人类非常聪明,我们可以通过观察进行学习。无论是日常的洗手,还是惊人的杂技表演,对人类来说都是可以学习的。
然而,对于机器来说,通过观察来学习是非常困难的。YouTube上面每分钟都会有300小时的视频上传,即使拥有如此庞大的数据库,也很难用它来训练机器。
因为,大多数模仿学习方法的表示必须非常简单以及简洁,例如动作捕捉(mocap)记录的表示。但获取动作数据可能非常麻烦,通常需要大量的仪器。动作捕捉系统也往往局限于室内环境,这显然严重限制了机器的学习。
如果我们的机器人可以通过观看视频片段来学习技能,那将会非常棒~
例如~

为了达到这种效果,伯克利大学提出了一个从视频(SFV)中学习技能的框架。利用计算机视觉和强化学习方面的最先进技术,系统使模拟角色能够从视频剪辑中学习各种各样的技能。给定一段动作视频,例如车轮或后空翻,特定对象能够学习从而再现该动作,而无需任何手动姿势注释。

通过观看视频,从而学习运动技能的问题一直在计算机领域备受关注。 以前的技术通常依赖于手工制作的控制结构,这些控制结构对产生的行为施加了强大的限制。因此,这些方法往往受限于可以学习的技能类型,并且,机器人模仿出来的动作看起来相当不自然。
观看视频感受下最新成果

最近,深度学习技术在简单的机器学习任务中表现的非常棒。但是这些任务通常只是简单的域转换,并而连续控制的结果主要是在相对简单的动态任务上进行的。
框架
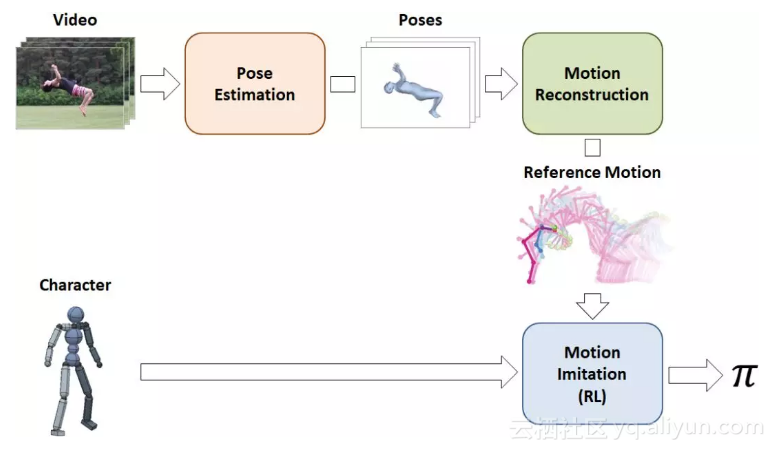
该学习框架由三个部分组成:姿态估计、运动重构和运动仿真。输入的视频首先由姿态估计阶段进行处理,预测每个帧中参与者的姿态。接下来,运动重建阶段将姿态预测合并为参考运动,并修复可能由姿态预测引入的伪影。最后,参考运动被传递到运动模拟阶段,在该阶段,一个模型被训练成模拟运动。
姿势估计
给定一个剪辑过的视频,使用一个基于视觉的姿态估计器来预测视频中的角色在每一帧中的姿态。姿态估计器是建立在人工网格恢复的基础上的,该方法使用弱监督的对抗性方法训练姿态估计器,从单目图像中预测姿态。虽然姿态标注是用来训练姿态估计器的,但是一旦经过训练,姿态估计器就可以应用到没有任何注解的新图像上。
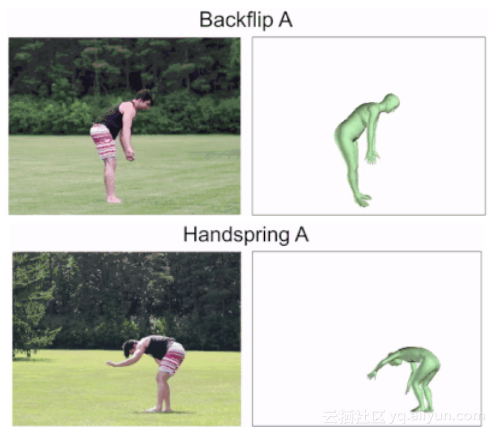
基于视觉的姿态估计器用于预测每个视频帧中参与者的姿态。
运动重构
由于姿态估计器对每个视频帧的预测是相互独立的,因此帧间的预测可能不一致,从而导致抖动伪影。此外,尽管基于视觉的姿态估计器在最近几年有了很大的改进,但它们仍然偶尔会犯一些相当大的错误,这可能导致不时出现一些奇怪的姿势。因此,运动重建阶段的作用是减少这些错误,从而产生一个更物理的参考运动,将更容易的模拟字符。
为此,优化参考运动,从而满足公式
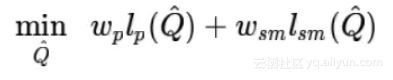
相邻帧中的姿势相似以便产生更平滑的运动。另外,wp和wsm是不同损失的权重。
该方法可以大大提高参考运动的质量,并能修复原始姿态预测产生的大量伪影。
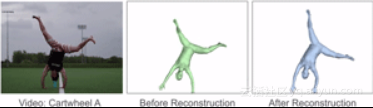
运动重建前后参考运动的比较。运动重建减轻了许多伪影,并产生了更平滑的参考运动。
运动模拟
一旦有了理想的参考运动,可以继续训练模拟角色从而模仿运动。然后引入奖励函数,其目标是鼓励模拟的姿态与重构的参考运动在每个帧的姿态的差异降到最小。
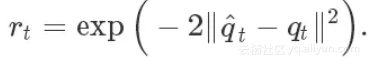
这种看似简单的方法的表现确是很棒,我们的角色能够学习到各种具有挑战性的杂技技能,其中每一项技能都可以从一个视频演示中学到的。

