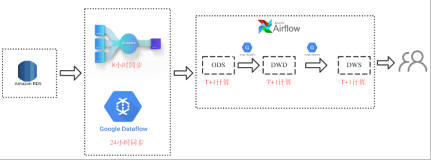
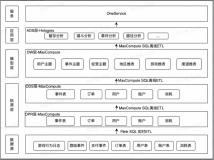
9月20日 E2-5 现场开讲。
实验活动内容地址如下:
1、在控制台使用OSS Select
2、基于日志的安全分析实战
3、智能媒体管理服务控制台功能体验
4、企业办公数据处理和分发(函数计算篇)
5、9.20 杭州云栖ClouderLab:环境准备
欢迎大家通过上面的网址进行动手试验课程。
9月20日 E2-5 现场开讲。
实验活动内容地址如下:
1、在控制台使用OSS Select
2、基于日志的安全分析实战
3、智能媒体管理服务控制台功能体验
4、企业办公数据处理和分发(函数计算篇)
5、9.20 杭州云栖ClouderLab:环境准备
欢迎大家通过上面的网址进行动手试验课程。