
需求背景
影业实时报表开始做法也是按照传统型报表做法一样,直接从阿里云rds写sql查询,随着数据量越来越大,这种做法已经没有办法满足业务扩张,带来的问题响应时间变慢,吞吐量低,我们急需要一种技术方案能满足未来2-3年随着影院增加,数据增长,而报表功能还能很好的满足客户需求技术方案。
业务目标
时间:平均1分钟,像销售报表最差5分钟返回结果。 数据准确性:数据不丢失并且跟业务库保持一直,数据正确性要100%。 数据校对和回溯:数据不准确的时候,能够手动修复报表。
技术挑战
数据幂等:ETL(精卫/Blink) 如何保障业务明细数据变更时间顺序,即:对同一条记录进行 update,如何保障 update 的顺序是正确的;同样对 delete/insert 一样要求。 数据校对:目前试运行阶段,一方面采用新旧报表对比,另外一方面,采用“数据回溯”,如每隔 5 分钟从业务库同步最近 5 分钟的变动数据。 数据查询性能:HybirdDB for Mysql存储中如何保障根据不同条件查询的性能,包括单表查询和多表关联查询。
技术方案
数据架构图
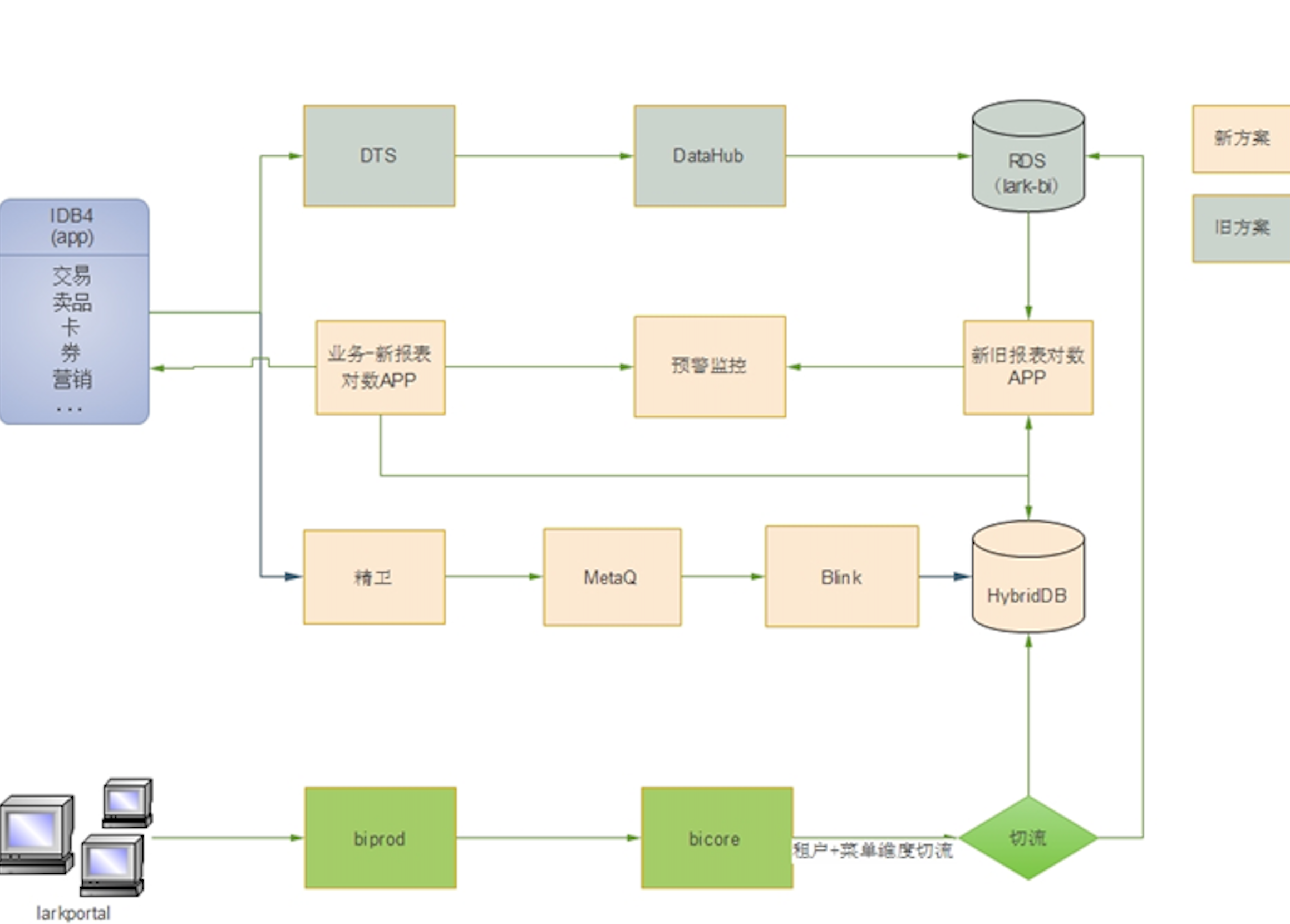
-
集团内部有很多种blink的数据源,如tt、datahub、metaq、notify,而我们在弹外使用了很久metaq,并且实时性也没什么问题,所以就用了metaq作为blink的数据源。
-
