么?就是thread。从这里可以看出,数据库连接数太多了,并且包含大量的活跃连接数请求。
从现象来看,是有些因素导致数据库连接数飙升,而造成应用无法连接的后果
3、性能指标
接下来看下,数据库以及主机各方面的具体性能指标,连接数是否真的出现飙升,与之相关的还有没有其他的异常指标?
系统安装了Easydb,我们可以通过性能图形,清晰地看到具体哪些性能指标出现了问题。
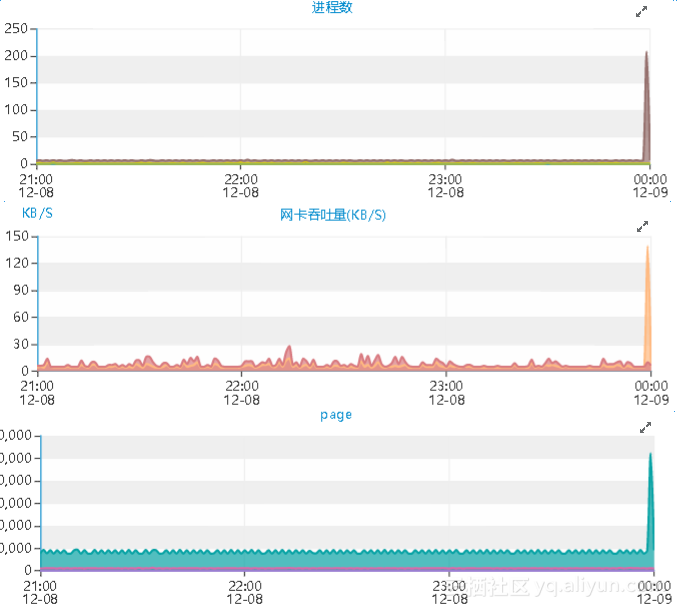
通过查看该告警实例性能指标的曲线图,发现从12月09日凌晨1点左右开始,出现连接数上涨的现象,上午09:16左右开始已经无法持续增长,直到09点50分左右基本完全释放。这一点和刚才看到的error log中的报错时间段基本吻合。
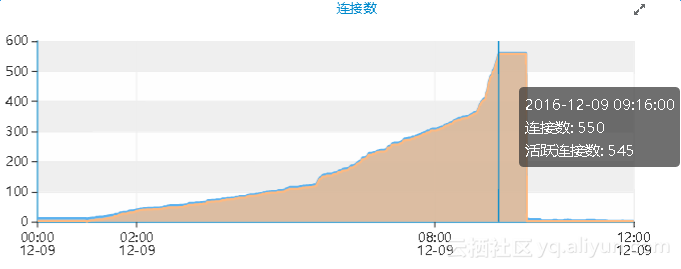
与主机的TCP连接趋势图基本吻合
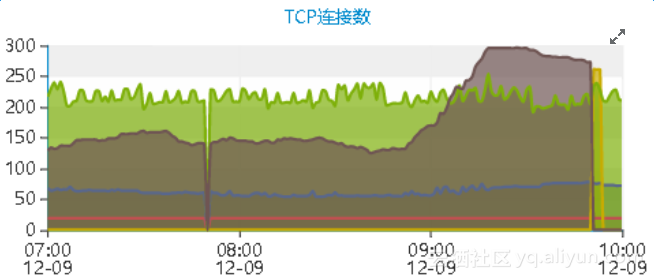
那么,接下来的任务就是要找到造成连接数飙升或者说大部分连接不释放的原因。继续对其他的性能指标的图形进行了观察。而其余的资源消耗却低得出人意料。
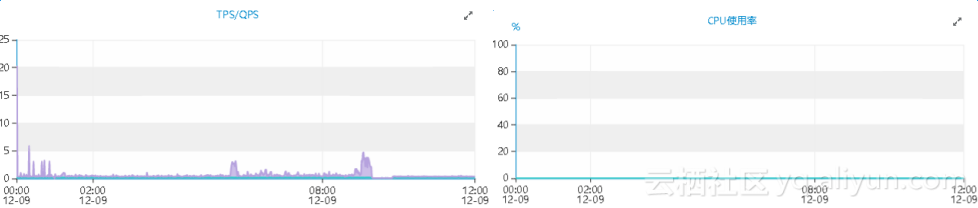
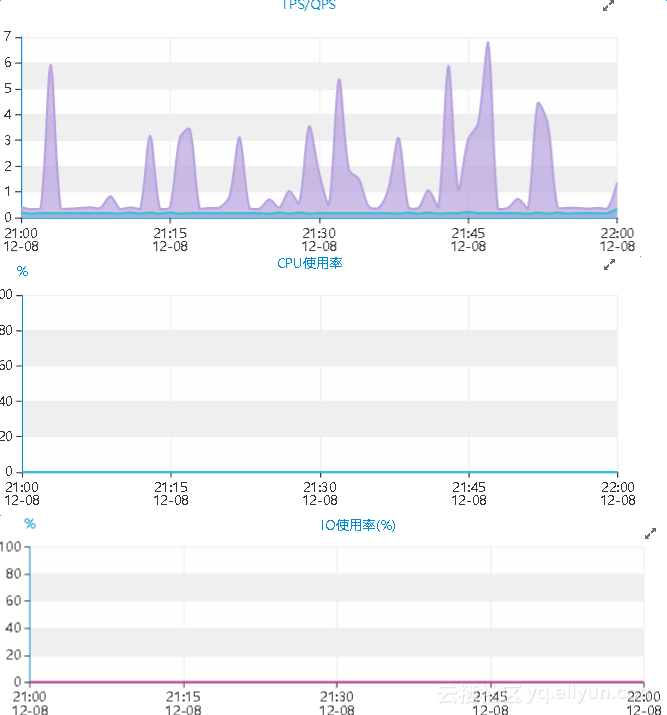
数据库TPS、QPS与CPU使用率:
主机的CPU使用率以及io情况:
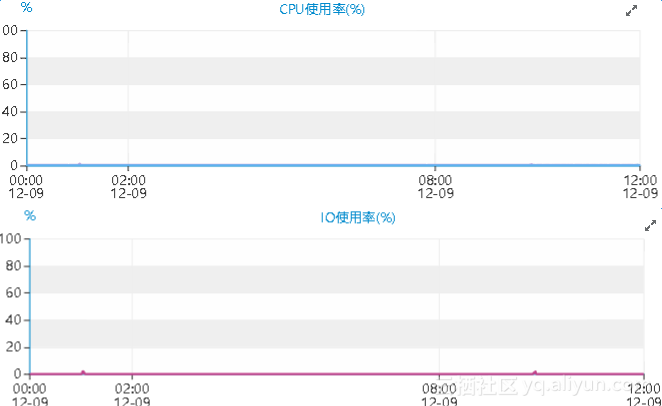
