介绍
大家好,我是蚂蚁金服的鲁直,是蚂蚁金服微服务团队的 TL,同时也负责 SOFA 对外开源的相关事宜。
非常感谢中生代社区王友强,蚂蚁金服右军的组织,让我今天能够有机会给大家做一个分享。我今天给大家带来的分享是「SOFA 分布式架构的演进」。
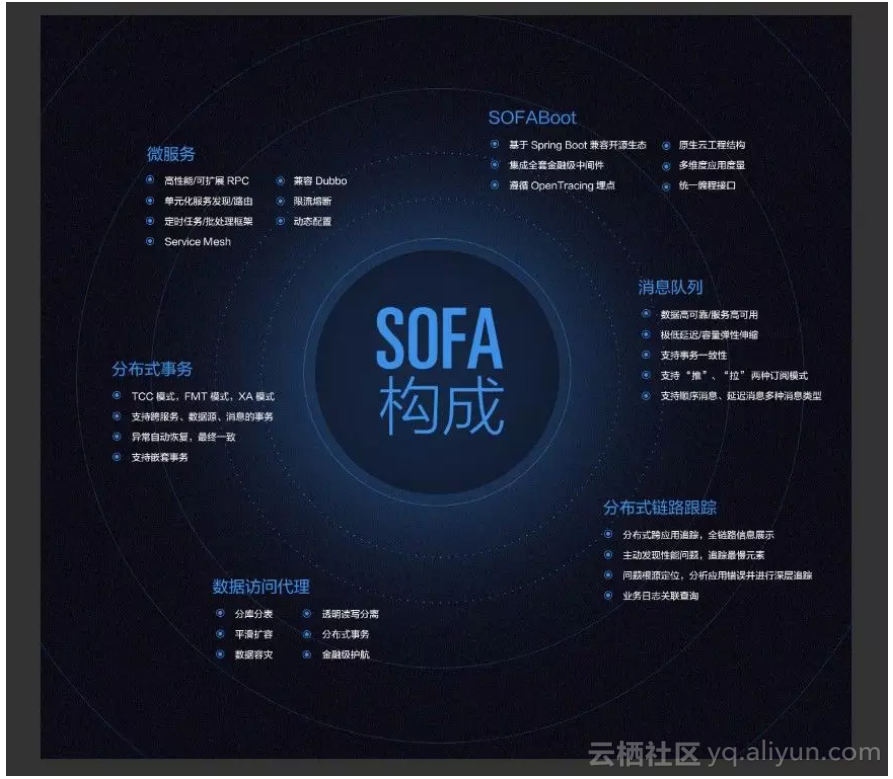
在开始之前,可能很多人不太清楚 SOFA 是什么东西,这里先做下简单地介绍。SOFA 是蚂蚁金服自研的一套金融级分布式中间件,从写下第一行代码到今天已经有将近 10 年的时间,包含了应用容器,RPC,消息,数据中间件,分布式事务,限流,熔断,分布式链路追中等等框架,算是一个分布式中间件全家桶。随着蚂蚁金服这 10 年业务的飞速发展,SOFA 也在这个过程中得到了大量地锤炼,快速地成长,支撑了每年双十一,双十二,新春红包等大型活动。大家可以从下面这种图中看到 SOFA 涵盖的范围。在今年 4 月份,SOFA 开始了开源之路,目前已经有部分组件开源在了 Github 上面,欢迎大家围观 star:https://github.com/alipay 。
早期模块化
要讲 SOFA 的发展过程,要从支付宝的早期开始,在支付宝的早期,支付宝的全站的架构非常简单,就是一个简单的分层架构,类似于下面这张图:
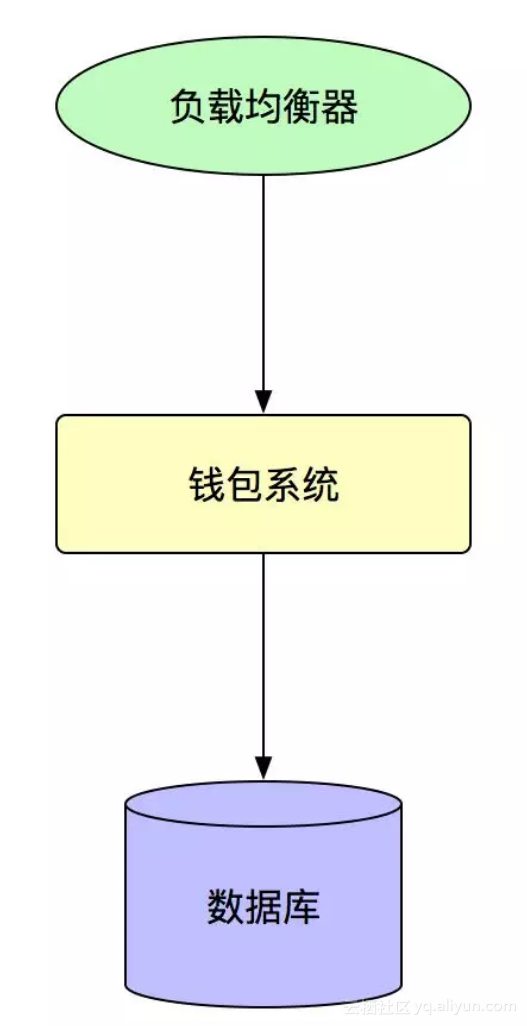
最前面是一个负载均衡器,负载均衡器的流量直接打到当时支付宝唯一的系统钱包系统里面来,然后钱包系统后面连着一个数据库。这种系统的分层设计在刚开始系统流量不高,团队不大的时候,没有太大的问题,但是当团队规模扩大,团队内部以及团队之间的协作成本就会越来越高,所以在 SOFA 最开始的版本中,我们引入了模块化的方案,来为系统解决系统内部的协作的问题,也为服务化做准备。
