摘要: 如果说数据处理技术时代中数据是新能源,流计算就是让新能源发电的关键技术。基于阿里云流计算天猫双十一大屏可以实时展现上亿条数据订单。如何搭建具备亿级QPS处理能力的流式大数据处理系统,本文就阿里云流计算在大数据实时处理中带来的价值、流计算的显著优势以及应用场景和案例等方面的内容做了深入的分析。
本场视频精彩回顾,戳这里!
本场视频PPT下载,戳这里!
演讲嘉宾简介:
付空,阿里云高级产品专家
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本次的分享主要围绕以下三个方面:
一、为什么要用流计算
二、为什么要用阿里云流计算
三、如何用流计算
一、 为什么要用流计算
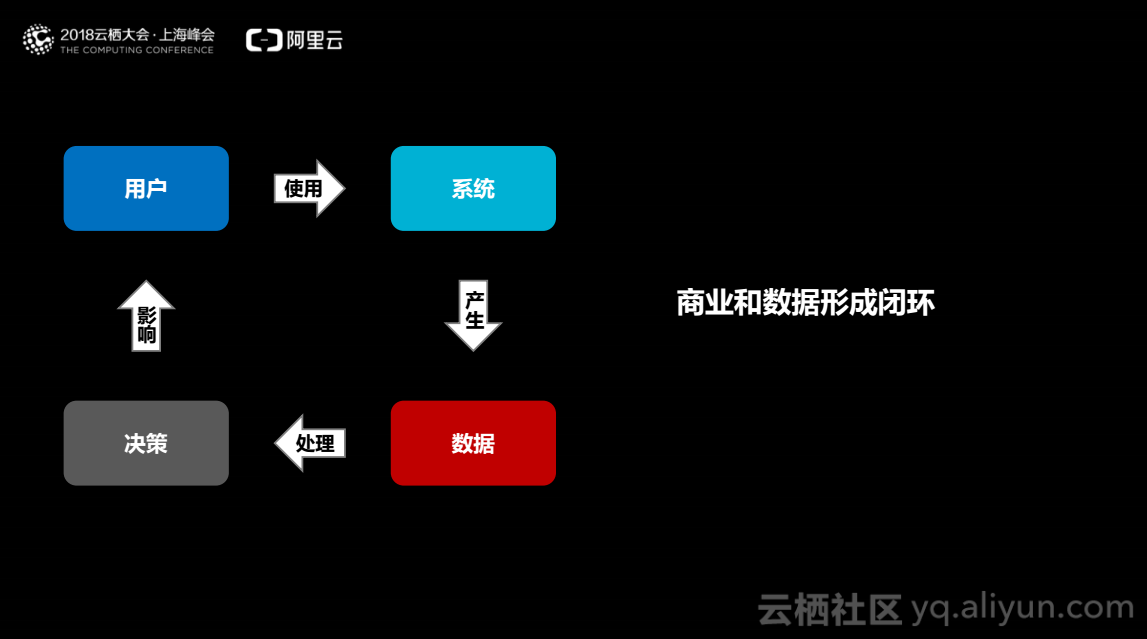
随着DT(数据处理技术)时代的到来,数据作为生产资料包含用户的需求,通过分析数据、挖掘用户需求同时满足用户需求,可以产生一定商业价值,因此商业和数据之间可以产生闭环。
