在 10G 和 11G 中,DBA 可以根据文件名,确定这个文件在 ASM 磁盘组上的分布,然后 dd 出来每一个 AU,最后拼凑成一个完成的数据文件。
在 12C 的 PDB 中,我们尝试用这种方法,进一步,根据给定的文件号和表的块号,从 ASM 磁盘上 dd 出来这些块。之后 sqlplus 清空这个表,再将出来的数据 dd 回去,以验证是否准确找到了需要的 block。
我们可以推算出表块跟 AU 的关系。
环境准备
测试环境是 8 KB 的标准块,有一个 5 个磁盘做 Normal 冗余的磁盘组,AU 大小为 4M。
PDB 生成的测试数据将要放在这个磁盘组。
如果只有一个盘的磁盘组,或者外部冗余,就没有必要测试了。
--这个是 pdb,要去 pdb 里面查询。
--在我的环境在 PDB 里面创建表空间,文件号 21。
alter session set container=ora122pdb1;
SQL> create tablespace asmres datafile '+DATAC1' SIZE 100M AUTOEXTEND ON;
Tablespace created.
然后查询文件名为 asmres.271.978291939,文件号为 21.
下面创建测试用表。测试用表这里,先创建空表,再给某个表打数,构造一个看起来较为错乱的 extent 分布。
create table asmtable tablespace asmres as select * from dba_objects where 0=1;
create table asmtable2 tablespace asmres as select * from asmtable;
create table asmtable3 tablespace asmres as select * from asmtable;
create table asmtable4 tablespace asmres as select * from asmtable;
insert into asmtable select * from dba_objects where rownum<512;
查看这个几个表的 extents 分布。
SQL> select owner,SEGMENT_NAME,EXTENT_ID,FILE_ID,BLOCK_ID,BLOCKS,RELATIVE_FNO from dba_extents where SEGMENT_NAME like 'ASMTABLE%';
这个构造的场景,能比较明显看出来,extent 的分布规律。
注意,从这里可以看到,ASMTABLE 生成了第二个 extent。
--注意这里的 extend_id 跟 ASM 的 extend_number 是两个概念。不可以混用。
所以,ASMTABLE 这个表是由 21 号文件的,128,129,130,131,132,133,134,135,注意这里不连续,160,161,162,163,164,165,166,167,这16个块构成。
这些是 DB 层的概念,ASM 层的概念跟这个不一样,所以通过视图,无法对应出来。但是,可以推测。
验证
下面开始验证:
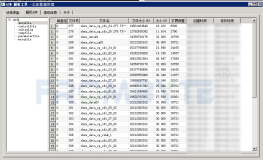
首先,拿出 21 号文件的 AU 分布图。
set linesize 255 pagesize 9999
col "FILE_NAME" format a30
col path for a25
col name for a10
set numw 15
set head on
select a.NAME "FILE_NAME",
p.NUMBER_KFFXP "FILE_NUMBER",
p.DISK_KFFXP "DISK_NUMBER",
p.AU_KFFXP "AU_NUMBER",
p.XNUM_KFFXP "EXTENT_NUMBER",
p.LXN_KFFXP "P/S_EXTENT",
a.group_number,
d.path,
dg.ALLOCATION_UNIT_SIZE/1048576 "AU_SIEZ_MB",
dg.name
from x$kffxp p, v$asm_alias a,v$asm_disk d,v$asm_diskgroup dg
where p.GROUP_KFFXP = a.GROUP_NUMBER
and p.NUMBER_KFFXP = a.FILE_NUMBER
and a.name like ('ASMRES.271.978291939')
and p.LXN_KFFXP=0 --只看primary的AU。1st_mirror什么的去掉。
and d.GROUP_NUMBER=p.GROUP_KFFXP
and dg.GROUP_NUMBER=p.GROUP_KFFXP
and p.DISK_KFFXP=d.disk_number
order by EXTENT_NUMBER,DISK_KFFXP,AU_KFFXP;
分析结果
这里查出来 26 个 AU,每个 AU 是 4M,总共 104M。为什么不是数据文件的100M ?
