我们这里要简要介绍一下增强学习(RL)——一种为了提高玩游戏效率的训练程序的通用技术。我们的目标是解释其实际实现:我们讲述一些基本理论,然后走马观花地看一下为玩《战舰》游戏而训练神经网络的最小python程序。
导言
增强学习[RL]技术是一种可用于提高效玩游戏效率的学习算法。与督导机器学习[ML]方法一样,增强学习是从数据——这里是指过去玩游戏的数据——中进行学习。然而,尽管督导学习算法只是根据现有的数据进行训练,但RL还挑战如何在收集数据的过程中表现良好性能。具体地说,我们所追求的设计原则是
- 让程序从过去实例中识别好的战略,
- 通过连续地玩游戏快速地学习新的战略。
我们在这里特想让我们的算法快速学习的理由是在培训数据有限或者战略空间太大而难以进行穷尽搜索的情况下最富有成果地运用RL。正是在这种体制下督导技术面临困境而RL则闪耀着光芒。
我们在本贴中要回顾一般性的RL培训程序:策略梯度、深度学习方案。我们下一节要回顾一下这种办法背后的理论。随后,我们将粗略地演示一下培训神经网络来玩战舰游戏的 python 实现。
我们的python码可以从我们的github网页这里下载。它需要 jupyter, tensorflow, numpy, 和 matplotlib包。
策略梯度,深度RL
策略深度和深度RL有两个主要构件。下面我们要详述二者并描述它们是如何协作训练好的模型的。
策略网络
一定深度RL算法的策略是一种神经网络,它将状态值ss映射为一定游戏行为 aa的概率。 换句话说,该网络的输入层接受环境的数字编码——游戏在特定时刻的状态。当输入通过网络馈送后,其输出层的值对应着我们现有每个行动可选的对数概率——我们可供选择的每个可能的行动都有一个输出节点。请注意如果我们肯定知道我们应采取的步骤,只有一个输出节点有一定的概率。但如果我们的网络不能肯定哪种行动最优时,那么就不只一个节点有一定的权值。
为了说明这一点,我们来图示一下下面“战舰”程序中所用的网络。(要回顾“战舰”的游戏规则请看注[1])简明起见,我们只用一维战舰网格。我们然后对我们对手的每个网格位置用一个输入神经元将我们对目前的环境知识进行编码。具体地说,我们对于每个神经元/下标运用下列编码:

在下面例图中,我们有五个输入神经元,因此游戏盘的大小是五。前三个神经元的值是−1−1 表明我们尚未轰炸这些网格点。最后两个分别是+1+1 和 00, 意味着战舰位于第四而不是第五的位置。
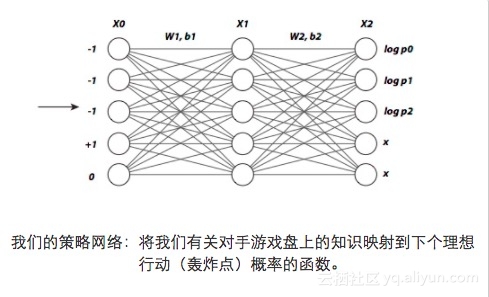
需要注意的是,在所显示的策略网输出层中,前三项值标为对数概率。这些值对应着每个下标的下次轰炸的概率。我们不能再次轰炸第四和第五个网格点,所以,尽管网络可能对这些神经元输出一些值,我们会忽略它们。
需要注意的是,在所显示的策略网输出层中,前三项值标为对数概率。这些值对应着每个下标的下次轰炸的概率。我们不能再次轰炸第四和第五个网格点,所以,尽管网络可能对这些神经元输出一些值,我们会忽略它们。 在我们继续前,我们注意到我们对我们的策略运用神经网络的理由是进行有效地归纳:对于象围棋这样有大量状态值的游戏来说,收集每个可能的游戏盘位置的数据并不可行。这正是ML算法所擅长的场合——根据过去的观测进行归纳从而对新局面做出很好的预测。为了将注意力放在RL上,我们不想在本贴中回顾ML算法(但你可以看看我们的库中的入门章节)。我们只是提请注意——利用这些工具,我们通过只培训游戏中有代表性的子集就能获得良好的性能而不必研究会非常庞大的整个集合。