期间的QPS、TPS极低,并且cpu以及io资源完全处于空闲状态,那么期间的线程大部分应该是处于被阻塞的状态。
而另外几个关键的性能指标,在09点50分左右出现和连接数变化趋势相反的极端,这点很出人意料。
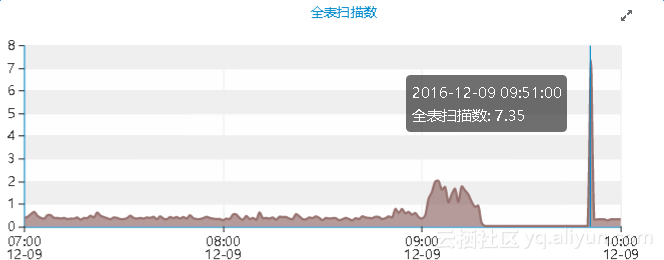
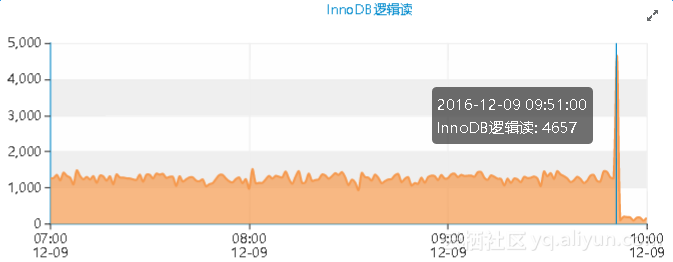
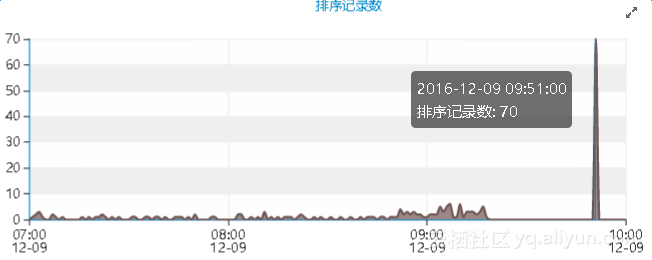
除此之外,反常的性能曲线图还包括主机的io吞吐量以及网络吞吐量等资源:
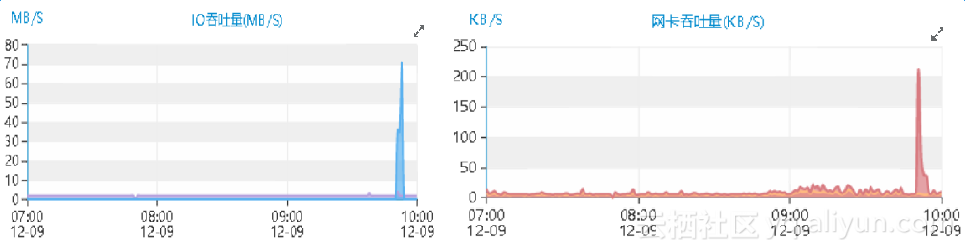
先来分析下,09点50分之前的情况。这段时间的性能数据,简单概述下,就是连接数上涨,而资源利用率极低。
这种情况的出现,一般来说有两个导致因素:一是锁等待;第二是慢查询。两者的共性就是某些SQL或者事务造成的连锁阻塞,而最终全局或大范围被阻塞。
然后看一下锁等待的情况,
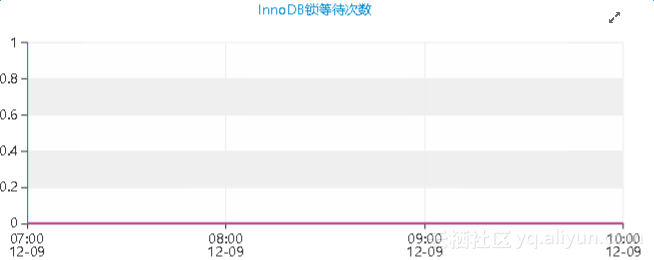
那么,分析到这里,问题基本可以定位为慢SQL导致的
4、MySQL 慢日志
接下来,目标似乎变得比较明朗了。就是找到出现阻塞现象的慢SQL。
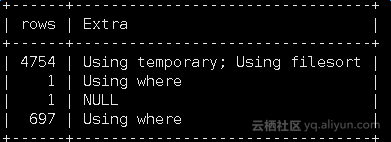
从09:00到10:00的慢日志报表中,发现了两个执行时间超长的SQL

直观地看,12月08日晚上09点11分左右执行一个SQL,这个SQL执行大概消耗12h的时间!而12月09日01点02分执行的FLUSH TABLE操作,需要等待这个SQL执行完成。而FLUSH TABLE被阻塞,就意味着,接下来的任何SQL操作都会被阻塞。