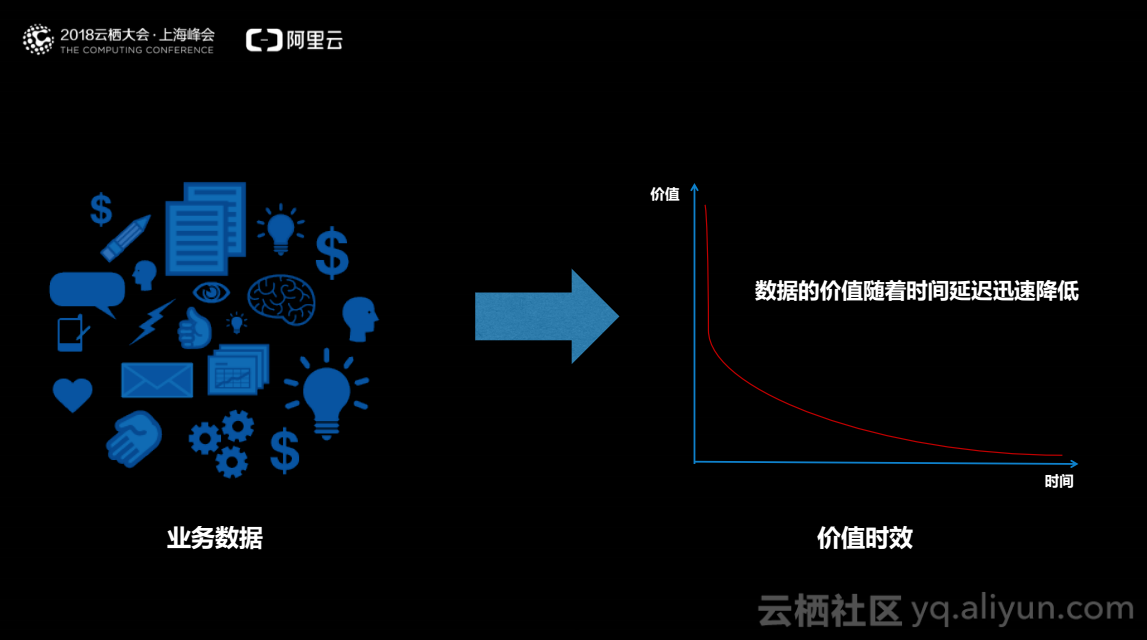
流计算秉持数据价值会随时间延迟而迅速跌落的基本观念,例如实时推荐、异常或欺诈检测和实时的报表。实时推荐中,要求在用户进行点击时,系统感知用户目前感兴趣的东西,从内容库中查找对应用户感兴趣的内容并推送给用户,从而使用户可以实时发现自己感兴趣的东西,延长用户活跃时间。相反当用户访问离线的推荐系统时,即使拥有较高准确率的算法,用户的兴趣也可能会随着时间的推移而发生改变。在实时异常和欺诈检测中,以电商系统为例,系统需要实时地监控用户的行为判断该用户是否为羊毛党,如果该系统为批处理系统,当发现问题时系统交易可能已经完成,追回损失成为困难。
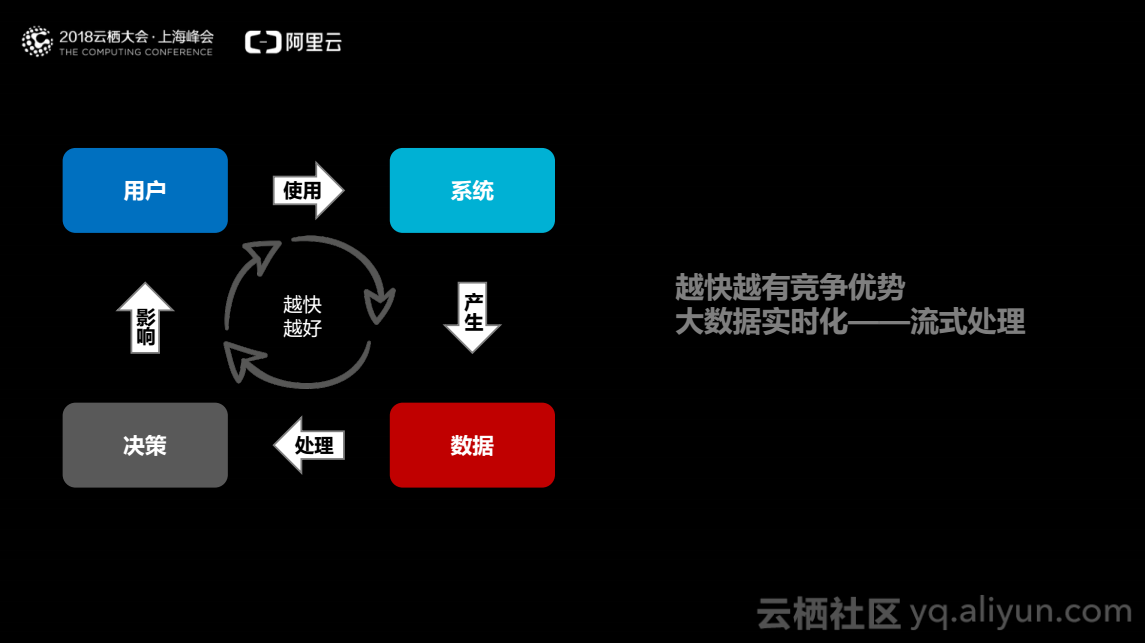