精卫发送数据到Metaq,而Blink订阅Metaq数据,整个解析模型现在Blink不支持,这个需要自己Blink UDX函数去转换,这个也需要去了解精卫发送到Metaq的协议,UDX自定义函数。
-
精卫发送数据到Metaq,如下图,目前只支持增量方式,并不支持全量到Metaq,而全量支持只有RDS到RDS,这个也需要去了解精卫发送到Metaq的协议。
整体配置流程
选择自主消费模式

选择TDDL数据源和配置表
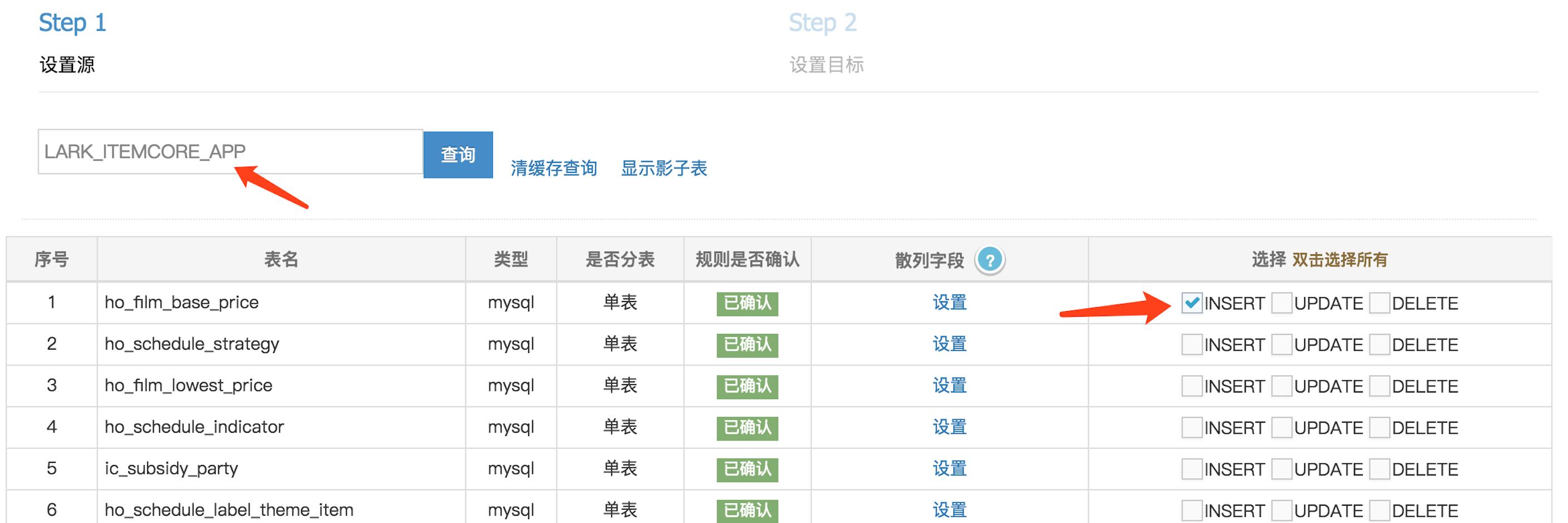
选择链路类型
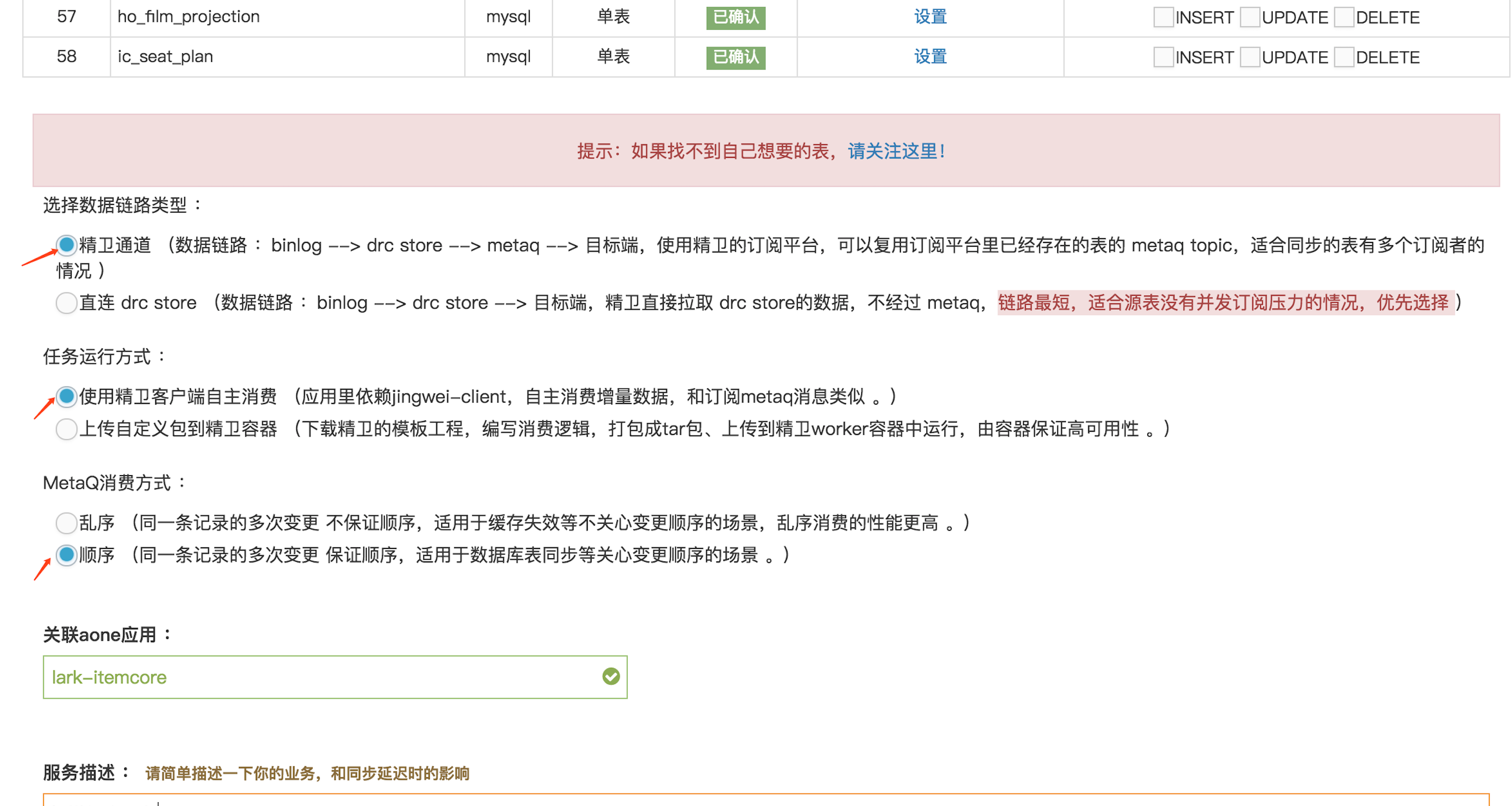
精卫服务配置完成
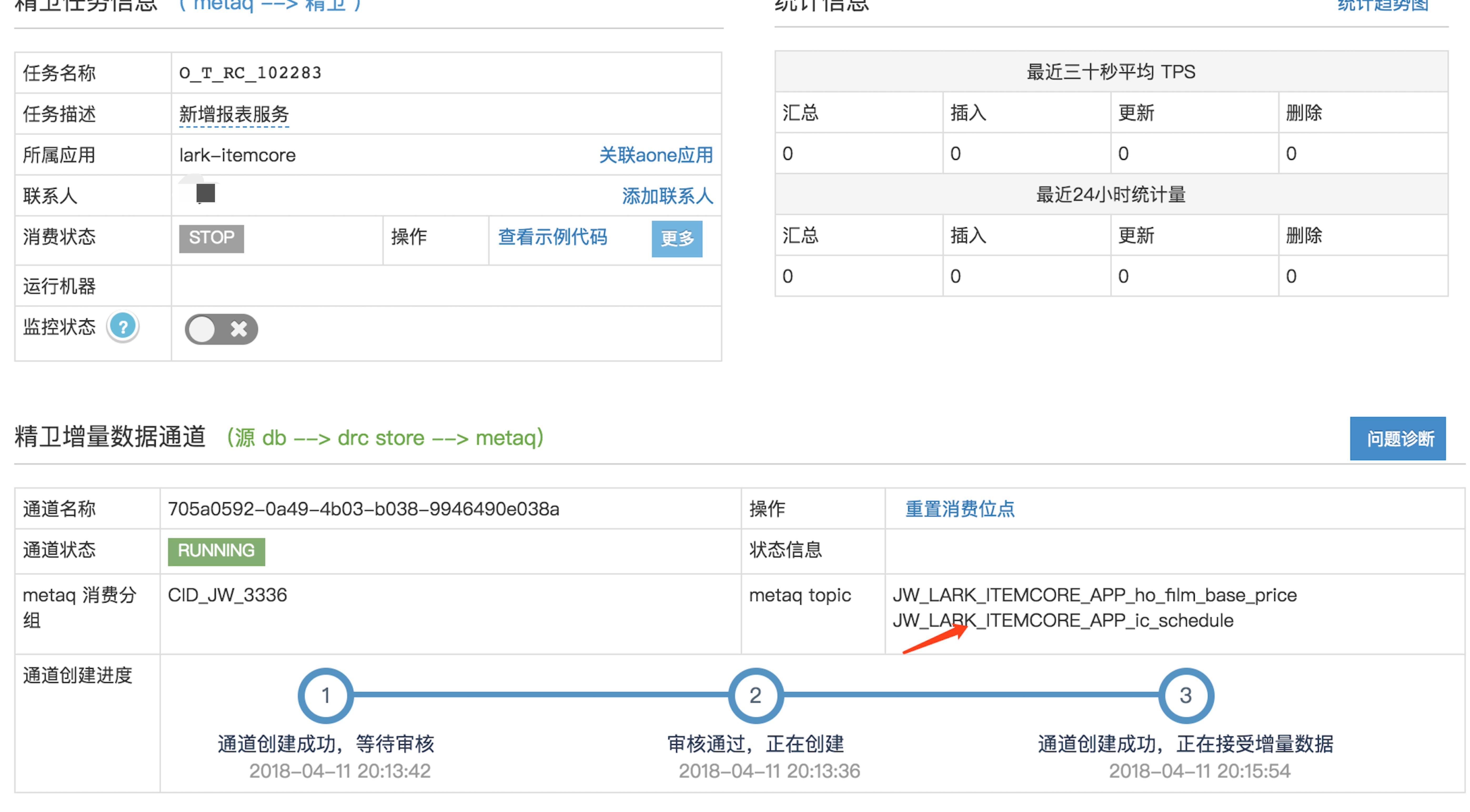
订阅metaq
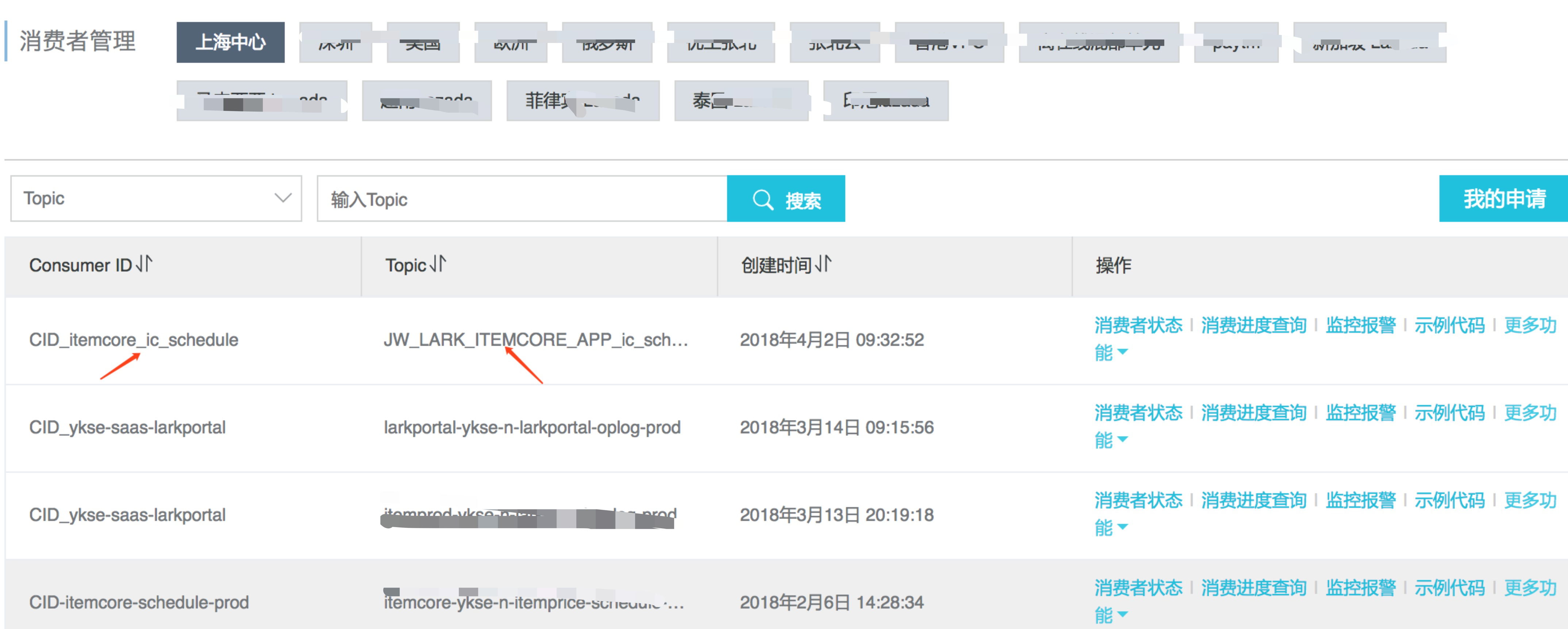
编写作业代码
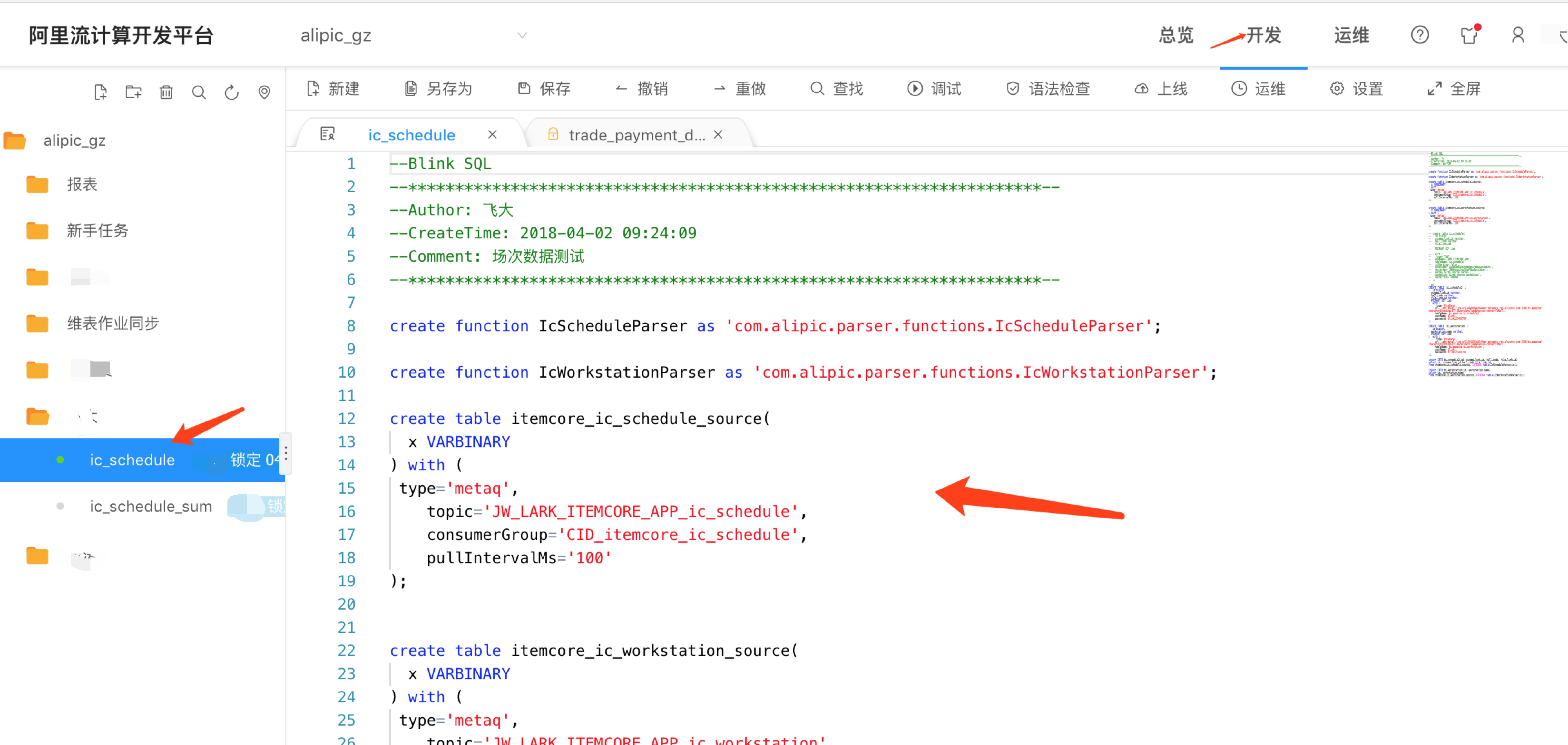
上线运维作业
精卫和metaq消息传输协议
为什么要去了解metaq和精卫之间传输的协议,是由于目前精卫官方提供的功能,没办法满足我们的业务需求,他提供了全量功能是针对db对db,没有办法db对metaq,并且我们还要兼容blink脚本共用,要满足这个功能就要查看精卫现在是怎么做的,通过查看文档和代码3.0.12之前的版本是dbsync协议而这个协议本身基于对象是DBMSRowChange,而之后的版本是EventMessage,现在容器代码也是返回DataMessage其结构跟EventMessage是一样,但是通过读取代码发现核心的还是DBMSRowChange通过这里面的数据组装到thirft协议中去,核心代码如下:
精卫发送metaq关键代码
com.alibaba.middleware.jingwei.core.applier.BatchMetaq3Applier
MessageBuilder messageBuilder = new PartitionMessageBuilder();
ThriftHeader header = null;
List<Message> messageFlush = new ArrayList<Message>(messages.size());
for (com.alibaba.middleware.jingwei.externalApi.message.Message message : messages) {
DbSyncMessage dbSyncMessage = (DbSyncMessage) message;
DBMSRowChange dbmsRowChange = (DBMSRowChange) dbSyncMessage.getDbMessage();
try {
header = buildThriftHeader(dbSyncMessage);
// 省去部分代码
for (Message thiftMessage : messageList) {
messageFlush.add(thiftMessage);
}
} catch (Throwable e) {
throw new JingWeiException(builder.toString(), e);
}
}
try {
for (Message thiftMessage : messageBuilder.flush(header)) {
messageFlush.add(thiftMessage);
}
} catch (TException e) {
String err = "Thrift serialization error: " + e.getMessage();
logger.error(err, e);
throw new JingWeiException(err, e);
}
msgSender.send(messageFlush);
代码主要是讲经过binlog的数据转换成Message对象,Message把响应的数据丢到Thrift协议中去,最核心就是把数据转成Thrift然后丢到metaq。
精卫解析metaq核心代码
com.alibaba.middleware.jingwei.client.util.MetaqToJingweiMsgParser
ThriftHeader thriftHeader;
try {
thriftHeader = ThriftHelper.loadThrift(msg.getBody(), eventSet);
} catch (Exception e) {