SOFA 的模块化不同于一般的模块化的方案,在一个一般的模块化的方案里面,只是在代码的组织结构上进行了模块化的拆分,负责同一个功能的代码内聚到到一个 Maven 模块下面,最终打包成一个 JAR 包。这种模块化的方案有一个缺陷,就是没有考虑运行时的问题,在这种模块化的方案里面,一般上都只有一个 Spring 的上下文,意味着一个模块里面的 Bean 可以任意地访问另一个模块里面的 Bean 而没有任何控制,长期来看,这种情况会导致模块和模块之间在运行时的高度耦合。
为了解决这个问题,SOFA 的模块化方案给每一个模块都加上了一个独立的 Spring 上下文,默认的情况下,一个模块不能直接引用另一个模块的 Bean。当需要引用另一个模块的 Bean 的时候,需要在代码中通过类似于 RPC 的服务发布和引用来解决,比如当模块 A 需要调用模块 B 的 SampleService 这个 Bean 的时候,模块 B 可以通过以下的代码来提供服务:
<sofa:service ref="sampleService"
interface="com.alipay.sofa.sample.SampleService"/>
另一个模块 B 就可以通过以下的代码来引用服务:
<sofa:reference id="sampleService"
interface="com.alipay.sofa.sample.SampleService"/>
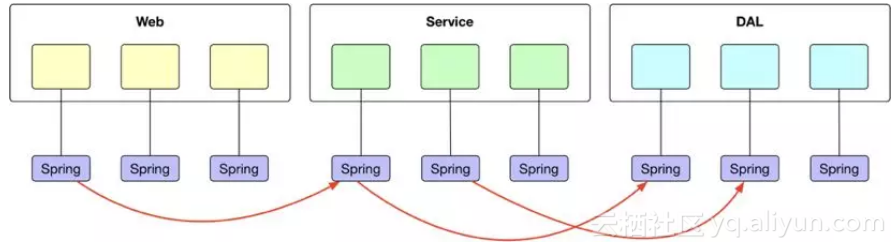