注意,这里的文件的 AU 在 ASM 磁盘组中的分布看起来是错乱的,基于 ASM 的算法,你会发现,AU 的分布是在磁盘 4,0,3,2,1 这样循环方式,打到每个成员盘上。
这里我过滤掉了主 AU 的 mirror,如果不过滤的话,另一组的规律也同样明显。
这里就是前面说的,没有直接的视图来对应数据文件块跟 AU 的关系,需要推测。
测试分两步,第一步是拿出来完整连续的文件,第二步是从文件里拿到表的块。
--Oracle 内部以及常做 ASM 恢复的 DBA 都有 Oracle 内部的一个脚本,可以直接从ASM 上拿出需要的块,但是那个,我没有。:)
首先,extent_number 的连续等于文件的连续。就是说按照连续 extent_number 方式,去对应的盘上找到对应的 AU,拿出来。再按照顺序组合。就是一个连续的数据文件。
下面是过程。
首先根据 AU 号把 dd 磁盘的命令生成出来,这里注意,最重要的是 order by 那一句 。以及 skip。
Select 'dd if='||d.path||' bs=4194304 count=1 skip='||p.au_kffxp||' of=asmres_'||p.XNUM_KFFXP||'.dbf'
from x$kffxp p, v$asm_alias a,v$asm_disk d,v$asm_diskgroup dg
where p.GROUP_KFFXP = a.GROUP_NUMBER
and p.NUMBER_KFFXP = a.FILE_NUMBER
and a.name in ('ASMRES.271.978291939')
and p.LXN_KFFXP=0
and d.GROUP_NUMBER=p.GROUP_KFFXP
and dg.GROUP_NUMBER=p.GROUP_KFFXP
and p.DISK_KFFXP=d.disk_number
order by XNUM_KFFXP;
生成的命令如下:
dd if=/dev/mapper/data07 bs=4194304 count=1 skip=321 of=asmres_0.dbf
dd if=/dev/mapper/data03 bs=4194304 count=1 skip=317 of=asmres_1.dbf
dd if=/dev/mapper/data06 bs=4194304 count=1 skip=325 of=asmres_2.dbf
dd if=/dev/mapper/data05 bs=4194304 count=1 skip=339 of=asmres_3.dbf
dd if=/dev/mapper/data04 bs=4194304 count=1 skip=315 of=asmres_4.dbf
dd if=/dev/mapper/data07 bs=4194304 count=1 skip=324 of=asmres_5.dbf
dd if=/dev/mapper/data03 bs=4194304 count=1 skip=319 of=asmres_6.dbf
dd if=/dev/mapper/data06 bs=4194304 count=1 skip=326 of=asmres_7.dbf
dd if=/dev/mapper/data05 bs=4194304 count=1 skip=340 of=asmres_8.dbf
dd if=/dev/mapper/data04 bs=4194304 count=1 skip=317 of=asmres_9.dbf
dd if=/dev/mapper/data07 bs=4194304 count=1 skip=327 of=asmres_10.dbf
dd if=/dev/mapper/data03 bs=4194304 count=1 skip=322 of=asmres_11.dbf
dd if=/dev/mapper/data06 bs=4194304 count=1 skip=304 of=asmres_12.dbf
dd if=/dev/mapper/data05 bs=4194304 count=1 skip=342 of=asmres_13.dbf
dd if=/dev/mapper/data04 bs=4194304 count=1 skip=319 of=asmres_14.dbf
dd if=/dev/mapper/data07 bs=4194304 count=1 skip=304 of=asmres_15.dbf
dd if=/dev/mapper/data03 bs=4194304 count=1 skip=324 of=asmres_16.dbf
dd if=/dev/mapper/data06 bs=4194304 count=1 skip=306 of=asmres_17.dbf
dd if=/dev/mapper/data05 bs=4194304 count=1 skip=177 of=asmres_18.dbf
dd if=/dev/mapper/data04 bs=4194304 count=1 skip=322 of=asmres_19.dbf
dd if=/dev/mapper/data07 bs=4194304 count=1 skip=305 of=asmres_20.dbf
dd if=/dev/mapper/data03 bs=4194304 count=1 skip=325 of=asmres_21.dbf
dd if=/dev/mapper/data06 bs=4194304 count=1 skip=309 of=asmres_22.dbf
dd if=/dev/mapper/data05 bs=4194304 count=1 skip=179 of=asmres_23.dbf
