前言
虽然前端面试中很少会考到算法类的题目,但是你去比如像腾讯一样的大厂面试的时候就知道了,对基本算法的掌握对于从事计算机科学技术的我们来说,还是必不可少的,每天花上 10 分钟,轻松了解基本算法概念以及前端的实现方式。
另外,掌握了一些基本的算法实现,对于我们日常开发来说,也是如虎添翼,能让我们的 js 业务逻辑更趋高效和流畅。
特别说明
今天这个算法稍微比较复杂,牵扯到的概念也比较多,需要先了解基础知识。我给每篇文章的定位是 10 分钟内应该要掌握下来,所以我就擅作主张地将堆排序算法讲解分割为上、下两篇文章了,希望能让大家阅读起来更清爽愉快。
文章结构
《堆排序(上)》文章结构:
- 简单的二叉树
- 简单的满二叉树
- 简单的完全二叉树
- 简单的堆
- 简单的堆分类
《堆排序(下)》文章结构:
- 算法介绍
- 轻松实现大顶堆调整
- 轻松实现创建大顶堆
- 轻松实现堆排序
- 复杂度分析
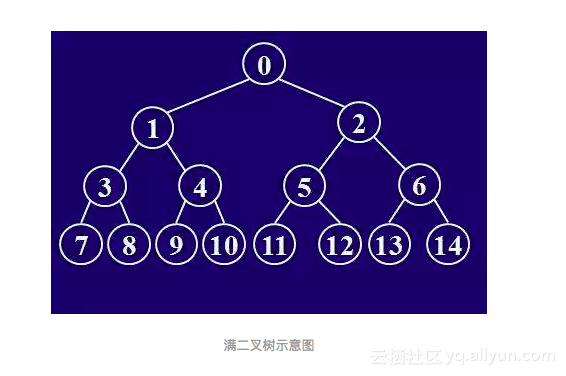
简单的二叉树
要了解堆,必须先了解一下二叉树,两者关系在下一步阐述。
二叉树(Binary Tree)是每一个节点最多有两个分支的树结构,通常分支被称作「左子树」和「右子树」,分支具有左右次序,不能随意颠倒。
二叉树第 i 层最多拥有 2^(i-1) 个节点,深度为 k 的二叉树最多共有 2^(k+1)-1 个节点,且定义根节点所在的层级 i=0,所在的深度 k=0。注意该定义在全文起作用,后续不继续提及。
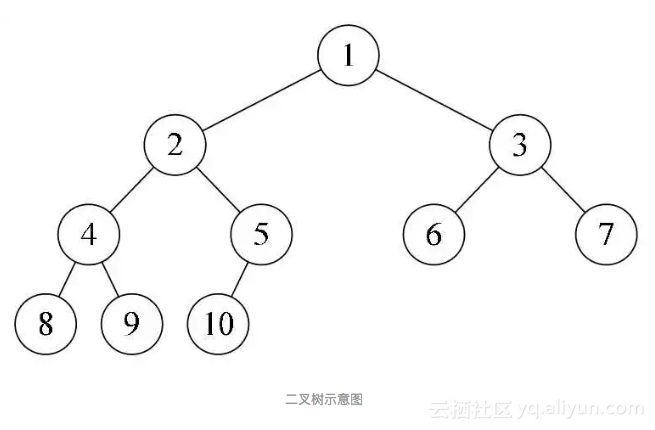
简单的满二叉树
假设某个二叉树深度为 k,第 i 层拥有 2^(i-1) 个节点,且总共拥有 2^(k+1)-1 个节点,这样的二叉树称为「满二叉树」。
换句话说,二叉树的每一层都是满的,除了最后一层上的节点,每一个节点都具有左节点和右节点。
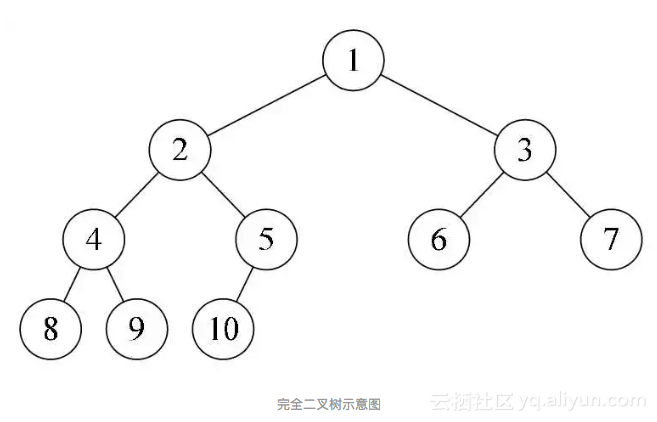
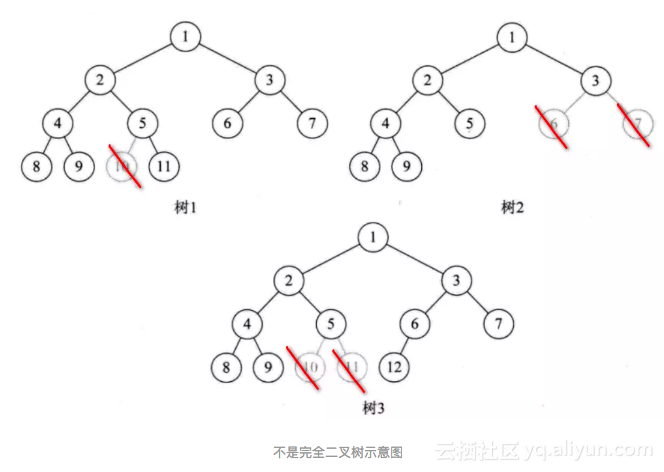
简单的完全二叉树
假设某个二叉树深度为 k,共有 n 个节点,当且仅当其中的每一个节点,都可以和同样深度为 k 的满二叉树上的,按层序编号相同的节点,也就是序号为 1 到 n 的节点,均一一对应时,这样的二叉树称为「完全二叉树」。
满二叉树一定是完全二叉树,但是完全二叉树不一定是满二叉树。
简单的堆
堆(Heap),一类特殊的数据结构的统称,通常是一个可以被看做一棵树的数组对象。