通过 SOFA 的模块化方案改造之后,一个系统的模块可以如下图所示,图中的红线就是 JVM 的服务发布和引用:
从单应用到服务化
通过 SOFA 引入模块化的方案之后,在一定程度上帮助业务解决了研发效率的问题。但是随着业务的不断地发展,团队规模的不断扩大,单纯靠一个系统内的模块化已经难以满足业务的诉求,所以,在这个时期,我们开始了服务化的改造,这个时候,SOFA 之前的模块化的方案的另一个优势就能够体现出来了,当我们将一个系统的多个模块通过服务化拆成多个系统的时候,只需要在原来的 <sofa:service/> 以及 <sofa:reference/> 里面加上一个协议,就可以将本地的模块间的调用变成 RPC 的调用:
<sofa:service ref="sampleService"
interface="com.alipay.sofa.sample.SampleService">
<sofa:binding.bolt/>
<sofa:service/>
<sofa:reference id="sampleService"
interface="com.alipay.sofa.sample.SampleService">
<sofa:binding.bolt/>
<sofa:reference/>
在服务化的早期,我们引入了 F5 作为服务间调用的负载均衡设备,也通过 F5 来做服务发现,如下面的架构图所示:
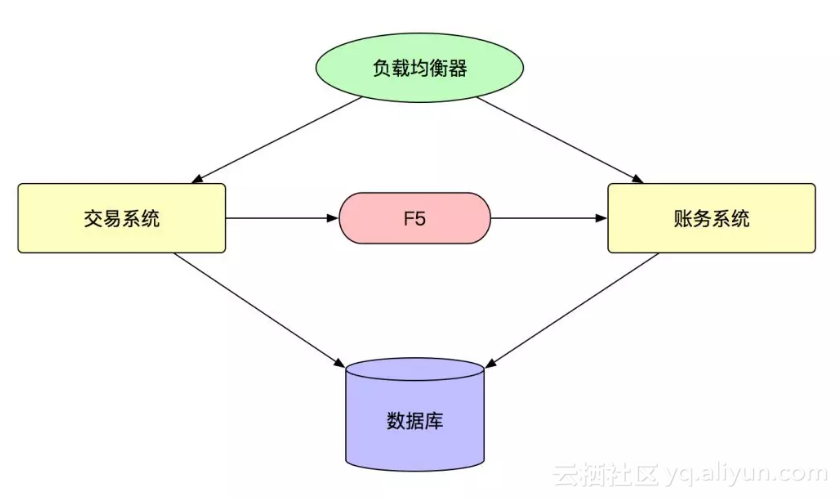
但是,运行了一段时候之后,我们发现 F5 成了一个瓶颈,所有的流量都要 F5,对 F5 本身会造成比较大的压力,另外,这种负载均衡设备在处理长连接的时候会有一些问题,服务端扩容操作可能会导致最终流量不均衡,所以,在后面,我们引入了自研的服务注册中心,变成了下面的这种结构:
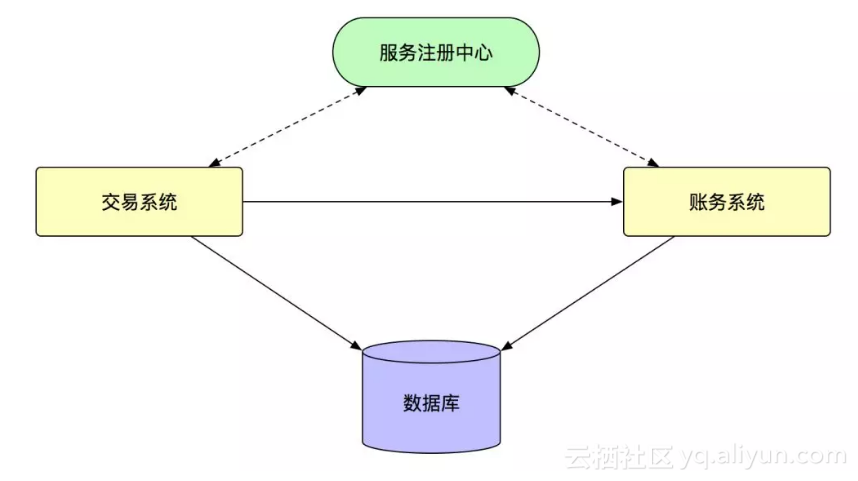
这里面之所以不选择 ZK 的原因是因为考虑到 ZK 是一个 CP 的系统,在发生网络故障的时候,会发生严重地不可用。所以 SOFA 自己的服务注册中心 SOFARegistry 设计成了一个 AP 的系统,最大程度的保证可用性,放弃一定程度的一致性。
目前 SOFARegistry 正在进行开源的准备工作,在准备完成之后,会公布出来。
到了这个阶段,支付宝的系统已经完成了基本的服务拆分。
SOFA数据拆分
在通过服务化解决了应用的水平扩容的问题之后,后面,我们遇到了数据库的容量的问题,原来,支付宝的所有的数据都在一个大的数据库里面,首先想到的就是进行垂直的拆分,将不同的业务的数据放到不同的数据库里面去。如下图所示:
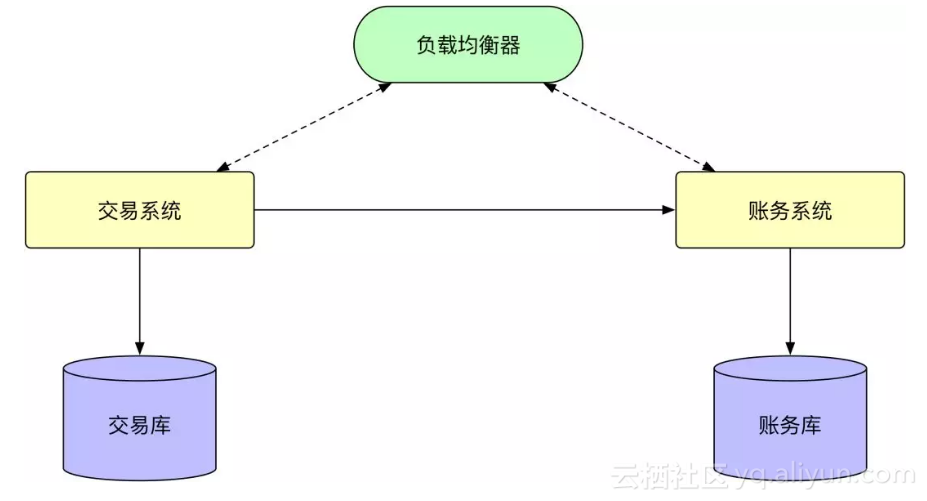
但是随着交易量的上升,类似交易库这种,会首先面临大量的交易的数据,单库都放不下这么多的事情,这个时候,就需要考虑做水平拆分, 比如向交易库这种,我们就可以根据用户的 ID 进行拆分,变成类似于下面的这种结构:
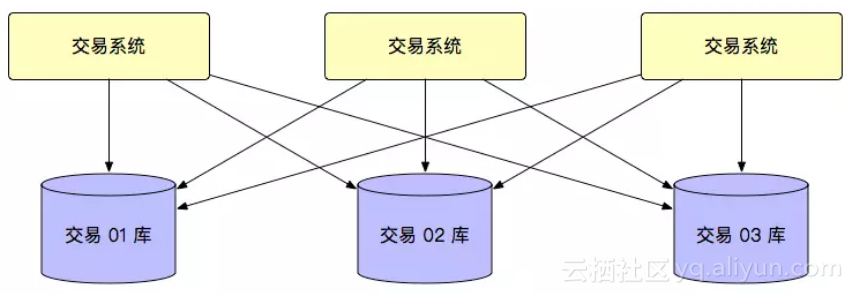
数据库的分库分表我相信很多人都已经听说过,这里也分享一下如何确定需要有多少的库, 需要有多少的表。首先是最小的库的数量,可以通过业务峰值 TPS 除以单库容量上限 TPS 来计算。然后是最小的表的数量,可以通过单位时间业务量乘以存储时长再除以单表的容量上限来进行计算。
SOFA分布式事务
