应用场景
之前介绍了单节点,部署伪分布式hadoop集群,可以作为自己使用,但是真正投入生产环境,伪分布式是不够的,仅仅作为个人研究测试使用,此时我们需要部署搭建hadoop完全分布式集群,此hadoop性能将更加强悍,满足生产需求,下面就搭建Apache Hadoop2.6.0环境演示。
操作步骤
1. 配置网络[每个节点]
2. 关闭防火墙[每个节点]
# systemctl stop firewalld.service
# systemctl disable firewalld.service
# vim /etc/selinux/config #设置selinux = disabled3. 修改主机名和配置hosts[每个节点]
# vim /etc/hostname #3个节点分别命为hadoop0,hadoop1,hadoop2
# vim /etc/hosts #添加3个节点ip以及对应的主机名4. 配置3个节点间的SSH互信
5. 配置时间同步
6. 安装jdk[每个节点]
7. 主节点安装mysql[主节点]
8. 安装配置hadoop2.6.0集群
8.1 安装hadoop
操作步骤:
1.将下载的hadoop2.6.0压缩包,上传到主节点的opt目录下
2.进行解压缩
3.配置环境变量
4.新建所需要的目录
# cd /opt
# tar -xzvf hadoop-2.6.0-x64.tar.gz
# mv hadoop-2.6.0 hadoop2.6.0 #解压hadoop安装包,并且修改目录为hadoop2.6.0
# vim /etc/profile 修改配置文件,加入hadoop的环境变量
export JAVA_HOME=/opt/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop2.6.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#mkdir /opt/hadoop2.6.0/tmp #创建目录,后续搭建过程中需要使用
#mkdir /opt/hadoop2.6.0/var
#mkdir /opt/hadoop2.6.0/dfs
#mkdir /opt/hadoop2.6.0/dfs/name
#mkdir /opt/hadoop2.6.0/dfs/data 8.2 修改hadoop-env.sh文件
# cd /opt/hadoop2.6.0/etc/hadoop/
# vim hadoop-env.sh
将:export JAVA_HOME=${JAVA_HOME}
修改为:export JAVA_HOME=/opt/jdk1.8 #修改为jdk目录
8.3 修改slaves文件
# cd /opt/hadoop2.6.0/etc/hadoop/
# vim slaveshadoop0
hadoop1
hadoop2
#此时是这种情况,hadoop0作为主节点,以及主备节点,管理节点,而同时hadoop0,hadoop1,hadoop2都作为数据节点!
8.4 修改core-site.xml文件