总之,我们的使用的方法能够从YouTube收集的各种视频剪辑中学习到20多种不同的技能。

我们的框架可以从视频演示中学习大量技能。
尽管我们角色的形态往往与视频中的人物有很大的不同,但是确实能够模仿很多动作。作为一个更极端的形态差异的例子,我们也可以训练一个阿特拉斯机器人来模仿视频中人物的动作
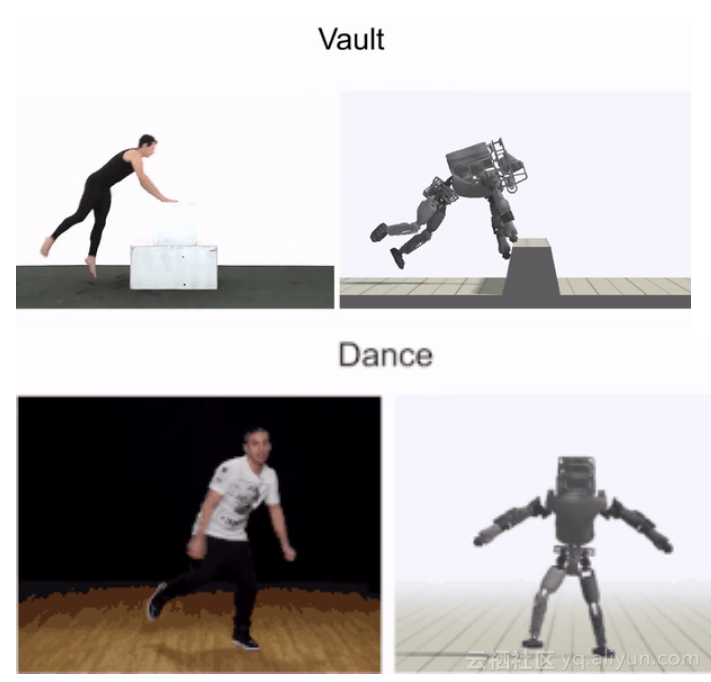
拥有一个模拟人物的优点之一是,我们可以利用模型将这些行为应用到新的环境中。在这里,我们的模型,学习适应不规则地形的运动,而原始视频,也就是学习对象中中的人物是在平坦的地面中演示的。

尽管环境与原始视频有很大的不同,但学习算法仍然为处理这些新环境开发了相当合理的策略。
总之,这个学习框架实际上是采取最简单的方法来解决模仿视频的问题。关键在于将问题分解为更易于管理的部分,为这些部分选择正确的方法,并将它们有效地集成在一起。然而,模仿视频的技巧仍然是一个极具挑战性的问题,我们还无法复制大量的视频片段:

但令人鼓舞的是,只要将现有的技术集成在一起,就可以在这个具有挑战性的问题上走得更远。希望这项工作将有助于未来的技术,让机器能够利用大量公开的视频数据,获得一系列真正令人震惊的技能。
原文发布时间为:2018-10-10
本文作者:蒋宝尚