基于以上两个方面,数据的闭环工作应该进行得越快越好,越快找到用户的需求并满足用户的需求,就能获取更好的商业竞争力。因此大数据的实时化成为一种需求,实时化需求的解决方案就是流式处理系统。
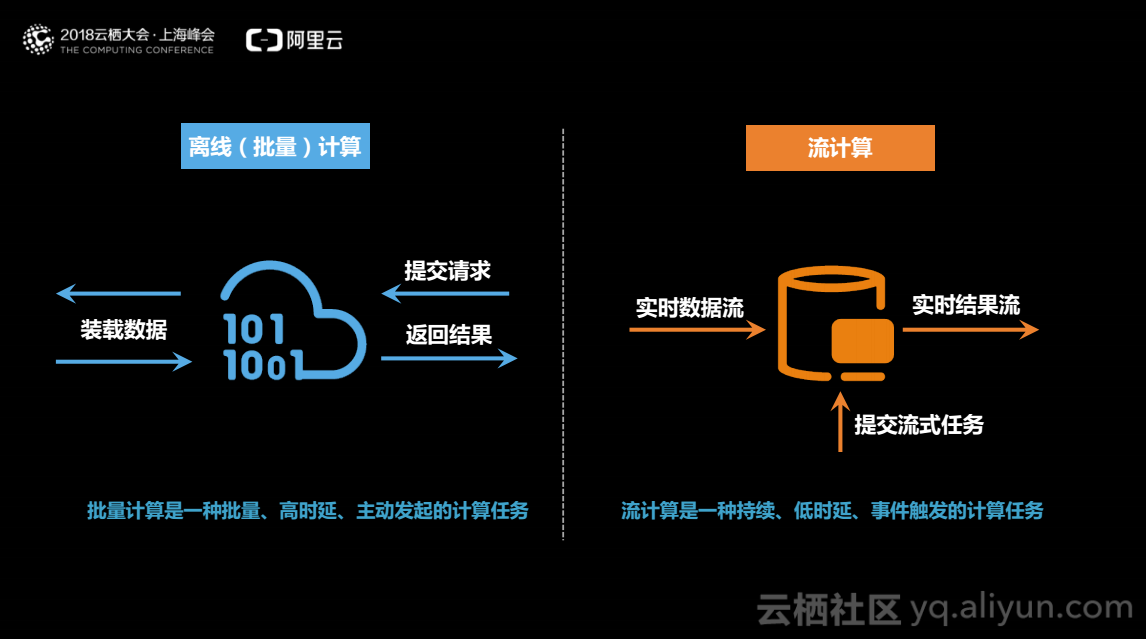
批处理系统中,用户将作业提交给系统,系统读取数据、计算、返回结果后作业停止。批处理系统具有比较大的延迟,表现为两个方面:
1)
每次计算都要计算所有的数据,产生较长的计算耗时。
2)
由提交作业驱动,提交作业和事件发生之间具有延迟。
流式处理系统中,用户提交作业后,作业会在内存中常驻,只要有数据过来就会触发计算,产生实时的结果流。流式处理系统做到实时性表现为两个方面:
1)
每次计算只计算一个增量,计算耗时短。
2)
由事件触发,事件到达即刻进行计算。
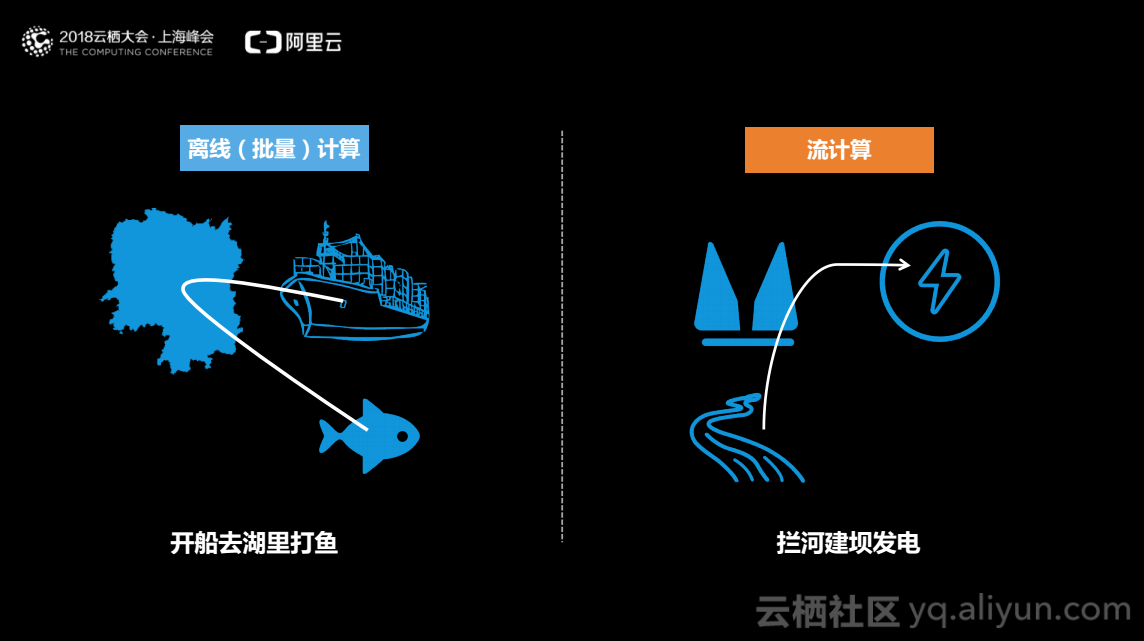