堆的实现通过构造二叉堆(binary heap),实为二叉树的一种,由于其应用的普遍性,当不加限定时,均指该数据结构的这种实现。
堆,是完全二叉树。
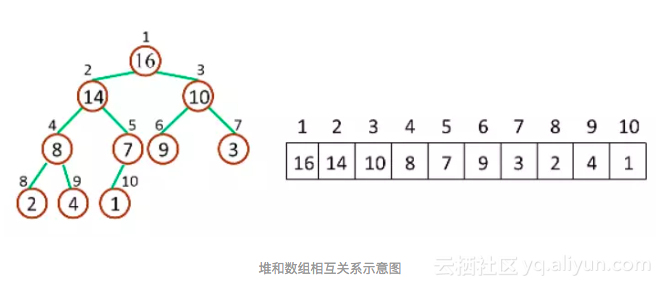
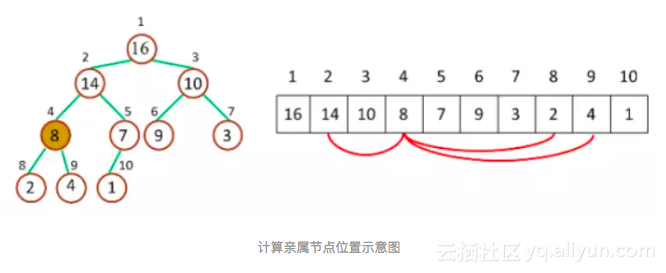
对于给定的某个节点的下标 idx,可以很容易地计算出这个节点的父节点与孩子节点的下标:
// 计算父节点的下标
var getParentPos = function(idx){
return Math.floor(idx / 2);
}
// 计算左子节点的下标
var getLeftChildPos = function(idx){
return 2*idx;
};
// 计算右子节点的下标
var getRightChildPos = function(idx){
return 2*idx + 1;
};
如下图,取下标 idx = 4 的节点,则其父节点的下标就为 Math.floor(4/2) === 2,其左子节点的下标就为 2*4 === 8,其右子节点的下标就为 2*4 + 1 === 9。
但将堆转换为数组时,由于数组的初始化下标始终为 0,所以我们的堆数据结构模型在此时要发生如下改变:
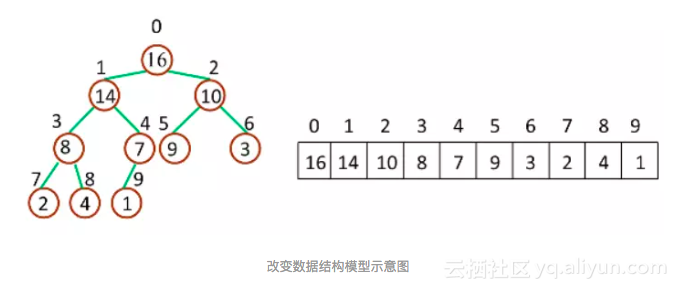
// 计算父节点的下标
var getParentPos = function(idx){
return Math.floor((idx-1) / 2);
}
// 计算左子节点的下标
var getLeftChildPos = function(idx){
return 2*idx + 1;
};
// 计算右子节点的下标
var getRightChildPos = function(idx){
return 2 * (idx+1);
};
简单的堆分类
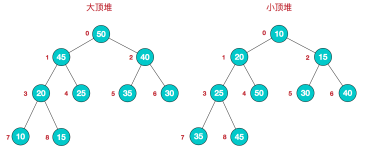
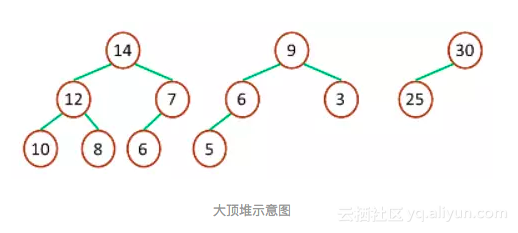
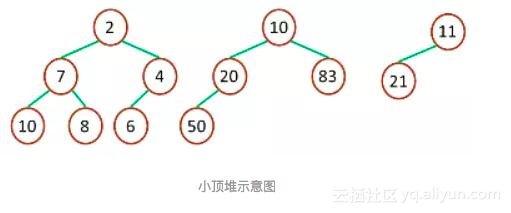
二叉堆一般分为两种:「大顶堆」和「小顶堆」。
假设有一个堆,其中每个节点的值都大于或等于其左右孩子节点的值,则该堆称为「大顶堆」。「大顶堆」的最大元素值出现在根节点。
本文来源: 掘金 如需转载请联系原作者