dd if=/dev/mapper/data04 bs=4194304 count=1 skip=323 of=asmres_24.dbf
dd if=/dev/mapper/data07 bs=4194304 count=1 skip=308 of=asmres_25.dbf
然后再生成 dd 合成文件的 SQL,注意里面的 seek。
SELECT
'dd if=asmres_'||p.XNUM_KFFXP||'.dbf bs=4194304 count=1 seek='||p.XNUM_KFFXP||' of=asmres.all.dbf'
from x$kffxp p, v$asm_alias a,v$asm_disk d,v$asm_diskgroup dg
where p.GROUP_KFFXP = a.GROUP_NUMBER
and p.NUMBER_KFFXP = a.FILE_NUMBER
and a.name in ('ASMRES.271.978291939')
and p.LXN_KFFXP=0
and d.GROUP_NUMBER=p.GROUP_KFFXP
and dg.GROUP_NUMBER=p.GROUP_KFFXP
and p.DISK_KFFXP=d.disk_number
order by XNUM_KFFXP;
生成的结果如下:
dd if=asmres_0.dbf bs=4194304 count=1 seek=0 of=asmres.all.dbf
dd if=asmres_1.dbf bs=4194304 count=1 seek=1 of=asmres.all.dbf
dd if=asmres_2.dbf bs=4194304 count=1 seek=2 of=asmres.all.dbf
dd if=asmres_3.dbf bs=4194304 count=1 seek=3 of=asmres.all.dbf
dd if=asmres_4.dbf bs=4194304 count=1 seek=4 of=asmres.all.dbf
dd if=asmres_5.dbf bs=4194304 count=1 seek=5 of=asmres.all.dbf
dd if=asmres_6.dbf bs=4194304 count=1 seek=6 of=asmres.all.dbf
dd if=asmres_7.dbf bs=4194304 count=1 seek=7 of=asmres.all.dbf
dd if=asmres_8.dbf bs=4194304 count=1 seek=8 of=asmres.all.dbf
dd if=asmres_9.dbf bs=4194304 count=1 seek=9 of=asmres.all.dbf
dd if=asmres_10.dbf bs=4194304 count=1 seek=10 of=asmres.all.dbf
dd if=asmres_11.dbf bs=4194304 count=1 seek=11 of=asmres.all.dbf
dd if=asmres_12.dbf bs=4194304 count=1 seek=12 of=asmres.all.dbf
dd if=asmres_13.dbf bs=4194304 count=1 seek=13 of=asmres.all.dbf
dd if=asmres_14.dbf bs=4194304 count=1 seek=14 of=asmres.all.dbf
dd if=asmres_15.dbf bs=4194304 count=1 seek=15 of=asmres.all.dbf
dd if=asmres_16.dbf bs=4194304 count=1 seek=16 of=asmres.all.dbf
dd if=asmres_17.dbf bs=4194304 count=1 seek=17 of=asmres.all.dbf
dd if=asmres_18.dbf bs=4194304 count=1 seek=18 of=asmres.all.dbf
dd if=asmres_19.dbf bs=4194304 count=1 seek=19 of=asmres.all.dbf
dd if=asmres_20.dbf bs=4194304 count=1 seek=20 of=asmres.all.dbf
dd if=asmres_21.dbf bs=4194304 count=1 seek=21 of=asmres.all.dbf
dd if=asmres_22.dbf bs=4194304 count=1 seek=22 of=asmres.all.dbf
dd if=asmres_23.dbf bs=4194304 count=1 seek=23 of=asmres.all.dbf
dd if=asmres_24.dbf bs=4194304 count=1 seek=24 of=asmres.all.dbf
dd if=asmres_25.dbf bs=4194304 count=1 seek=25 of=asmres.all.dbf
执行了之后,会得到一个 104M 的 asmres.all.dbf(你猜为什么不是当初创建的 100M ? )
拼接好了之后,开始 dbv
[grid@tafrac121 ~]$ dbv file=asmres.all.dbf
DBVERIFY: Release 12.2.0.1.0 - Production on Fri Jun 8 22:15:37 2018
Copyright (c) 1982, 2017, Oracle and/or its affiliates. All rights reserved.
