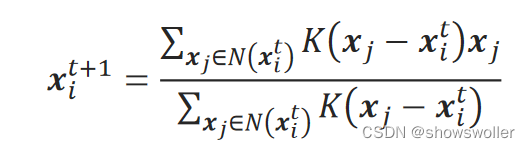文章系列链接
前言
第一篇文章SLS机器学习介绍(01):时序统计建模上周更新完,一下子炸出了很多潜伏的业内高手,忽的发现集团内部各个业务线都针对时序分析存在一定的需求。大家私信问我业务线上的具体方法,在此针对遇到的通用问题予以陈述(权且抛砖引玉,希望各位大牛提供更好的建议和方法):
-
数据的高频抖动如何处理?
- 在业务需求能满足的条件下,进可能的对数据做聚合操作,用窗口策略消除抖动
- 若不能粗粒度的聚合,我一般会选择窗口滤波操作,在针对滤波后的数据进行一次去异常点操作
- 改变检测策略,将问题变成一个回归问题,引入多维度特征,对目标进行预测
-
历史训练数据如何选择?
- 针对自己的时序数据,需要先进行简单的摸底操作,选择合适的模型,是不是有明显的周期?是不是有明显的趋势?
-
这么多方法该如何选择?
- 针对单指标预测的方法,需要采用多种算法模型进行预测,将得到的结果也要集成起来,降低误报操作
- 可以针对历史上的全量报警样本,设计一套报警聚合规则,在一定容忍度的条件下得到较好的结果
摘要
在大型互联网企业中,对海量KPI(关键性能指标)进行监控和异常检测是确保服务质量和可靠性的重要手段。基于互联网的服务型企业(如线上购物、社交网络、搜索引擎等)通过监控各种系统及应用的数以万计的KPI(如CPU利用率、每秒请求量等)来确保服务可靠性。KPI上的异常通常反映了其相关应用上可能出现故障,如服务器故障、网络负载过高、外部攻击等。因而,异常检测技术被广泛用于及时检测异常事件以达到快速止损的目的。
问题背景
大多数异常检测算法(如雅虎的EDAGS,Twitter的BreakoutDetection,FaceBook的prophet)都需要为每条KPI单独建立异常检测模型,在面对海量KPI时,会产生极大的模型选择、参数调优、模型训练及异常标注开销。幸运的是,由于许多KPI之间存在隐含的关联性,它们是较为相似的。如果我们能够找到这些相似的KPI(例如在一个负载均衡的服务器集群中每个服务器上的每秒请求量KPI是相似的),将它们划分为若干聚类簇,则可以在每个聚类簇中应用相同的异常检测模型,从而大大降低各项开销。
序列聚类建模

