初步认识RocketMQ的核心模块

rocketmq-broker:接受生产者发来的消息并存储(通过调用rocketmq-store),消费者从这里取得消息。
rocketmq-client:提供发送、接受消息的客户端API。
rocketmq-namesrv:NameServer,类似于Zookeeper,这里保存着消息的TopicName,队列等运行时的元信息。(有点NameNode的味道)
rocketmq-common:通用的一些类,方法,数据结构等
rocketmq-remoting:基于Netty4的client/server + fastjson序列化 + 自定义二进制协议
rocketmq-store:消息、索引存储等
rocketmq-filtersrv:消息过滤器Server,需要注意的是,要实现这种过滤,需要上传代码到MQ!【一般而言,我们利用Tag足以满足大部分的过滤需求,如果更灵活更复杂的过滤需求,可以考虑filtersrv组件】
rocketmq-tools:命令行工具
说到分布式事务,就会谈到那个经典的”账号转账”问题:2个账号,分布处于2个不同的DB,或者说2个不同的子系统里面,A要扣钱,B要加钱,如何保证原子性?
一般的思路都是通过消息中间件来实现“最终一致性”:A系统扣钱,然后发条消息给中间件,B系统接收此消息,进行加钱。
但这里面有个问题:A是先update DB,后发送消息呢? 还是先发送消息,后update DB?
假设先update DB成功,发送消息网络失败,重发又失败,怎么办?
假设先发送消息成功,update DB失败。消息已经发出去了,又不能撤回,怎么办?
所以,这里下个结论: 只要发送消息和update DB这2个操作不是原子的,无论谁先谁后,都是有问题的。
那这个问题怎么解决呢?
错误的方案0
有人可能想到了,我可以把“发送消息”这个网络调用和update DB放在同1个事务里面,如果发送消息失败,update DB自动回滚。这样不就保证2个操作的原子性了吗?
这个方案看似正确,其实是错误的,原因有2:
(1)网络的2将军问题:发送消息失败,发送方并不知道是消息中间件真的没有收到消息呢?还是消息已经收到了,只是返回response的时候失败了?
如果是已经收到消息了,而发送端认为没有收到,执行update db的回滚操作。则会导致A账号的钱没有扣,B账号的钱却加了。
(2)把网络调用放在DB事务里面,可能会因为网络的延时,导致DB长事务。严重的,会block整个DB。这个风险很大。
基于以上分析,我们知道,这个方案其实是错误的!
方案1–业务方自己实现
假设消息中间件没有提供“事务消息”功能,比如你用的是Kafka。那如何解决这个问题呢?
解决方案如下:
(1)Producer端准备1张消息表,把update DB和insert message这2个操作,放在一个DB事务里面。
(2)准备一个后台程序,源源不断的把消息表中的message传送给消息中间件。失败了,不断重试重传。允许消息重复,但消息不会丢,顺序也不会打乱。
(3)Consumer端准备一个判重表。处理过的消息,记在判重表里面。实现业务的幂等。但这里又涉及一个原子性问题:如果保证消息消费 + insert message到判重表这2个操作的原子性?
消费成功,但insert判重表失败,怎么办?关于这个,在Kafka的源码分析系列,第1篇, exactly once问题的时候,有过讨论。
通过上面3步,我们基本就解决了这里update db和发送网络消息这2个操作的原子性问题。
但这个方案的一个缺点就是:需要设计DB消息表,同时还需要一个后台任务,不断扫描本地消息。导致消息的处理和业务逻辑耦合额外增加业务方的负担。
方案2 – RocketMQ 事务消息
为了能解决该问题,同时又不和业务耦合,RocketMQ提出了“事务消息”的概念。
具体来说,就是把消息的发送分成了2个阶段:Prepare阶段和确认阶段。
具体来说,上面的2个步骤,被分解成3个步骤:
(1) 发送Prepared消息
(2) update DB
(3) 根据update DB结果成功或失败,Confirm或者取消Prepared消息。
可能有人会问了,前2步执行成功了,最后1步失败了怎么办?这里就涉及到了RocketMQ的关键点:RocketMQ会定期(默认是1分钟)扫描所有的Prepared消息,询问发送方,到底是要确认这条消息发出去?还是取消此条消息?