在批处理中,数据相当于一个湖,无论湖有多大都是静态的,离线(批量)计算相当于开船去湖中捕鱼,将计算贴近数据从而获取想要的结果。在流计算中,数据相当于一条河,河流不停地在流动,流计算相当于在河边修水坝,数据流过时获取想要的结果相当于电。基于以上例子,批量计算和流计算的区别在于:
1)
批量计算中数据是静态的,流计算中数据是动态的,表现为湖与河的区别。
2)
批量计算是将船开到湖中,自己寻找数据,流计算是在河边建坝,等待数据传入。
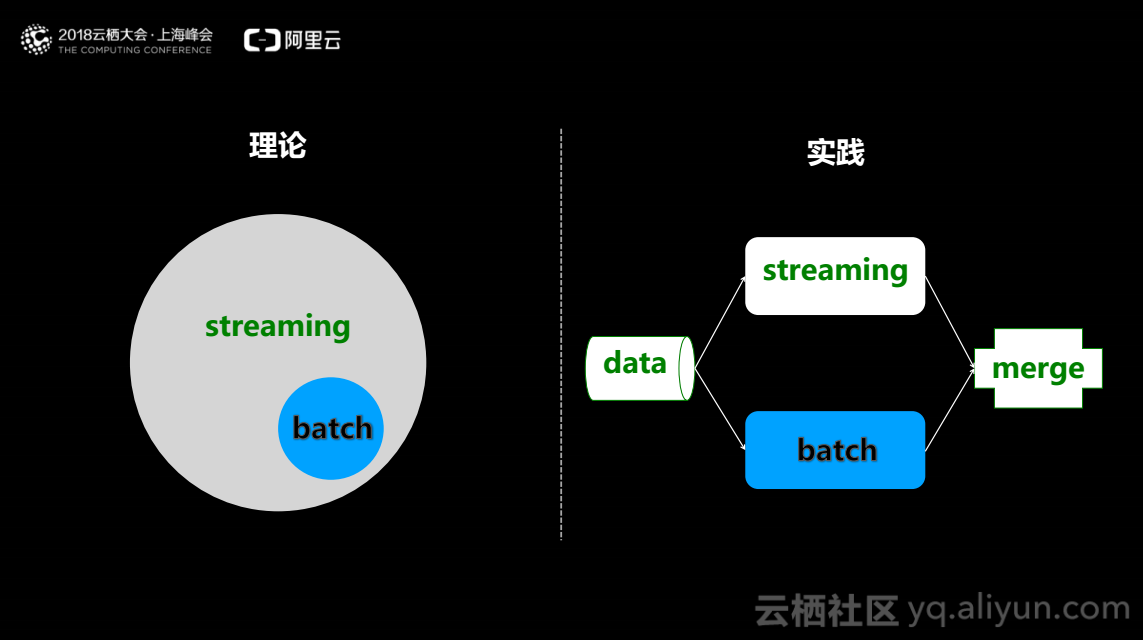
批处理是处理有限的数据,流处理是处理无限的数据。将有限作为无限的特例,具体来说,在流式处理中将窗口设置成批处理一样的大小,从而获取和批处理一样的结果。然而在实践中,人们会把两个系统分开,实时的部分采用流式系统,离线的部分采用批处理系统。采用以上架构有两点原因:
1)