DBVERIFY - Verification starting : FILE = /home/grid/asmres.all.dbf
DBVERIFY - Verification complete
Total Pages Examined : 12800
Total Pages Processed (Data) : 1409
Total Pages Failing (Data) : 0
Total Pages Processed (Index): 0
Total Pages Failing (Index): 0
Total Pages Processed (Other): 166
Total Pages Processed (Seg) : 0
Total Pages Failing (Seg) : 0
Total Pages Empty : 11225
Total Pages Marked Corrupt : 0
Total Pages Influx : 0
Total Pages Encrypted : 0
Highest block SCN : 2207155 (0.2207155)
[grid@tafrac121 ~]$
数据文件正常。
刚才说到 ASMTABLE 这个表是由 21 号文件的,128,129,130,131,132,133,134,135,注意这里不连续,160,161,162,163,164,165,166,167,这16个块构成。
以下是罗列的一些知识点:
数据文件上的块号也是连续的。
到这里就能把表的块号跟实际磁盘和AU对应起来了。
例如,假如说5号文件的17520块是哪个磁盘的哪个AU:
(17520*block_size)/au_size,就能得到extent_number号,根据分布图,找这个extent_number对应的AU和磁盘即可。
--但是注意:11.1以后,出现了可变extent,就是说在extent较大的时候,一个extent里有多个AU,具体数值应该是1M的AU size的时候,数据文件超过20G会触发可变extent。
附加验证:
用 dd 的方法,把一个表 dd 出来,然后,把这个表 delete 掉,然后再拿 dd 出来的块,覆盖回去,看看数据还在不在。
前面说过,数据库是 8192 的,AU 是 4M,所以一个 AU 可以存放,4*1024/8=512个块。 也就是说,这个表的所有块都在第一个 AU 里。
就是前面的这个 AU:
FILE_NAME FILE_NUMBER DISK_NUMBER AU_NUMBER EXTENT_NUMBER P/S_EXTENT GROUP_NUMBER PATH AU_SIEZ_MB NAME
ASMRES.271.978291939 271 4 321 0 0 1 /dev/mapper/data07 4 DATAC1
在 /dev/mapper/data07 盘上的 .AU 号是 321。
下面我们从数据文件上的位置,dd 出来这个表的数据。然后 SQLPLUS 清空这个表,再把 dd 出来的表块放回去。以验证我们推测的分布是正确的。
注意知识点:
ASM 文件跟放在文件系统上的数据文件,头部不一样,ASM 上的文件头部会多出来一个块。
比如创建一个 10M 的数据文件,在文件系统上是 10240K,在 ASM 上,这个文件的size 是10240+8K。
下面从已经 dd 出来的数据文件上,把表的 16 个块都 dd 出来。
dd if=asmres.all.dbf of=8_block_1.dd skip=129 bs=8192 count=8
dd if=asmres.all.dbf of=8_block_2.dd skip=161 bs=8192 count=8
SQL> select BYTES/1024 from dba_segments where segment_name='ASMTABLE';
BYTES/1024
---------------
128
把这个表,delete,清空掉。(如果这里用 truncate 会影响后面的结果不?)
SQL> delete from asmtable;
511 rows deleted.
SQL> commit;
Commit complete.
SQL> select count(*) from asmtable;
COUNT(*)
---------------
0
然后把刚才 dd 出来的文件覆盖回去。覆盖 /dev/mapper/data07 这个盘的 321 号AU,为了方便,我们把这个 AU 拿出来。
dd if=/dev/mapper/data07 bs=4194304 count=1 skip=321 of=AU_321_0.dbf
把上面提取出来的表的两个 dd 写进这个 AU 的 dd,再把这个 AU 的 dd 写回磁盘。
dd if=asmres.all.dbf of=8_block_1.dd skip=129 bs=8192 count=8
dd if=asmres.all.dbf of=8_block_2.dd skip=161 bs=8192 count=8
dd if=8_block_1.dd of=AU_321_0.dbf seek=129 bs=8192 count=8 conv=notrunc
dd if=8_block_2.dd of=AU_321_0.dbf seek=161 bs=8192 count=8 conv=notrunc
dd if=AU_321_0.dbf bs=4194304 count=1 seek=321 of=/dev/mapper/data07 conv=notrunc
然后重启整个数据库。
SQL> alter session set container=ora122pdb1;
Session altered.
SQL> select count(*) from asmtable;
COUNT(*)
----------
511
验证完毕,这样方式对应的 block 号和 au 号是正确的。
原文发布时间为:2018-07-10
本文作者:李敏
本文来自云栖社区合作伙伴“数据和云”,了解相关信息可以关注“数据和云”。