在经过数据库的拆分之后,在金融场景下很自然地,就面临了一个新的问题,就是分布式事务的问题,原来所有的数据都在一个库里面,那么只需要数据库支持事务就可以了。在数据库经过了拆分之后,就需要通过引入分布式事务来协调多个数据库之间的事务问题了。
在 SOFA 里面,通过自研了一个 TCC 的框架来解决了分布式事务的问题,也就是现在的 SOFA DT X ,在 TCC 模型下,会有一个事务的发起方,这个一般上是一个业务系统,它会现在业务系统中去启动一个本地事务,然后调用所有的事务参与方的 Try 接口,如果 Try 通过之后,再调用所有的事务的参与方的 Commit 接口进行事务提交。如果 Try 失败,则调用所有的事务参与方的 Cancel 接口进行事务回滚。在 TCC 中,一旦一阶段 Try 通过之后,二阶段就 Commit 就必须成功,但是现实情况中,总会因为各种各样的问题,会有 Commit 失败的情况发生。所以,在 SOFA 的 DTX 中,还有一个单独的服务,专门用于重试二阶段,让这些事务最终能够成功。
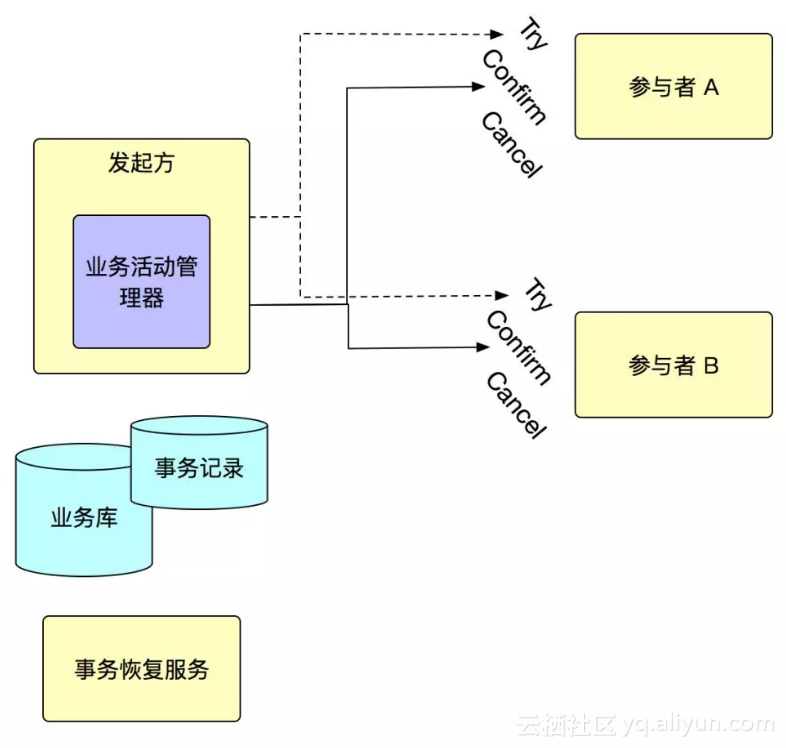
当然,在 SOFA 里面,除了对分布式事务做同步的服务的事务支持之外,针对异步的消息,也提供了事务消息的支持,SOFA 里面的事务消息的支持可以看如下这张图:
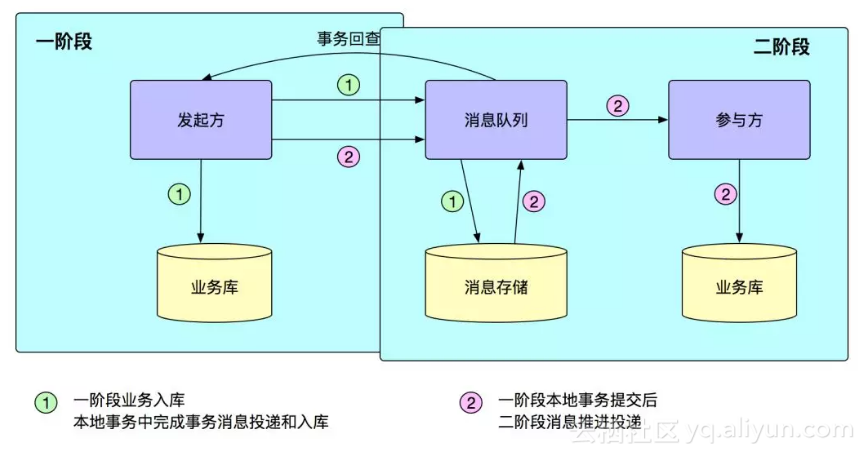
在事务消息里面,发起方会在一个本地事务中去发送一个消息,SOFA 的消息中心接收到这个消息之后,会落到消息中心的存储里面,但是这个时候,消息中心并不会向订阅方投递消息;等到发起方的本地事务结束,会自动给消息中心一个通知,告诉消息中心本地事务已经提交或者回滚,如果消息中心从发起方得到的通知是事务已经提交,就会将消息发送给消息的订阅方,如果消息中心从发起方得到的通知是事务已经回滚,那么消息中心就会从存储中将消息删除掉。