收益函数
为了训练RL算法,我们必须反复地进行游戏/得分过程:我们根据当前的策略玩游戏,根据与该网络输出的概率成比例的频率做出移动选择。如果所采取的行动得到好的结果,我们就要在往后提高这些行动的概率。
收益函数是我们用于对我们以前游戏的结果进行正式打分的工具——我们将鼓励我们的算法在游戏期间努力将该量最大化。它其实是RL算法的超级参数:可以使用许多不同的函数,并每个都得出不同的学习特征。对于我们的战舰程序来说,我们用下列函数
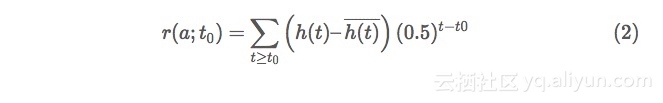
只要游戏日志完备,该函数考查在时间t0时所采取的行动a并返回命中值h(t)的加权和,以及该游戏所有未来步骤。在这里,如果我们在步骤t时命中,h(t)则为1,否则为0。
在到达(2)时, 我们承认并不对所有可能的收益函数集合进行仔细搜索。但我们肯定这一选择会有很好的游戏效果,它们有良好的目的性:具体地说,我们注意到加权项(0.5)t−t0(0.5)t−t0 能强烈地激发当前步骤的命中率 (对于在t0时命中,我们得到的收益为11 ), 但在(t0+1)(t0+1)时命中的行为在 t0t0 时也有收益—— 其值为0.50.5。同样,在 (t0+2)(t0+2) 时命中收益为0.250.25, 依此类推。 (2)的这种超前加权起到了鼓励有效探索棋局的作用:它迫使程序顾及有利于未来命中的步骤。 (2) 中出现的其他要素是减去h(t)¯¯¯¯¯¯¯¯¯h(t)¯。 这是随机网络会获得的预期收益。通过将该项除去,我们的网络只有表现超过随机选择才有收益——该收益是这一学习过程的净加速。
随机递减
为了训练我们的算法在游玩期间收益最大化,我们运用了递减法。为了表现这一点,我们设想让我们的网络参数 θθ 在游戏的某些特定步骤发生改变。对所有可能的步骤进行平均,于是有了预期收益的梯度公式,
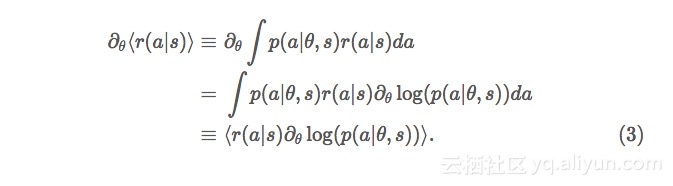
这里, p(a)p(a) 的值是我们网络行动的概率输出。
不过,我们通常无法求得上述最后一行的值。但我们可以用抽样值进行迫近:我们只是用我们当前网络玩游戏,因此我们用在第 ii次移动时所获得的实际收益取代上述的预期收益,
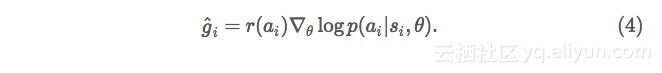
这里aiai 是所采取的行动, r(ai)r(ai)是获得的收益,可以通过反向传播求该对数的导数(对于那些熟悉神经网络的人来说:这是叉熵损失函数的导数,当你处理类似督导学习训练事例的事件时,可以用所选择行动 aiai 做为标记以应用该函数)。函数g^ig^i 提供理想梯度的噪声估计,但步骤多了会导致“随机”递减,一般推动我们朝着正确的收益最大化前进。
训练过程总结
总之,RL训练是迭代进行:要起动迭代步骤,首先我们用我们当前的策略网络玩游戏,随机地根据网络输出选择移动步骤。在游戏结束后,我们通过计算每次移动所获得的收益来对结果打分,例如在战舰游戏中,我们用(22)。 一旦完成这一步,我们就用 (44)来估计收益函数的梯度。最后,我们用αα小步长步骤参数更新网络参数 θ→θ+α∑g^iθ→θ+α∑g^i, 接着,我们用经过更新的网络继续玩新的游戏,依此类推。