# cd /opt/hadoop2.6.0/etc/hadoop/
# vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop2.6.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop0:9000</value>
</property>
</configuration>8.5 修改hdfs-site.xml文件
# cd /opt/hadoop2.6.0/etc/hadoop/
# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop2.6.0/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop2.6.0/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
</configuration>8.6 修改mapred-site.xml文件
# cd /opt/hadoop2.6.0/etc/hadoop/
# cp mapred-site.xml.template mapred-site.xml
# vim hdfs-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop0:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/opt/hadoop2.6.0/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>8.6 修改yarn-site.xml文件
# cd /opt/hadoop2.6.0/etc/hadoop/
# vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>12288</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
</configuration>**注:在主节点上配置好hadoop包后,同步到另外两个节点,配置不用修改,三个节点的配置都一样!
拷贝过去要注意目录是否有权限:chmod 777 -R /opt/hadoop2.6.0 【如果没有权限,会导致data节点无法启动】**
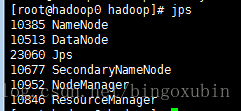
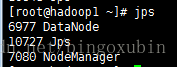
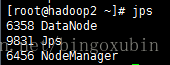
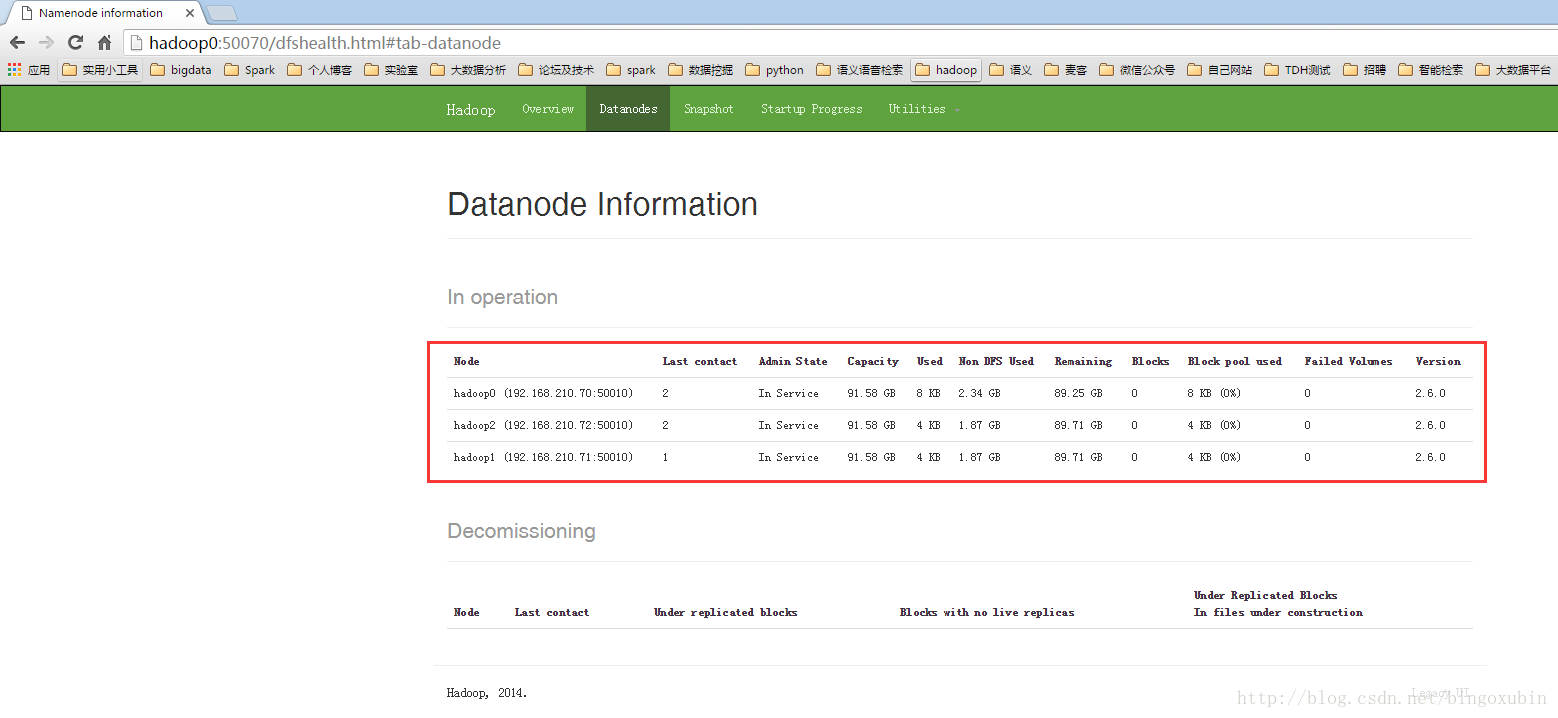
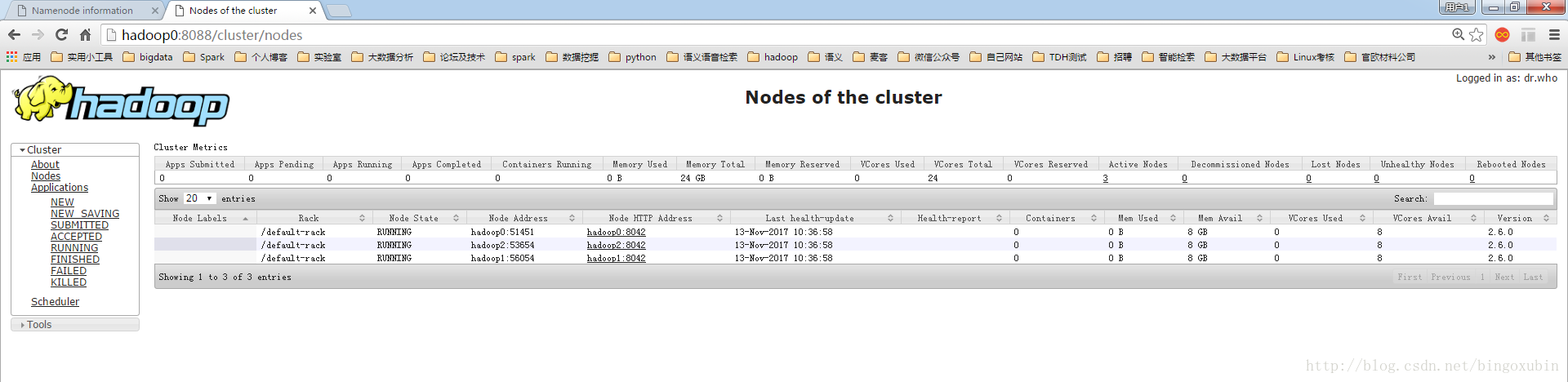
9. hadoop集群的初始化以及启动【主节点hadoop0上操作】
在管理节点上进行初始化以及启动
# cd /opt/hadoop2.6.0/bin
# ./hadoop namenode -format #初始化hadoop集群
格式化成功后,可以在看到在/opt/hadoop2.6.0/dfs/name/目录多了一个current目录,而且该目录内有4个文件。
# cd /opt/hadoop2.6.0/sbin
# ./start-all.sh #启动hadoop集群