当然,发起方给消息中心的通知在中间也可能会因为各种各样的问题到丢失,所以,一般上事务的发起方还需要实现一个消息回查的接口,当消息中心在一段时间内没有收到事务的发起方的通知的时候,消息中心会主动回查发起方,主动咨询发起方对应的事务的状态,根据主动拿到的状态来决定消息是要发送还是删除。
在蚂蚁内部,分布式事务和事务型消息作为 SOFA 在事务上的解决方案都在被广泛地使用,其中分布式事务一般上用在强同步的场景,比如转账的场景,而事务型的消息一般上被用在异步的场景,比如消息记录的生成等等。
合并部署
在经过了几年的服务化之后,因为蚂蚁的业务的特点,出现了一些比较长的业务链路,比如从淘宝过来的支付链路,可能中间涉及到十几个系统,这些系统之间在一次请求中的相互调用非常频繁,导致中间 RPC 消耗地时间比较高,并且像支付链路这样,其实上下游关系非常密切,在运维操作上,因为大促而导致的容量评估,扩容缩容也都必须一起操作,所以,在 SOFA 中,我们引入了合并部署的概念,来解决这种长的业务链路中的 RPC 调用耗时的问题,也期望通过合并部署能够让关键系统更好地去做容量评估。合并部署整体的示意图如下图所示:
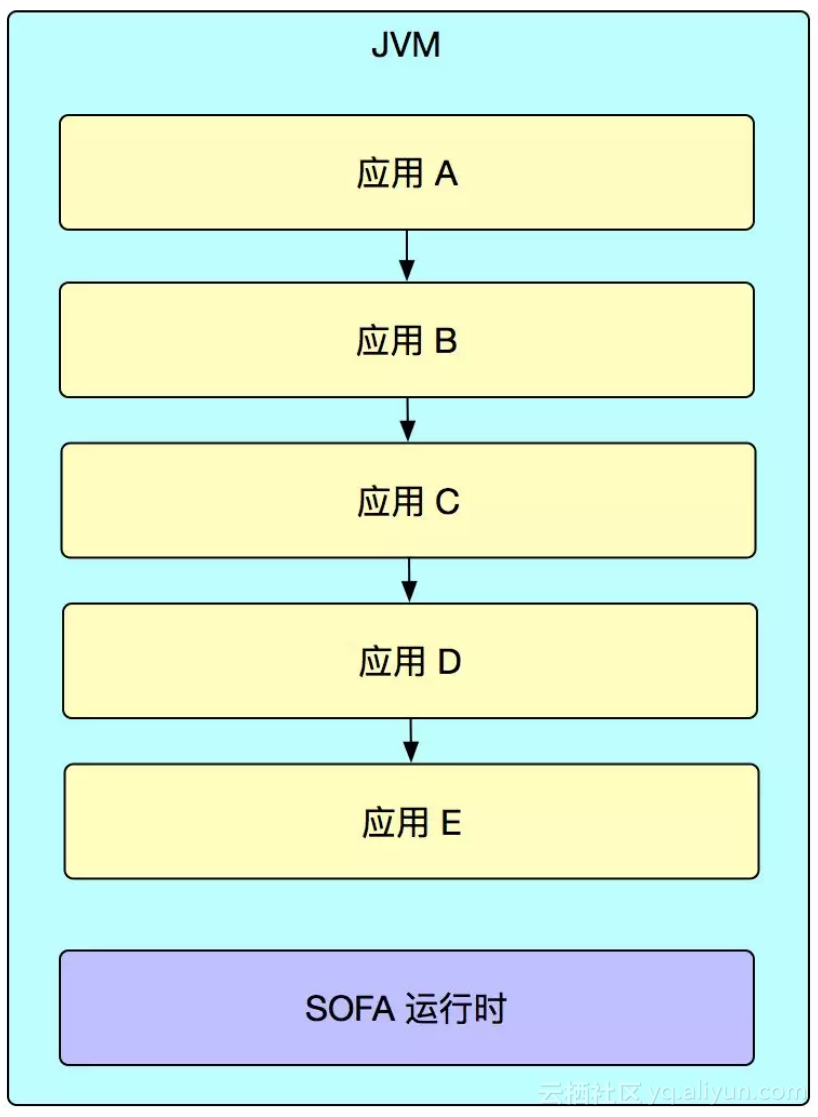
所谓的合并部署,从上图中可以看出,就是将相关联的一些系统部署到一个 SOFA 运行时下面,每个系统之间通过单独的 ClassLoader 加载,防止出现类冲突,和服务化的过程刚好相反,在合并部署里面,SOFA 会自动地将这些系统之间的 RPC 调用转换成 JVM 调用,从而节省了类的成本。