具体代码实现如下:
也就是定义了一个checkListener,RocketMQ会回调此Listener,从而实现上面所说的方案。
// 也就是上文所说的,当RocketMQ发现`Prepared消息`时,会根据这个Listener实现的策略来决断事务
TransactionCheckListener transactionCheckListener = new TransactionCheckListenerImpl();
// 构造事务消息的生产者
TransactionMQProducer producer = new TransactionMQProducer("groupName"); // 设置事务决断处理类 producer.setTransactionCheckListener(transactionCheckListener); // 本地事务的处理逻辑,相当于示例中检查Bob账户并扣钱的逻辑 TransactionExecuterImpl tranExecuter = new TransactionExecuterImpl(); producer.start() // 构造MSG,省略构造参数 Message msg = new Message(......); // 发送消息 SendResult sendResult = producer.sendMessageInTransaction(msg, tranExecuter, null); producer.shutdown();public TransactionSendResult sendMessageInTransaction(.....) {
// 逻辑代码,非实际代码
// 1.发送消息
sendResult = this.send(msg); // sendResult.getSendStatus() == SEND_OK // 2.如果消息发送成功,处理与消息关联的本地事务单元 LocalTransactionState localTransactionState = tranExecuter.executeLocalTransactionBranch(msg, arg); // 3.结束事务 this.endTransaction(sendResult, localTransactionState, localException); }然后执行本地事务,具体代码如下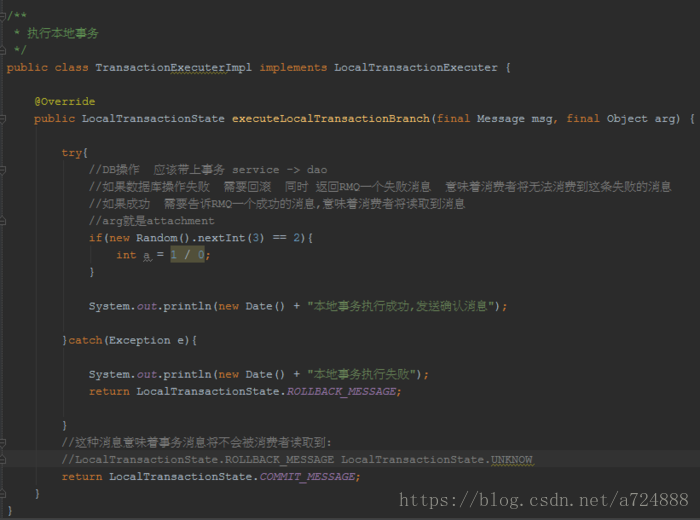
上面所说的消息中间件上注册的listener,超时以后会回调producer的接口以确定事务执行情况
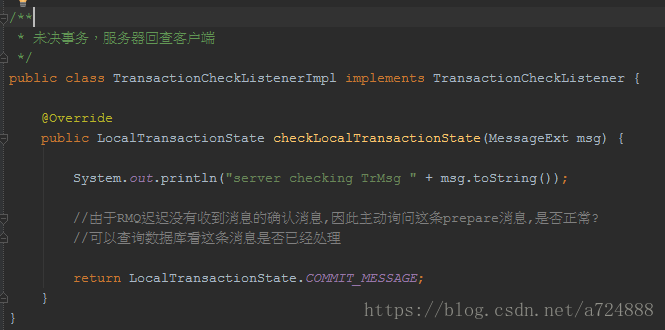
总结:对比方案2和方案1,RocketMQ最大的改变,其实就是把“扫描消息表”这个事情,不让业务方做,而是消息中间件帮着做了。
至于消息表,其实还是没有省掉。因为消息中间件要询问发送方,事物是否执行成功,还是需要一个“变相的本地消息表”,记录事物执行状态。
人工介入
可能有人又要说了,无论方案1,还是方案2,发送端把消息成功放入了队列,但消费端消费失败怎么办?
消费失败了,重试,还一直失败怎么办?是不是要自动回滚整个流程?
答案是人工介入。从工程实践角度讲,这种整个流程自动回滚的代价是非常巨大的,不但实现复杂,还会引入新的问题。比如自动回滚失败,又怎么处理?
对应这种极低概率的case,采取人工处理,会比实现一个高复杂的自动化回滚系统,更加可靠,也更加简单。
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站。(关注公众号后回复”Java“即可领取 Java基础、进阶、项目和架构师等免费学习资料,更有数据库、分布式、微服务等热门技术学习视频,内容丰富,兼顾原理和实践,另外也将赠送作者原创的Java学习指南、Java程序员面试指南等干货资源)

![]()