if (DynamicConfig.isSKIP_ALL_EXCEPTION(taskName)) {
logger.warn("SKIP_ALL_EXCEPTION is true, will skip the msg : " + msg, e);
continue;
} else {
throw new JingWeiException("ThriftHelper.loadThrift occur error" + ", msg : " + msg, e);
}
}
for (ThriftEvent event : eventSet) {
//省去部分代码
}
上面代码是精简出来的,解析Thrift处理过的metaq的数据,如果针对上面ThirftEvent感兴趣可以仔细看看他们内部怎么处理,通过测试这种协议反解析出来的速度很快,都是毫秒级别。
blink解析metaq模型
解析metaq发送过来的核心代码
public static<T> List<T> parseMetaQMessage(byte[] bytes, Class c) throws Exception {
List<T> sourceList = new ArrayList<>();
List<ThriftEvent> eventSet = new ArrayList<>();
ThriftHelper.loadThrift(bytes, eventSet);
//协议解包
for (ThriftEvent event : eventSet) {
// 省去部分代码
}
return sourceList;
}配置流程
可以参考上面整体配置流程。
精卫回溯方案
为什么不自己开发一套代码,直接把消息丢到metaq不就行了吗? 是因为精卫是按照任务纬度来划分,一个任务有多个表,如果自己再开发一套就需要把现有的任务跟表的关系关联在一起,这样造成很大的工作量,并且通过查看官方文档和vone咨询那边的开发,他们现在没有办法支持全量同步到metaq,只能通过精卫容器模式自己编写代码来实现。
全量发送metaq核心代码
Metaq3ApplierVO metaq3ApplierVO = new Metaq3ApplierVO();
metaq3ApplierVO.setCompressionType("NONE");
BatchMetaq3Applier outerClass = new BatchMetaq3Applier();
outerClass.setMetaq3ApplierVO(metaq3ApplierVO);
BatchMetaq3Applier.PartitionMessageBuilder messageBuilder = outerClass.new PartitionMessageBuilder();
ThriftHeader header = null;
String topic = entryMessageData.getKey();
