1.背景介绍
异常检测可以定义为“基于行动者(人或机器)的行为是否正常作出决策”,这项技术可以应用于非常多的
行
业中,比如金融场景中做交易检测、贷款检测;工业场景中做生产线预警;安防场景做入侵检测等等。
根据业务要求的不同,流计算在其中扮演着不同的角色:既可以做在线的欺诈检测,也可以做决策后近实时
的
结果分析、全局预警与规则调整等。
本文先介绍一种准实时的异常检测系统。
所谓准实时,即要求延迟在100ms以内。
比如一家银行要做一个实时的交易检测,判断每笔交易是否是正
常
交易:如果用户的用户名和密码被盗取,系统能够在盗取者发起交易的瞬间检测到风险来决定是否冻结这
笔
交
易。
这
种场景对实时性的要求非常高,否则会阻碍用户正常交易,所以叫做准实时系统。
由于行动者可能会根据系统的结果进行调整,所以规则也会更新,流计算和离线的处理用来研究规则是否
需
要
更新以及规则如何更新。
2.系统架构与模块综述
为了解决这个问题,我们设计如下的系统架构:
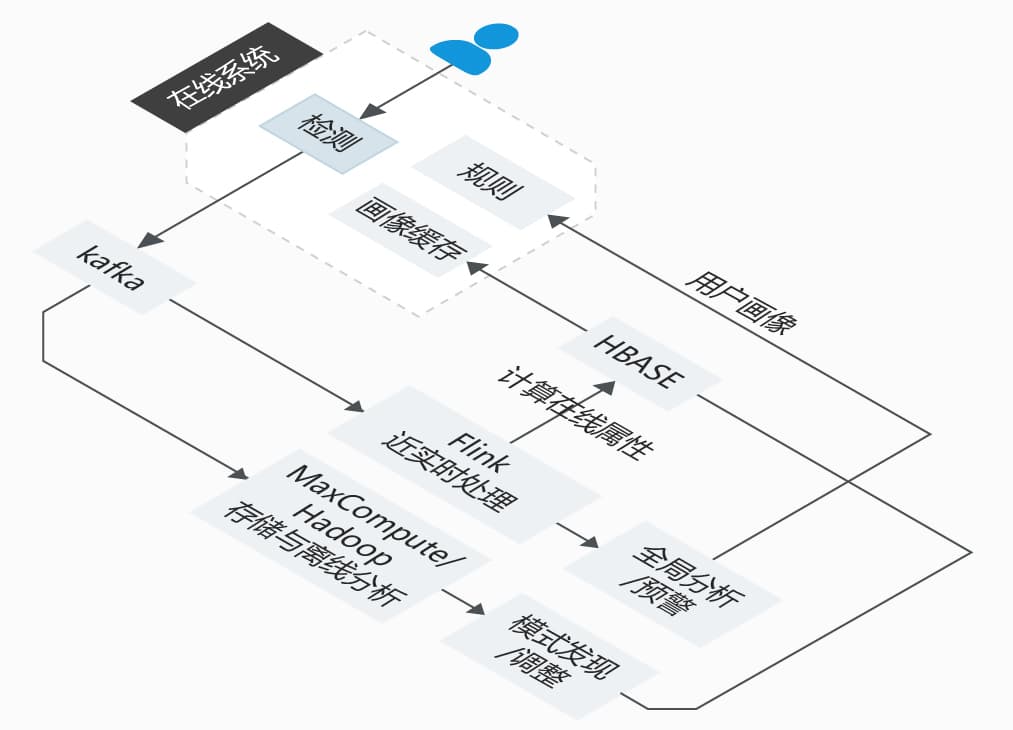
-
在线系统,完成在线检测功能,可以是web服务的形式:
-
针对单条事件进行检测
-
根据全局上下文进行检测,比如全局黑名单
-
根据用户画像或近期一段时间的信息进行检测,比如最近20次交易时间与地点
-
-
kafka,把事件与检测的结果及其原因发送到下游
-
flink近实时处理
近实时的更新用户的属性,比如最近的交易时间&地点;
汇总统计全局的检测状态,并做同期对比,比如某条规则的拦截率突然发生较大变化、全局通过率突然增高或降低等等;
maxcompute/hadoop存储与离线分析,用于保留历史记录,并由业务人员探索性的研究有没有新的模式hbase,保存用户
画像
3.关键模块
3.1 在线检测系统
交易的异常检测在本系统中实现,他可以是一个web服务器,也可以是嵌入到客户端的系统。在本文中,
我
们假
设它是一个web服务器,其主要任务就是检阅到来的事件并反馈同意或拒绝。
针对每一个进入的事件,可以进行三个层次的检测:
-
事件级检测
只用该事件本身就能完成检测,比如格式判断或基本规则验证(a属性必须大于10小于30,b属性不能为空等等)
-
全局上下文检测
在全局信息中的上下文中,比如存在一个全局的黑名单,判断该用户是否在黑名单中。或者某属性大于或小雨全局的平
均值等。
-
画像内容检测
针对该行动者本身的跨多条记录分析,比如该用户前100次交易都发生在杭州,而本次交易发生在北京且距上次交易只有
10分钟,那就有理由发出异常信号。
所以这个系统至少要保存三方面的东西,一方面是整个检测的过程,一方面是进行判断的规则,一方面是
所需
的全局数据,除此之外,根据需要决定是否把用户画像在本地做缓存。
3.2 kafka
kafka主要用来把检测的事件、检测的结果、拒绝或通过的原因等数据发送到下游,供流计算和离线计算