单从这个现象来看,可以屡清前面发现的一些线索了:
1.凌晨一点开始的应用报错,出现在FLUSH TABLE被阻塞之后,从这时候开始,可以新建连接,而SQL无法执行。这也是后面被阻塞的线程都处于活跃状态的原因
2.上午09点多出现的告警信息,是因为此时数据库已经无法再新建连接,agent进程无法连接mysql数据库,持续5s后出现告警
3.09点16分到09点50分左右这段时间,MySQL error log报错与连接数曲线图吻合,说明09点16分thread资源耗尽,而09点50分左右阻塞者执行完成,连接数释放
4.两类曲线图变化反常关系解释,慢SQL从12月08日21点11分开始执行,经历45453s的时间,恰好是上午09点50分左右,此时SQL开始返回数据,逻辑读以及全表扫描指标急剧升高,同时还发现,这个SQL可能是有排序操作的
那么,这两个时间点,都在做什么?
与开发进行了简单的沟通,并且排查了easydb的日志。前一天晚上09点11分是一个开发人员的报表查询;而凌晨1点的FLUSH操作,是全备任务的一个执行阶段。

那么似乎是这个开发人员跑了个很烂的SQL导致的?
接下来的排查,发现情况好像并没这么乐观。
分析下这个SQL,语句如下:

执行计划如下:

从extras,我们看到,这个SQL使用到了临时表排序,并且貌似t_business_contacts表的关联列没有索引,ALL type下使用到了Block Nested Loop算法
那么,实际执行情况怎样?