List<Message> messageFlush = new ArrayList<Message>(messages.size());
for (DataMessage message : entryMessageData.getValue()) {
DBMSRowChange dbmsRowChange = null;
List<DBMSColumn> columns = new ArrayList<>();
int columnIndex = 0;
// 省去部分代码
}
基于上面分析的协议,而现在返回DataMessage对象是精卫封装后的,为了兼容一套Blink协议转换,需要把转换后的对象再组装成Thrift协议,在组装过程有很多依赖,有些依赖没有考虑全面报了很多错误,然后去适配,还有个细节由于每个任务对应不同的表,而不同的表是有不同的topic,所以在代码上把接受到数据做了一层分组,这样按照精卫生成的topic,就能一套代码运行N个服务。
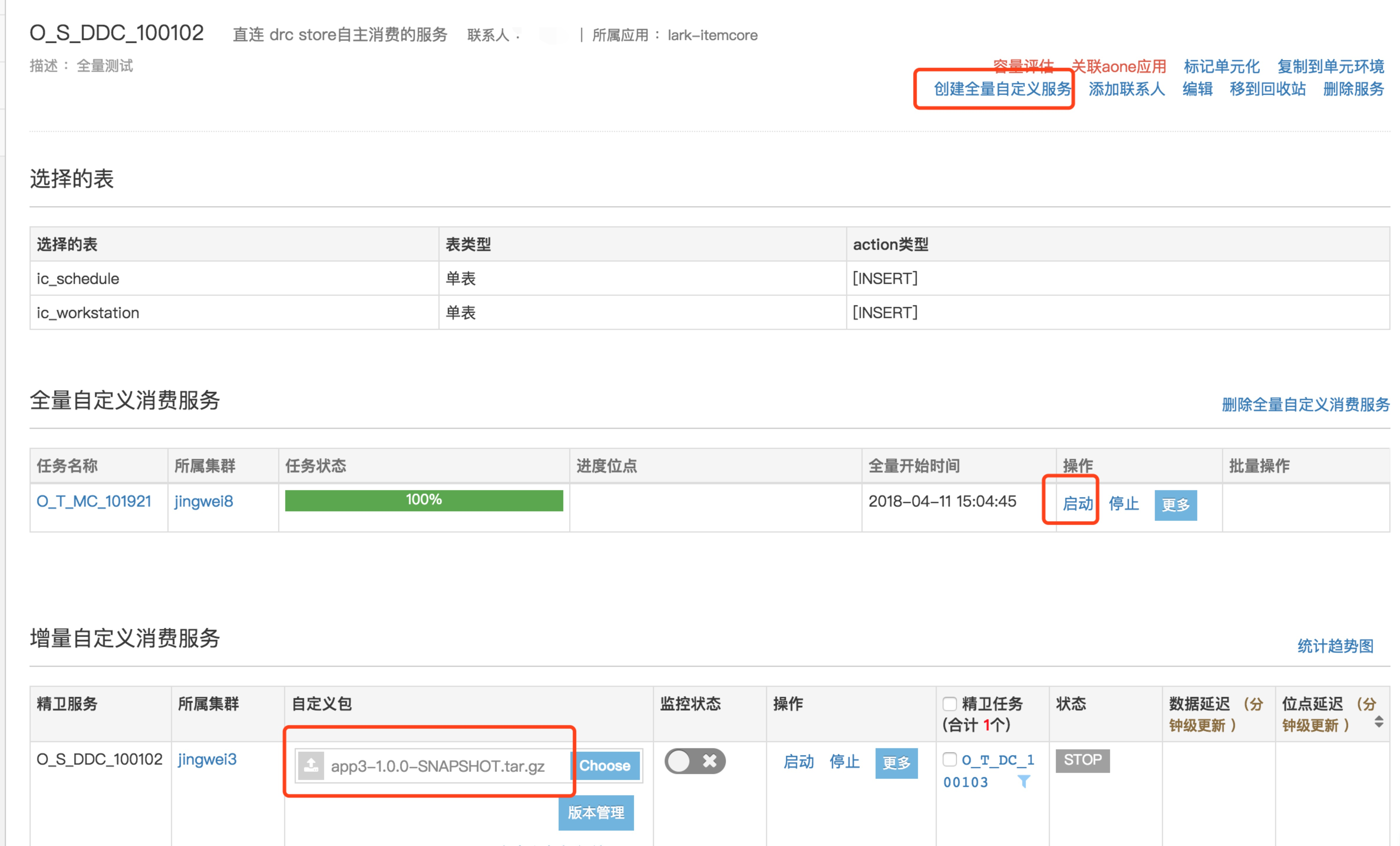
回朔配置流程
选择精卫自主消费
选择据链路类型

上传代码到容器
petadata技术
-
petadata百万查询都是毫秒级别,不过不能分页过多,因为页数过多多从多个分区拿数据,然后再组装很耗时。
总结
-
精卫发送metaq的数据带毫秒的,格式如:2018-03-10 12:12:12.0,而回溯全量方案获取的dataMessage是直接从数据库拿的值,没有带毫秒。格式如:2018-03-10 12:12:12。