进行
处理。
3.3 flink近实时处理
在上面的系统中已经完成了异常检测,并把决策发送到了kafka,接下来我们需要使用这些数据针对当前
的
策略
进行新一轮的防御性检测。
即使已知的作弊行为已经输入到模型和规则库中进行了标记,但总有“聪明人”尝试欺诈。他们会学习现在的
系
统,猜测规则并作出调整,这些新的行为很可能超出了我们当前的理解。所以我们需要一种系统来检测整体
系统
的异常,发现新的规则。
也就说,我们的目标不是检测单个事件是否有问题,而是要检测这些用来检测事件的逻辑本身有没有问题,
所
以一定要站在比事件更高的层面来看问题,如果在更高的层面发生变化,那么有理由考虑对规则/逻辑进行
调整。
具体来说,系统应该关注一些宏观指标,比如总量,平均值,某个群体的行为等等。这些指标发生了变化
往往
表示某些规则已经失效。
举几个例子:
某条规则之前的拦截率是20%,突然降低到了5%;
某天规则上线后,大量的正常用户均被拦截掉了;
某个人在电子产品上的花费突然增长了100倍,但同时其他人也有很多类似的行为,这可能具有某种说得通的解释(比如
Iphone上市);
某人连续几次行为,单次都正常,但不应该有这么多次,比如一天内连续买了100次同一产品【开窗分析】;
识别某种组合多条正常行为的组合,这种组合是异常的,比如用户买菜刀是正常的,买车票是正常的,买绳子也是正常的,
去加油站加油也是正常的,但短时间内同时做这些事情就不是正常的。通过全局分析能够发现这种行为的模式。
业务人员根据流计算产生的近实时结果能够及时发现规则有没有问题,进而对规则作出调整。
除此之外,流计算还能进行用户画像的实时更新更新,比如统计用户过去10分钟的几次行为,最近10次的登
陆
地
点等等。
3.4 maxcompute/hadoop离线存储于探索性分析
在这个环节中,可以通过脚本、sql、或机器学习算法来进行探索性分析,发现新的模型,比如通过聚类算
法
把
用户进行聚类、对行为打标后进行模型的训练等等,或者周期性的重新计算用户画像。这里和业务关系很
大,
不
多过多描述。
3.5 hbase用户画像
hbase保存着流计算&离线计算产生的用户画像,供检测系统使用。之所以选择hbase主要是为了满足实时
查询
的需求。
4.总结
上面给出了一个准实时异常检测系统的概念性设计,业务逻辑虽然简单,但整个系统本身是非常完整且具
有良
好扩展性的,所以可以在这个基础上进一步去完善。
后面我会再介绍近实时的异常检测系统,即实时性要求不那么高,要求在秒级的异常检测系统,在近实时
异
常检
测系统中,流计算会发挥更大的作用。
5.参考资料
《hadoop application architectures》
本文为郭华(付空)原创,阿里云实时计算高级产品经理。

了解更多,加入实时计算 Flink 钉钉群