问题定义
在同一个业务指标的前提下:
- 查找出当前时序序列中有哪些相似的曲线形态?(单条曲线的多形态分解)
- 多条KPI指标曲线有哪些曲线的形态类似?(N条曲线形态聚类)
相似性度量
本文主要从时间对齐的多条时序KPI中进行相似性度量,时间点上的指标的相似性和时序曲线形态的相似性
- 时间点聚类(时间上的相似性)
1.1 闵可夫斯基距离:衡量数值点之间距离的一种常见的方法,假设$P=(x_1,x_2,...,x_n)$和$Q=(y_1,y_2,...,y_n)$,则具体的公式如下:
$$ dist = (\sum_{i=1}^{n}|x_i-y_i|^p)^{\frac{1}{p}} $$
当$p=1$时,表示曼哈顿距离;$p=2$时,表示欧几里得距离;当p趋近于无穷大时,该距离转换为切比雪夫距离,具体如下式所式:
$$ \lim_{p->\infty}(\sum_{i=1}^{n}|x_i-y_i|^p)^{\frac{1}{p}} = max_{i=1}^{n}|x_i-y_i| $$
闵可夫斯基距离比较直观,但是它与数据的分布无关,具有一定的局限性,如果x方向的幅值远远大于y方向的幅值,这个距离公式就会过度方法x维度的作用。因此在加算前,需要对数据进行变换(去均值,除以标准差)。这种方法在假设数据各个维度不相关的情况下,利用数据分布的特性计算出不同的距离。如果数据维度之间数据相关,这时该类距离就不合适了!
1.2 马氏距离:若不同维度之间存在相关性和尺度变换等关系,需要使用一种变化规则,将当前空间中的向量变换到另一个可以简单度量的空间中去测量。假设样本之间的协方差矩阵是$\Sigma$,利用矩阵分解(LU分解)可以转换为下三角矩阵和上三角矩阵的乘积:$\Sigma=LL^T$。消除不同维度之间的相关性和尺度变换,需要对样本x做如下处理:$z=L^{-1}(x-\mu)$,经过处理的向量就可以利用欧式距离进行度量。
$$ dist = z^Tz = (x-\mu)^T\Sigma^{-1}(x-\mu) $$
- 形状之间的相似性(空间上的结构相似性)
2.1 编辑距离
如何去比较两个不同长度的字符串的相似性?给定两个字符串,由一个转成另一个所需要的最小编辑操作,其中需要有三个操作,相同位置字符的替换、对字符串中某个位置进行插入与删除。具体的递归表达式如下:
$$ dp[i][j] = \begin{cases} 0 & i=0,j = 0 \\ j & i=0,j>0 \\ i & i>0,j=0 \\ min(dp[i][j-1] + 1, dp[i-1][j] + 1, dp[i-1][j-1]) & S_1(i) = S_2(j) \\ min(dp[i][j-1] + 1, dp[i-1][j] + 1, dp[i-1][j-1] + 1) & S_1(i) \neq S_2(j) \end{cases} $$
2.2 DTW(Dynamic Time Warpping)距离
动态时间规整(Dynamic Time Warping;DTW)是一种将时间规整和距离测度相结合的一种非线性规整技术。主要思想是把未知量均匀地伸长或者缩短,直到与参考模式的长度一致,在这一过程中,未知量的时间轴要不均匀地扭曲或弯折,以使其特征与参考模式特征对正。
DTW(Dynamic Time Warping)距离的计算过程如下:
假设,两个时间序列Q和C,Q={$q_1$,$q_2$,…,$q_n$},C={$c_1$,$c_2$,…,$c_m$}。构造一个(n, m)的矩阵,第(i, j)单元记录两个点$(q_i,c_j)$之间的欧氏距离,$d(q_i,c_j )=|q_i-c_j |$。一条弯折的路径W,由若干个彼此相连的矩阵单元构成,这条路径描述了Q和C之间的一种映射。设第k个单元定义为$w_k=(i,j)_k$,则$w=\{w_1, w_2, w_3, ..., w_K\}, max(n,m) <= K <= n+m-1$。
这条弯折的路径满足如下的条件:
1. 边界条件:$w_1=(1,1)$,且$w_k=(n,m)$
2. 连续性:设$w_k=(a, b)$,$w_{k-1}=(a^{'}, b^{'})$,那么$a-a^{'}<= 1$,$b-b^{'}<=1$
3. 单调性:设$w_k=(a,b)$,$w_{k-1}=(a^{'}, b^{'})$,那么$a-a^{'}>=0, b-b^{'} >=0$
在满足上述条件的多条路径中,最短的,花费最少的一条路径是:
$$ DTW(Q,C) = min\{1/K \sqrt(\sum_{k=1}^{K}w_k)\} $$
DTW距离的计算过程是一个DP过程,先用欧式距离初始化矩阵,然后使用如下递推公式进行求解:
$$ r(i,j) = d(i,j) + min\{r(i-1, j-1), r(i-1, j), r(i, j-1)\} $$
算法步骤
1. 数据预处理
-
数据源:集群中所有集群的多指标度量值(秒级数据)
- SYS:系统运行情况记录(启动时间,负载情况、进程信息等)
- NET:网络设备状态传输情况(TCP、UDP等上行和下行流量等)
- MEMORY:内存使用情况(使用率、交换分区使用情况等)
- CPU/GPU:使用情况
- DISK:磁盘IO情况
-
基本的预处理
- 确定下单条数据的信息(查看某机器某指标的情况)
* and metric_name : machine_022_cpu | select stamp, metric_val order by stamp limit 2000
- 若时序数据含有缺失值,需要将将序列进行补点操作(如果序列缺失小于10%,则模型内部会将缺失数据自动按照邻近值补齐)
- 该数据是按照15秒一个点进行采样的,如果需要进行更粗粒度的操作,需要额外处理
2. 时序数据的降维采样
集群中有相同属性的机器大约为5K台,那么我们就会有经过处理的5K条NET:Tcp的曲线,现在需要对该集合进行聚类,找到其中相似形态的曲线,并发现形态不一致的曲线形态。
- 分段线性表示方法
分段线性表示是一种使用线性模型来对时间序列进行分割的方法,根据不同的分割方法可以使用不同的分割策略来实现,如滑动窗口、自底向上和自顶向下。利用滑动窗口和自底向上方法的时间复杂度为序列长度的平方阶, 而自顶向下的时间复杂度为线性阶。滑动窗口在一些情况下对时间序列的拟合效果较差,不能很好地反映原时间序列的变化信息。 - 分段聚合近似(Piecewise Aggregation Approximation,PAA)表示方法
通过对时间序列进行平均分割并利用分段序列的均值来表示原时间序列的方法。 - 符号化表示方法
符号化表示方法是一种将时间序列转换为字符串序列的过程。在时间序列数据挖掘过程中,传统方法主要依赖于定量数据,远远不能满足数据挖掘领域中分析和解决问题的要求。在数据结构和算法设计中,字符串具有特定的数据存储结构以及较为成熟且高效的操作算法。

