译者按:本文作者是亚马逊CTO Werner,今日在其个人博客上发表的关于行业产品的最新见解。如果你对数据库了解不多,则本文能够帮助建立一个宏观的理解,同时能参考亚马逊的产品来指导在企业内部进行数据库技术选型。
【译文】
我经常被问及的一个问题,为什么我们(亚马逊)提供这么多数据库产品?对我来说答案很简单:开发人员希望他们的应用程序能够很好地架构和有效扩展。为此,他们需要能够在同一个应用程序中使用多个数据库和数据模型。
一套数据库很少能满足多个不同使用场景的需求。一套数据库能满足所有场景的时代已经过去,开发人员如今正在构建高度分布式的应用程序,需要使用大量专用数据库。开发人员正在做他们最擅长的事情:将复杂的应用程序分解成更小的部分,然后选择最佳工具来解决每个问题。使用场景不同,同一个任务的最合适的工具也不同。
几十年来,因为唯一的数据库选择就是关系数据库,无论应用程序中数据的类型或功能如何,数据都会被建模为关系数据库,而不是靠使用用例来驱动对数据库对需求。数据库曾经主导来应用使用数据对数据模型。关系数据库是否为规范化模式专门设计的吗?要在数据库中强制引用完整性?当然是,但问题但关键是不是所有应用程序数据模型或用例都与关系模型匹配。
正如我之前谈到的,我们构建Amazon DynamoDB的原因之一是亚马逊当时正在推动当前领先的商业数据库的极限,我们无法维持亚马逊业务增长所需要的可用性、可扩展性和性能需求。我们发现大约70%的操作是键值查找,即只使用了主键并且返回了一行。由于不需要引用完整性和事务,我们意识到这些访问模式可以通过不同类型的数据库更好地满足。此外,随着Amazon.com的增长和扩展,无限的横向扩展需要成为一个关键的设计点 ,但简单扩展并不是一个有效的选择。这最终导致了DynamoDB的诞生,一种非关系型数据库服务,它可以扩展到超出关系数据库的限制。
这并不意味着关系数据库在当前的开发实践中不再能提供实用性,可用性,可扩展或提供高性能。事实上,我们的客户已经证明了这一点,因为Amazon Aurora仍然是AWS历史上发展最快的服务。我们在Amazon.com上遇到的是,用户以超出预期的方式在使用数据库。这正是本博客后续的核心 - 数据库是为了一个目的而构建的,将用例与数据库相匹配将有助于您更快地开发高性能,可扩展且功能更强的应用程序。
专用数据库
世界仍在变化,非关系数据库的种类继续在增加。我们越来越多地看到,客户希望基于不同数据模型构建在全网扩展的应用程序。为了满足这些需求,开发人员现在可以选择关系,键值,文档,图形,内存和搜索数据库。每一类数据库都解决了一个特定问题或一组问题。
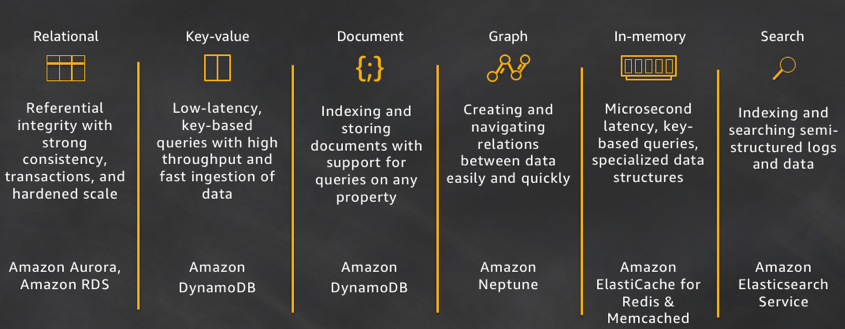
让我们仔细看看上面每个数据库的目的:
关系:关系数据库是自描述的,因为它使开发人员能够定义数据库的模式以及数据库中行和表之间的关系和约束。开发人员依赖关系数据库(而不是应用程序代码)的功能来保证数据模式和数据库中数据的引用完整性。关系数据库的典型用例包括Web和移动应用程序,企业应用程序和在线游戏。Airbnb是客户使用Amazon Aurora构建高性能和可扩展应用程序的一个很好的例子。Aurora为Airbnb提供了一个完全托管,可扩展且功能齐全的服务,来运行他们的MySQL工作负载。
键值:键值数据库具有高度可分区性,允许在其他类型的数据库无法实现的级别进行水平扩展。游戏、广告技术和物联网等用例特别适合于键值数据模型,其中访问模式要求针对已知键值的低延迟查询/写入。DynamoDB的目的是为任何规模的工作负载提供持续的毫秒级延迟服务。这种一致的性能是Snapchat Stories功能(包括Snapchat最大的存储写入工作负载)迁移到DynamoDB的重要原因。
文档:文档数据库的使用对于开发者来说非常直观,因为应用程序层中的数据通常表示为JSON格式文档。开发者可以使用和应用程序代码中的相同文档模型格式来保留数据。Tinder是使用DynamoDB的灵活模式模型来实现开发人员效率的一个客户示例。
图:图数据库的目的是使构建和运行使用高度连接的数据集应用程序变得容易。图数据库的典型用例包括社交网络,推荐引擎,欺诈检测和知识图。Amazon Neptune是一个完全托管的图形数据库服务。Neptune支持Property Graph模型和Resource Description Framework(RDF)框架,有两个图形API可供选择:TinkerPop和RDF / SPARQL。目前的Neptune用户主要是构建知识图表,构建游戏内置的推荐和欺诈检测。例如,汤森路透通过使用Neptune帮助他们的客户浏览复杂的全球税收政策和法规网络。