-
petadata不支持group by后再order by。
-
幂等顺序问题通过LAST_VALUE和group by来解决。
-
blink.state.ttl.ms(默认一天) 和 state.backend.rocksdb.ttl.ms(默认1一天半), 一般是按照这个规则设置两个参数blink.state.ttl.ms <= state.backend.rocksdb.ttl.ms,由于我们报表业务特殊性,是凌晨6点到第二天凌晨6点为一个周日,所以这两个参数最少要设置为2天,才能保证准确性。
-
有join操作,先过滤、去重,再join。
-
如果in/outcpu过高,则从core、memory、parallelism,cu几方面扩大调优。
-
传输数据过多,可以增大blink.miniBatch.size,以减少在计算过程中对IO的操作,但只能对group by生效。
-
精卫bug:当带上自定义查询条件,如果id是主键,且是varchar类型,精卫拼装sql就会报错,这个已经反馈给精卫开发,正常id都是long,由于我们在弹外的业务是字符串,所以复现这个bug,后续的表一定要按照集团规范,不然使用其他中间件估计也会有问题。
作者:向飞(飞大)
简介:技术专家,资深java程序员,喜欢折腾各种技术。

如果您有实时报表/实时数据大屏/实时金融风控/实时电商推荐等相关实时化数据处理需求,可以加入如下钉钉交流群!









