热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
Java 中文官方教程 2022 版(十六)(2)
Java 中文官方教程 2022 版(十六)(1)
使用Python打造爬虫程序之Python中的并发与异步IO:解锁高效数据处理之道
使用Python打造爬虫程序之破茧而出:Python爬虫遭遇反爬虫机制及应对策略
探索 Java 的函数式接口和 Lambda 表达式
使用Python打造爬虫程序之揭开动态加载内容的神秘面纱:Python爬虫进阶技巧
使用Python打造爬虫程序之HTML解析大揭秘:轻松提取网页数据
使用Python打造爬虫程序之入门探秘:掌握HTTP请求,开启你的数据抓取之旅
关系型数据库REVOKE语句
关系型数据库GRANT语句
利用Python的Pandas库进行数据清洗和分析
关系型数据库DROP语句
await
async、await
git常用操作+常见问题汇总
探索前端领域中的微前端架构
优化前端性能:提升网页加载速度的五种技巧
html标签的样式
人工智能在社会中的影响与未来展望
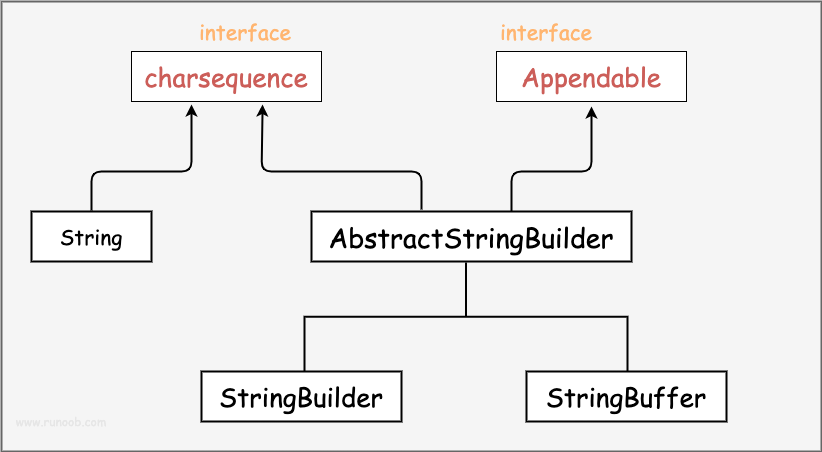
Java StringBuffer 和 StringBuilder 类
触发式邮件邮箱API发送邮件的方法和步骤
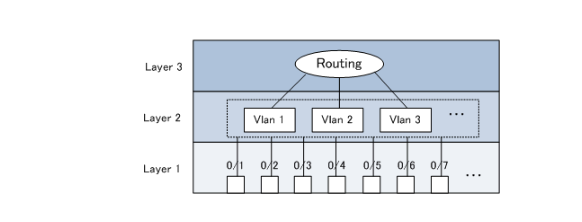
【技术分享】Multilayer Switch
element组件问题
【webpack】弄清楚webpack 与vite的区别
数组去重面试
使用 Java 进行大数据处理和分析
探究 $nextTick 的实现原理
SendCloud和Aoksend邮箱API发送邮件的方法
Swiper库和Glide.js库的性能有何区别
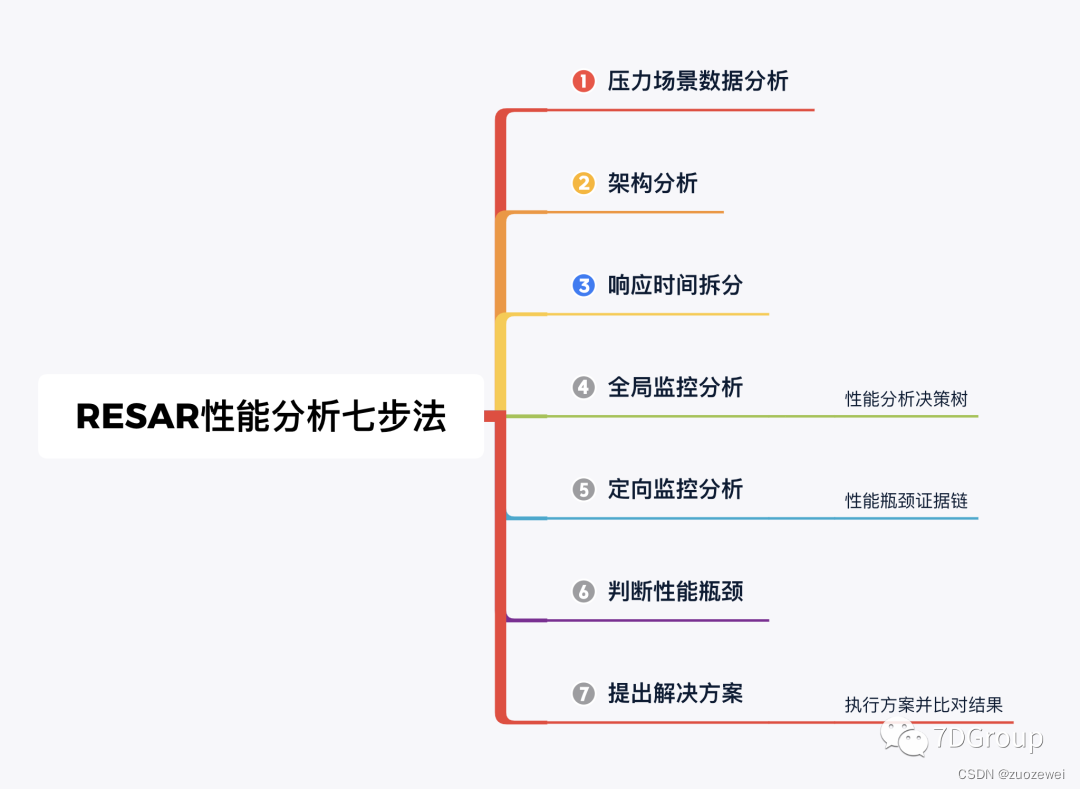
7DGroup性能实施项目日记9
BOSHIDA DC电源模块的未来发展方向和创新应用领域
深入理解 Java 内存模型和垃圾回收机制
构建高效的后端API:优化方法与实践
探索人工智能在医疗诊断中的应用
构建高效稳定的Docker容器集群:从原理到实践
探索Python中的异步编程:从回调到async/await
ZeptoMail邮箱API发送邮件的方法
中间件数据传输重传机制
光学雨量计原理及其在城市雨水管理中的应用
Servlet 教程 之 Servlet 客户端 HTTP 请求 1
中间件数据传输数据校验
中间件数据传输数据加密
Vue的缓存组件 | 详解KeepAlive
Servlet 教程 之 Servlet 表单数据 8
光学雨量计在城市雨水管理中具有重要的应用价值
foreach 跳不出循环
rpc简介
常见的前端加密方法