内存:金融服务,电子商务,Web和移动应用程序都有排行榜,会话存储和实时分析等场景,它们需要微秒响应时间,并且随时可能出现大量流量峰值。我们构建了Amazon ElastiCache,提供Memcached和Redis,满足低延迟,高吞吐量的工作负载的需求,例如麦当劳,这些工作负载无法由基于磁盘的数据存储负担。Amazon DynamoDB Accelerator(DAX)是专用数据存储的另一个示例。构建DAX是为了使DynamoDB读取速度提高一个数量级。
搜索:许多应用程序借助输出日志,帮助开发人员解决问题。Amazon Elasticsearch Service(Amazon ES)的定位是,通过对机器产生对数据建立索引,聚合和搜索半结构化日志和指标,提供近乎实时的可视化和分析。Amazon ES也是一款功能强大的高性能搜索引擎,可用于全文搜索。Expedia正在使用150多个Amazon ES域,30 TB数据和300亿个文档,处理各种关键任务,包括运营监控和故障排除,分布式应用程序堆栈跟踪和定价优化。
使用专用数据库构建应用程序
开发人员正在构建高度分布式和松耦合的应用程序,AWS使开发人员能够使用多个AWS服务构建这些云原生应用程序。以Expedia为例。虽然对于客户来说,Expedia网站看起来像一个应用程序,但在幕后,Expedia.com由许多组件组成,每个组件都具有特定的功能。通过将诸如Expedia.com之类的应用程序分解为具有特定作业的多个组件(例如微服务,容器和AWS Lambda函数),开发人员可以通过提高规模和性能,减少运维,提高部署灵活性以及组件独立发展,来提高工作效率。构建应用程序时,开发人员可以将每个应用场景,选择最适合需要的数据库。
为了实现这一点,请查看一些使用多种不同类型的数据库来构建应用程序的客户:
- Airbnb使用DynamoDB存储用户的搜索历史记录,以便快速查找,以及提供个性化搜索。Airbnb还使用ElastiCache在内存中存储会话状态,以便更快地进行站点服务,并且他们使用Amazon RDS上的MySQL 作为其主要事务数据库。
- Capital One使用Amazon RDS存储状态管理的交易数据,使用Amazon Redshift存储需要聚合分析的Web日志,使用DynamoDB存储用户数据,以便客户可以使用Capital One应用程序快速访问其信息。
- Expedia使用Aurora,Amazon Redshift和ElastiCache构建了一个实时数据仓库,用于住宿市场定价,保证数据可用性以进行内部市场分析。数据仓库使用ElastiCache for Redis执行多数据流联合,并使用24小时回顾窗口进行自联接。数据仓库还将处理后的数据直接保存到Aurora MySQL和Amazon Redshift中,以支持运营和分析查询。
- Zynga将Zynga扑克数据库从MySQL服务器场迁移到DynamoDB,并获得了巨大的性能提升。过去需要30秒的查询,现在只需要一秒钟。Zynga还使用ElastiCache(Memcached和Redis)代替自己运维对内存缓存服务。Aurora的自动化和Serverless可扩展性使其成为Zynga使用关系数据库时的首选。
- 强生公司使用Amazon RDS,DynamoDB和Amazon Redshift来最大限度地减少收集和配置数据所花费的时间和精力,更快速的获得洞察。AWS数据库服务正在帮助强生公司改善医生的工作流程,优化供应链和发现新药。
就像开发人员不再编写单一应用程序一样,开发人员也不再需要使用单一数据库来处理应用程序中的所有场景 - 他们可以使用的是多种数据库。虽然关系数据库仍然存在且生命力旺盛,并且仍然适用于许多用例,但是用于键值,文档,图形,内存和搜索用例的专用数据库可以帮助你优化功能、性能和扩展性 - 更重要的是 - 你的客户体验。
原文:https://www.allthingsdistributed.com/2018/06/purpose-built-databases-in-aws.html