要明白这一过程实际上是鼓励在练习中产生良好结果的行动,注意 (44) 与在步骤 ii中所获收益成比例的。因此,我们在 (44)的方向上调整参数,我们极力鼓励那些产生很大收益结果的行动。另外,收益为负的步骤受到抑制。网络按这种方式经过一段时间后将学会考察这一系统并提出可能产生最佳结果的步骤。
这说的是深度策略梯度RL的基础。我们现在回到我们战舰python示例上来。
Python 代码流程 — 战舰 RL
加载所需的包。
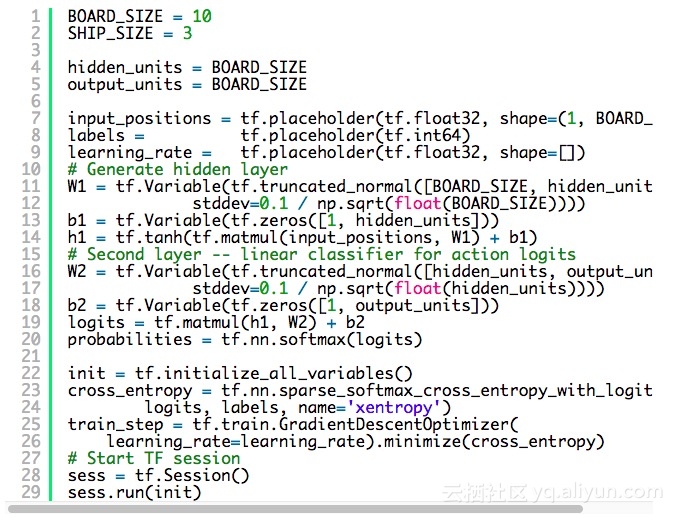
定义我们的网络——一个全面相联的三层系统。下面代码基本上是 tensorflow 标准本,通过了其第一教程就可得出。有一项非同凡响的事是我们已将(26)集的学习速度定为占位符值 (9) 。这将让我们用下列所观察到的捕获收益改变我们的步长。
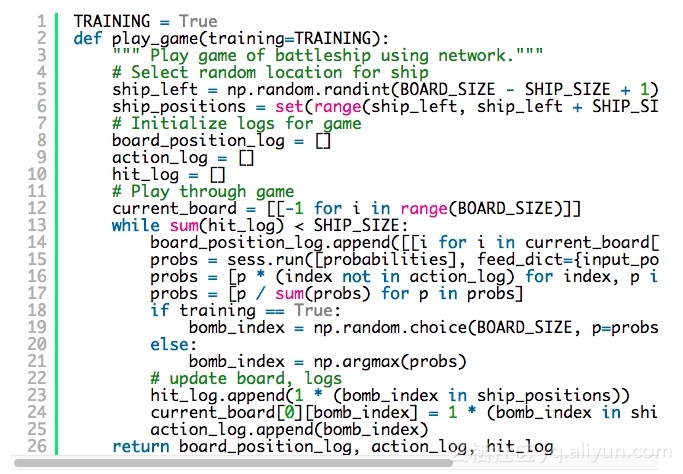
其次,我们定义了让我们用我们的网络玩游戏的方法。变量TRAINNING决定了我们是否采取理想步骤或选择随机步骤。请注意该方法返回一组记录游戏过程的日志集。这些是训练所需要的。
我们收益函数的实现(2):

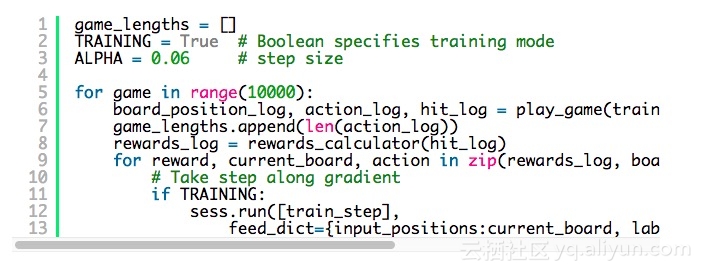
最后是我们的训练循环。我们反复地玩多次游戏,每次都记分,然后调整参数——用阿尔法乘以所获得收益得出学习速度。
运行上一单元,我们看到训练起作用了!下面例子通过将TRAINNING设为FALSE跟踪play_game()方法。这展示了一种智能步骤选择过程。

这里前五行是游戏盘编码——每一步都用(11)来填充网络。第二至最后一行是所选择的系列网络选择。最后一行是命中日志。请注意前两步很好地抽样了游戏盘不同地区。此后,所记录命中为 66。该算法然后智能地选择 77和 88,它能推断它们一定是战舰的最后位置。
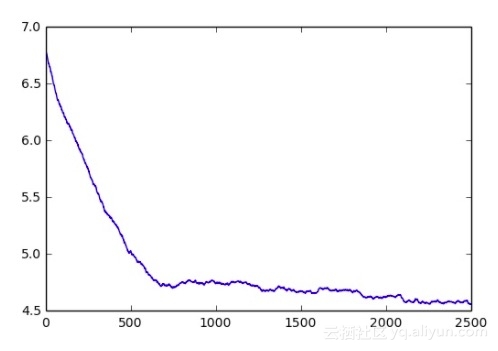
下图进一步地描述了学习过程的特征。它将游戏平均长度(完全轰炸战舰所需步骤)与训练时间进行对照。该程序非常迅速地学到基础知识并随着时间推进而持续进步。
小结
在本贴中,我们讲到RL的一种——即策略梯度、深度RL方案。该方法一般是当前最知名战略 ,偶尔也从其他方法中取样,最终实现策略的迭加改进。其两个主要成份是策略网络和收益函数。尽管网络结构设计通常是督导学习考虑得最多的地方,但在RL的情况下最费神的是收益函数。为了方便训练(依靠长远预测会放慢学习过程),好的选择应该是时间上尽可能地靠近。然而,收益函数常常也会损害到这一过程的最终目标(“赢”这场游戏——鼓励侧向追求,而一些侧向追求是不必要的,但如果不加注意会时常出现)。要在这两种互相竞争的要求间进行权衡并不容易。所以收益函数设计在某种程度上说是一种艺术。
我们这个简短的介绍只想说明RL实际上是如何实行的。更多细节,我们推荐两个来源:Sutton 和Barto的文本书[3]和最近John Schulman的谈话[4]。
注释和参考资料
[1]游戏规则:(常见的简单游戏:略)
[2] 我有位同事(HC)提出,该程序可能在某个点上开始拟合过度。但这种一维游戏战舰的位点太少,训练集分割似乎不太合适。不过,如果我们转移到更高维度并加入更多战舰时会管用。
[3] Sutton 和 Barto, (2016). 《增强学习引论》文本地址在 此.
[4] John Schulman, (2016),《弯区的深度学习学院》 Youtube 的谈话录音在 此.
本文译者为:kundogma
原文来自:EVAVDB