本实验中将时序序列将高维度数据降低到长度为300的PAA策略。
3. DBSCAN聚类算法
DBSCAN(Density-BasedSpatial Clustering of Applications with Noise),一种基于密度的聚类方法,即找到被低密度区域分离的稠密区域,要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。
-
其中几个关键术语:
- 密度:空间中任意一点的密度是以该点为圆心,以Eps为半径的圆区域内包含的点数目
- 边界点:空间中某一点的密度,如果小于某一点给定的阈值minPts,则称为边界点
- 噪声点:不属于核心点,也不属于边界点的点,也就是密度为1的点

上图是一般DBSCAN的聚类过程,其中有两个地方可以进行较好的优化:
-
两个参数
- 最近两个聚类中心的距离参数(Eps)
- 最小聚类中心的实例的个数(MinPts)
- 查找一个向量在给定参数情况下的近邻集合
3.1 KD Tree构造
KD(K-Dimensional) Tree,是一种分割K维度数据空间的数据结构。主要应用与多维空间关键数据的搜索(如:范围搜索和近邻搜索)。
function kdtree(list of points pointList, int depth) {
// select axis based on depth so that axis cycles through all valid values
var int axis := depth % k;
// sort point list and choose median as pivot element
select median by axis from pointList;
// create node and construct subtree
node.location := median;
node.leftChild := kdtree(points in pointList before median, depth + 1);
node.rightChild := kdtree(points in pointList before median, depth + 1);
return node;
}上述算法模型中,最大的问题在于轴点的选择,选择好轴点之后,就可以递归去创建这颗树了。
-
建树必须遵循的两个准则:
- 建立的树应当尽量平衡,树越平衡代表着分割得越平均,搜索的时间也就是越少;
- 最大化邻域搜索的剪枝操作;
-
选择轴点的策略
- 对于所有描述子数据(特征矢量),统计在每个维度上的数据方差,挑选出方差中最大值,对应的维度就是分割域的值。数据方差大说明沿着该坐标轴方向上数据点分散的比较开。这个方向上,进行数据分割可以获得最好的平衡。数据点集按照当前选择的维度的值排序,位于正中间的那个数据点,就被选为轴点。
- 实际中会出现问题:理论上空间均匀分布的点,在一个方向上分割,通过计算方差,下一次分割就不会出现在这个方向上,但实际数据往往会不均匀,这样就会出现很多长条的分割,会导致效率降低。
- 为了避免这种情况,候选维度的选择依据是数据范围最大的那一个维度作为分割维度,之后就选择这个维度的中间节点作为轴点,进行分割,分割出来的结果会稍微好一些。
- 实际中也可以通过限制树的高度的时候。

-
邻近搜索策略
- 给定一个KD Tree和一个节点,求KD Tree中离这个节点最近的节点,可以选定一个距离度量的方式。
- 搜索的基本思路:首先通过二叉树搜索(比较待查询节点和分裂节点的分裂维度的值,小于等于就进入左侧分支,大于就进入右侧分支),顺着搜索路径很快能找到最近邻的近似点,也就是与待查询点处于同一个子空间的叶子节点;然后在回溯搜索路径,并判断搜素路径上的其它近邻节点是否有可能距离查询点更近的数据点,直到搜索路径上的候选节点为空时停止。
3.2 参数自动化估计

具体的成分如下图所示:
$$ P(\mu-\sigma \leq X \leq \mu + \sigma) \sim 0.6827 $$
$$ P(\mu-2\sigma \leq X \leq \mu + 2\sigma) \sim 0.9545 $$
$$ P(\mu-3\sigma \leq X \leq \mu + 3\sigma) \sim 0.9973 $$
这里我们假设$(\mu + 2\sigma, \mu + 3\sigma)$的坐在成分为$2.1%$左右,因此我们假设最小的近邻集合中所含有的样本数量为$k=Total Size * 2.1% * 0.5$。
-
具体的参数估计流程如下:
- 计算任意两个样本之间的距离
- 计算每个样本的k-距离值,选择每个样本最近邻的k个样本,将该所有样本的k距离集合进行升序排序,同时记录每个候选距离中对应的点对坐标(去重复之后,用来记录该距离有多少个点)
- 去查找k距离排序之后的若干波动点(见参考文献)
- 使用KMeans聚类,对于找到的候选信息$(eps, minPts)$进行聚类,得到相应的聚类中心
- 然后将该参数送入到DBSCAN中进行聚类,对得到的聚类中心的信息进行判定,得到较好的聚类结果
3.3 DBSCAN具体流程
直观的理解下本节开头关于聚类指标的说明:
- core point:聚类中心向量
- Border Point:某个聚类中心的边界样本点
- MinPts:最少聚类中心的样本点的数量
- $\epsilon$:聚类中心内的最远边缘样本到聚类中心的距离
- Noise Point:噪声样本点