![]()
开发人员反映,昨晚的执行,只用了2s不到的时间就获取到了结果,而刚才的执行情况也确实如此。
由于系统自运行以来,整体负载一直比较低,查询的数据量也不大,那么即使这个SQL语句有着不好的执行计划,执行的时间应该也是比较乐观的。但是从前面的现象来看,凌晨一点主库上发起全备任务时,这个SQL应该是还在执行。
再次查看了21:16前后的系统负载,CPU以及IO资源基本处于空闲,而QPS也极低,而12月08日也没有任何的慢SQL记录
如果只是1s多的时间就返回了数据,那么这个慢SQL从何而来?或许还有别的误操作,导致同样的SQL请求被发起,而这个相同的SQL卡在某个执行的阶段?从前面分析到的现象来看,这个SQL直到第二天上午09点50才开始返回数据。
仔细查看各项指标,发现几个系统指标在09号0点左右出现高峰,但是仍然无法解释09点16分执行的SQL被卡住
先保留这个疑问,这个SQL无疑是有着较大的性能问题的,我们先对其做个优化处理。
按照如下操作,添加两个索引:
alter table t_business_contacts add index idx_oi(org_id),ALGORITHM=INPLACE,LOCK=NONE;
alter table t_system_organization add index idx_on(ORG_NAME),ALGORITHM=INPLACE,LOCK=NONE;
从新的执行计划,发现有了一些改观,关联字段通过索引等值匹配,没有了Block Nested Loop算法,而in查询取值池太大导致优化器没有选择索引,优化器仍然使用了总行数只有4000+的t_sup_qualifie_info表作为驱动表
接下来看下实际的执行效果:

执行效率有了接近40倍的提升!目前来看,优化效果还比较乐观
5、message日志
前面还提到一个CASE,就是业务恢复的时间,基本是和告警时间相吻合。从前面的发现来看,现在的问题就是为什么业务在数据库实例连接数释放之前就恢复了正常。
结合OS message日志,很快就解除了疑惑。上午09点16分开始的日志内容如下:
![]()
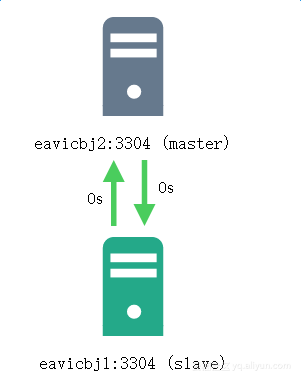
从这里可以看到,在目标实例不可用的时候,keepalived进行了主备的切换,因此,接下来的业务连接的都是原来的备实例。Easydb上看到现在的复制关系拓扑图如下:
6、SQL执行场景沟通
目前为止,问题的产生过程、告警原因、业务恢复过程,都能够有一个合理的解释了。那么现在的疑问就是,这个SQL为什么会这么慢?
尝试与开发人员进行沟通,看看这个SQL当时执行的场景如何。
开发人员表示,当时是使用的客户端工具进行的这个SQL的查询,人工查询后将结果汇总到Excel,而当时的查询过程不到两秒钟的时间。那么这个SQL实质就是一个每天进行的一个报表查询,这个流程已经进行了三个月,为何今天才出现问题?
结合SQL执行期间的业务压力以及系统的负载,基本很难构造出一个导致这个SQL执行如此耗时的场景。毕竟这个SQL执行不是数百上千秒,而是12h,这与前面手工执行验证的1.13s还是有着巨大差异的。
从数据库的慢SQL来看,有这样一个SQL执行慢,是肯定的,但是与开发人员的描述有极不相符,这个期间可能还是有些其他的异常情况,由于没有历史的show processlist数据,目前很难找到原因,看是否下次能够在某些情况下重现类似的问题。
根因分析
这是一个典型的连锁阻塞,过程如下:
1.昨晚某个时间点,某个客户端发起一个SQL请求,很长时间没有获得响应
2.凌晨的自动备份执行到FLUSH TABLE阶段,等待这个SQL执行完成
3.之后的SQL请求都被FLUSH TABLE阻塞
4.活跃连接数持续增加,导致Thread资源不可用,应用报错
5.EasyDB agent无法获取实例信息,持续5分钟触发告警;keepalived检测到主库不可用,自动切库
根因:
1.SQL执行效率太低(原因未知)
2.主库上有自动备份任务
后续
对SQL进行了优化之后,当天晚上关掉了所有主库的自动备份任务,防止类似的情况导致主库不可用;
至于SQL执行过程中到底发生了什么,确实很值得探究,但可惜的是,MySQL对历史性能数据视图支持的并不好,通过工具分析到的性能指标却又和这个SQL的执行情况完全相悖,或许如果能够构造出一个这样的场景,可能会有发现。