在合并部署里面,有门面系统和非门面系统的概念,只有门面系统会对外暴露服务,外部的系统只能看到门面系统发布的服务,非门面的系统全部为门面系统服务。
虽然这些系统部署最终是部署在一起的,但是开发还是有独立的团队进行开发,所以在研发上,并没有太大的差比,合并部署更多的是一种运维以及部署上的优化。
单元化
刚才在数据拆分的那张图里面知道,一个应用对应的数据库进行了拆分之后,对于一个应用的实例来说,它必须连到分库后的所有的数据库,才能够确保任何请求进入的时候都可以找到数据,这种方式在应用的实例数量增加之后,就会出现数据库连接的瓶颈,如下图所示:
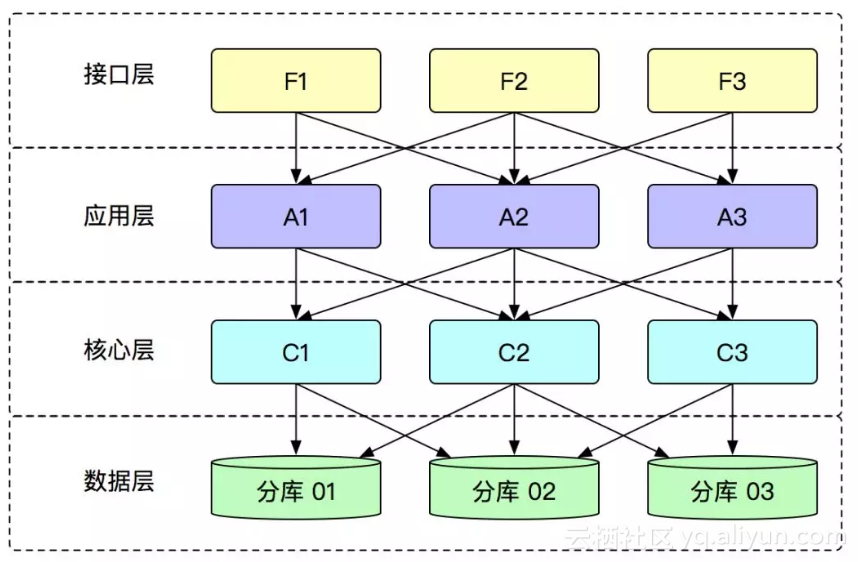
为了解决数据库连接的瓶颈的问题,我们开始引入了单元化的概念,在蚂蚁叫 LDC(逻辑数据中心),单元化的概念如下图所示:
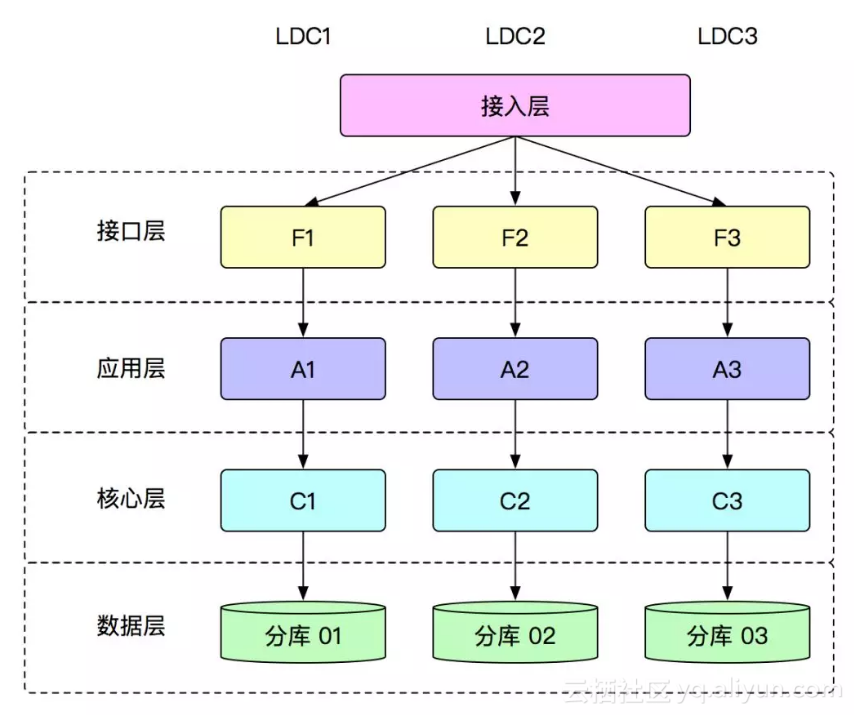
在单元化中,一个逻辑数据中心只处理一个数据分片的请求,如果说数据是按照用户来进行分片的话,涉及到一个用户的请求只会在一个逻辑数据中心里面来处理,通过这样的设计,一个应用连的数据库只要和对应的逻辑数据中心的数据分片一致就可以,这样,就可以大量地减少数据库上的连接数的压力。而且利用这种逻辑数据中心的概念,理论上,如果数据库的连接数不足,只需要增加逻辑数据中心就可以。
ServiceMesh