-
DBSCAN算法描述中常用的概念
- 密度可达:样本点p,关于样本点q对于参数${Eps, MinPts}$密度直达,若它满足$p \in Neighbor(q, Eps)$ 且 $|Neighbor(q, Eps)| >= MinPts$
- 密度可达:样本点p,关于样本点q对于参数${Eps, MinPts}$密度可达,若存在一系列的样本点$p_1,...,p_n$(其中$p_1=q$, $p_n=p$)使得对于$i=1,2...,n-1$,样本点$p_i$密度可达
- 密度相连:样本点p,关于样本点q对于参数${Eps, MinPts}$密度相连,若存在一个样本点o,使得p和q均由样本点o密度可达。

- 具体的算法流程
首先,将数据集D中的所有对象标记为为处理状态
for 样本p in 数据集D do
if p 属于某个簇 或者 被标记为噪声 then
continue;
else
检查p的Eps邻域 Neighbor(Eps, p)
if |Neighbor(Eps, p)| < MinPts then
标记对象p为边界点或噪声点
else
标记样本p为核心点,并建立新的簇C,并将p邻域的所有点加入C
for 样本q in Neighbor(Eps, p)中所有未被处理的对象 do
按照邻域样本数量进行判断
end for
end if
end if
end for4. 层次聚类算法

层次聚类是一种很直观的算法,就是一层一层的对数据进行聚类操作,可以自低向上进行合并聚类、也可以自顶向下进行分裂聚类。
- 凝聚式:从点作为个体簇开始,每一个步合并两个最接近的簇
- 分裂式:从包含所有个体的簇开始,每一步分裂一个簇,直到仅剩下单点簇为止
4.1 凝聚层次聚类算法步骤
- 计算邻近度量矩阵
-
repeat
- 合并最接近的两个簇
- 更新邻近度矩阵,以反映新簇与原来簇之间的邻近度量值
- Until 仅剩下一个簇或者达到某个终止条件
平台实验结果
自动参数选择的密度聚类算法
- 调用命令
* | select ts_density_cluster(stamp, metric_val, metric_name)- 聚类结果





-
上述输出结果说明
- 聚类的中心的数量有算法自动生成
- 输出的结果按照所含有的实例数量降序排列
层次聚类算法
- 调用命令
* | select ts_hierarchical_cluster(stamp, metric_val, metric_name, 2)- 聚类结果

- 调用命令
* | select ts_hierarchical_cluster(stamp, metric_val, metric_name, 8)- 聚类结果


-
上述输出结果说明
- 聚类的中心的数量的上限用户可自定义
- 输出的结果按照所含有的实例数量降序排列
查找相似曲线
- 调用命令
* | select ts_similar_instance(stamp, metric_val, metric_name, 'machine_008_cpu')-
返回结果
- machine_008_cpu

- machine_021_cpu

- machine_023_cpu

- machine_008_cpu
硬广时间
日志进阶
阿里云日志服务针对日志提供了完整的解决方案,以下相关功能是日志进阶的必备良药:
- 机器学习语法与函数:https://help.aliyun.com/document_detail/93024.html
- 日志上下文查询:https://help.aliyun.com/document_detail/48148.html
- 快速查询:https://help.aliyun.com/document_detail/88985.html
- 实时分析:https://help.aliyun.com/document_detail/53608.html
- 快速分析:https://help.aliyun.com/document_detail/66275.html
- 基于日志设置告警:https://help.aliyun.com/document_detail/48162.html
- 配置大盘:https://help.aliyun.com/document_detail/69313.html
更多日志进阶内容可以参考:日志服务学习路径。
联系我们
纠错或者帮助文档以及最佳实践贡献,请联系:悟冥
问题咨询请加钉钉群:11775223
Reference
- 微软亚研院的AIOps底层算法: KPI快速聚类
- Yading: Fast Clustering of Large-Scale Time Series Data
- 漫谈:机器学习中距离和相似性度量方法
- 如何理解K-L散度(相对熵)
- 最小编辑距离算法
- DTW Algorithm
- A Piecewise Aggregate Approximation Lower-Bound Estimate for Posteriorgram-based Dynamic Time Warping
- 各类降维方法总结
- 68–95–99.7 rule
- Comment on "Clustering by fast search and find of density peaks"
- Clustering by fast search-and-find of density peaks