我们知道,模型训练的时候使用的数据集是训练集,模型在测试集上的误差近似为泛化误差,而我们更关注的就是泛化误差,所以在离线阶段我们需要解决一个问题,那就是如何将一个数据集 D 划分成训练集 S 和测试集 T ?实际上,离线评估的时候有多种方法可以实现上面的要求,这里介绍一些常用的方法。
留出法
留出法(hold-out)是指将数据集 D 划分成两份互斥的数据集,一份作为训练集 S,一份作为测试集 T,在 S 上训练模型,在 T 上评估模型效果。
留出法的优点是简单好实现,但是也会有一些明显的缺点。比如说划分后的训练集和测试集的大小会严重影响模型最终的评估结果。如果说训练集 S 比较大,测试集 T 比较小,那么评估结果的不够稳定准确,可信度较低;如果说训练集 S 比较小,测试集 T 比较大,那么得到的模型很可能与全量数据集 D 得到的模型有很大的差别,这就降低了评估结果的真实性。通常的做法是,将全量数据集的 2/3~4/5的样本作为训练集,剩余样本作为测试集。
除了划分得到的训练集 S 和测试集 T 的数据量会影响评估结果外,它们的数据分布也会影响评估结果,尽量保证训练集 S 和测试集 T 的数据分布一致,避免由于数据划分引入额外的偏差而对最终结果产生影响。举个具体的例子来说明,有一个包含了 1500 条正样本和 1500 条负样本的数据集,现在使用二分类模型来进行自动分类,假设将 1/3 的数据作为测试集,应该使得测试集正负样本均在 500 条左右;如果测试集由 50 条正样本和 950 条负样本组成,那么评估结果将会因为样本分布差异而导致很大的偏差。
因此,考虑到单次留出法的结果往往不够稳定可靠,我们一般会进行多次留出法实验,每次随机划分,最终将多次得到的实验结论进行平均。
但是在实际工作中,如果不分场景,任何时候都是用随机划分数据集可能会导致一些其他的问题,比如说数据泄露(穿越问题)等。
交叉验证法
交叉验证法(cross validation)先将数据集 D 划分成 k 分互斥的数据子集,即
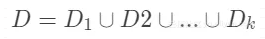
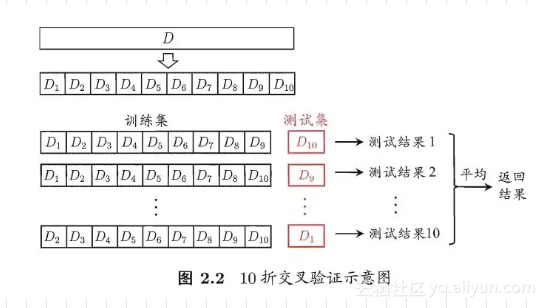
很明显,交叉验证评估结果的稳定性和保真性在很大程度上取决于 k 值的大小,所以交叉验证也叫做k 折交叉验证(k-fold cross validation)。k 常用的取值有 5、10 和 20。
假定数据集 D 中包含了 m 个样本,若令 k=m,则得到了交叉验证法中的一个特例:留一法(leave-one-out,简称 LOO)。留一法的优缺点都很明显。训练 m 个模型,每个模型基本上用到了全部的数据,得到的模型与全部数据集 D 得到的模型更接近,并且不再受随机样本划分方式的影响。但是当样本太多时,即 m 很大时,计算成本非常高。
知道了留一法之后,我们再来看下一个新的评估方法:留P法(leave-p-out,简称LPO)。留P法是每次留下 p 个样本作为测试集,而从 m 个元素中选择 p 个元素有中可能,因此它的计算开销远远高于留一法。
由于存在不平衡分类问题(分类问题中样本里包含的标签的数量失衡,比如二分类中样本量包含的正负样本比例为10:1),基于此,存在一种叫做分层 k 折交叉验证法(stratified-k-fold)。这种方法对每个类别进行 k 折划分,使得每份数据子集中各类别的数据分布与完整数据集分布相一致。比如二分类中进行分层5折交叉验证,正样本有 300 条,负样本有 30 条,将数据划分成 5 分,并且每份数据中有 60 条正样本,6 条负样本。
自助法
自助法(bootstrapping)以自主采样(bootstrap sampling)为基础,使用有放回的重复采样的方式进行训练集、测试集的构建。比如为了构建 m 条样本的训练集,每次从数据集 D 中采样放入训练集,然后有放回重新采样,重复 m 次得到 m 条样本的训练集,然后将将没有出现过的样本作为测试集。
很明显,有一些样本在会被重复采样,多次出现在训练集中,而另外一些样本在训练集从未出现。我们可以计算样本从未在训练集中出现的概率。在每次采样
时,每条样本经过 m 次始终没有被采到的概率是
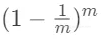
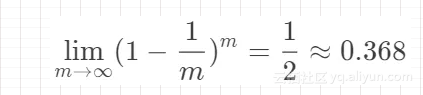
这也就意味着,当数据量很大时,大约有 36.8% 的样本不会出现在训练集中,也就是这些样本都会作为测试集。
留出法和交叉验证法在训练模型时用的数据都只是整个数据集 D 的一个自己,得到的模型会因为训练集大小不一致导致一定的偏差。而自助法能够更好地解决这个问题。但自助法改变了初始数据集的分布,会引入估计偏差,所以在数据量足够时,一般采用留出法和交叉验证法。
练习题
看完这篇文章,我们来做几道练习题来检验下学习成果:
-
试证明自助法中对 m 个样本进行 m 次自助采样,当 m 趋于无穷大时,为什么有 36.8% 的样本从未被选择过?