前面讲到的 SOFA 从演进过程中发展出来的能力,都是在蚂蚁线上运行地非常成熟的一些东西,这几年,虽然 Kubernetes 的普及,ServiceMesh 也变得越来越火,所以,SOFA 现在也在往 ServiceMesh 这个方向上演进,在蚂蚁内部,有将近 2000 多个 SOFA 的系统,每次版本的升级都非常痛苦;另外,随着人工智能等领域的兴起,Python 等语言越来越火,原来 SOFA 里面所有的内容都是通过 Java 来做的,已经不能够满足当前业务的系统,我们需要也寻找一个方案去解决多语言的问题。刚好,通过 ServiceMesh,我们可以将 SOFA 里面原有的一些能力下沉,比如服务发现,限流,熔断等等,这样,这些能力的升级一方面可以摆脱业务系统去自主升级,另一方面,也可以让 SOFA 的体系更加方便地为其他的语言所服务。
目前 SOFAMesh 的 0.1.0 的版本也已经在 Github 上面开源,包括 Istio 的 Control Plane 的部分:
https://github.com/alipay/sofa-mesh ,
以及我们自研的 Data Plane 的部分:
https://github.com/alipay/sofa-mosn
总结
SOFA 的发展离不开蚂蚁金服自身业务的发展,正是由于蚂蚁金服自身业务的飞速发展,需要 SOFA 不断地去解决各种各样的问题,才有了 SOFA 的今天,当然,我们也深感蚂蚁金服本身的业务的广度和整个业界比起来真的是九牛一毛,所以在今年 4 月份,我们开始了 SOFA 的开源的进程,逐步将 SOFA 里面的各个组件开放出来,希望 SOFA 在整个社区中能够得到更大的锻炼,得到更多的反馈,帮助 SOFA 进一步发展。对 SOFA 开源感兴趣的,可以到我们的 Github 的地址上给一个 star:https://github.com/alipay