由于大数据通过Spark等发展起来,本身采用离线的处理系统,批处理系统占据了公司的大部分业务,具有一定的先发优势。
2)
从工程上来讲,批处理是流处理的特殊场景,批处理系统在特殊的场景中可以进行特殊的优化。例如批处理系统不用考虑流计算窗口上的容错,在设计内部数据结构或查询优化时,可以假设数据是有限的,因此在批处理特殊场景下会有更好的性能,例如更高的吞吐量等。
二、 为什么要用阿里云流计算
阿里云流计算采用一站式、高性能、稳定、易用的流式大数据处理平台。下面从四个方面介绍阿里云流计算平台。
流式SQL
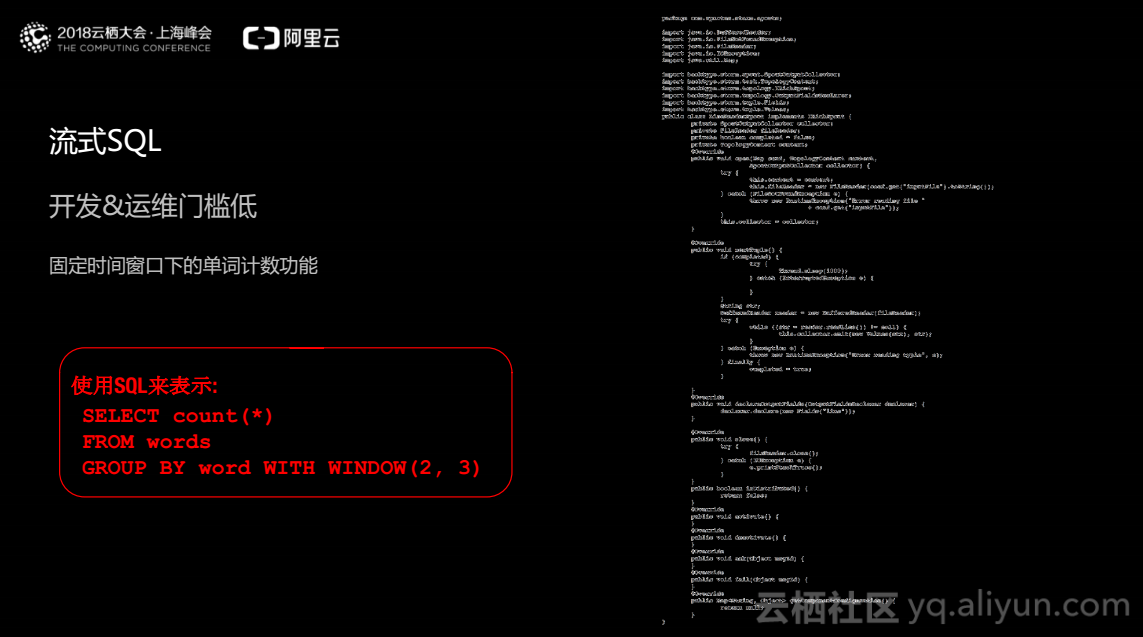
阿里云的流计算平台采用流式SQL语言,图中右侧为基于storm的固定时间窗口下的单词计数的java代码,左侧为实现相同功能的SQL代码,两者在代码量上差别巨大,SQL对生产力的提升有着非常大的帮助,同时SQL的编写较为简单,从而降低了使用者的门槛。
一站式平台
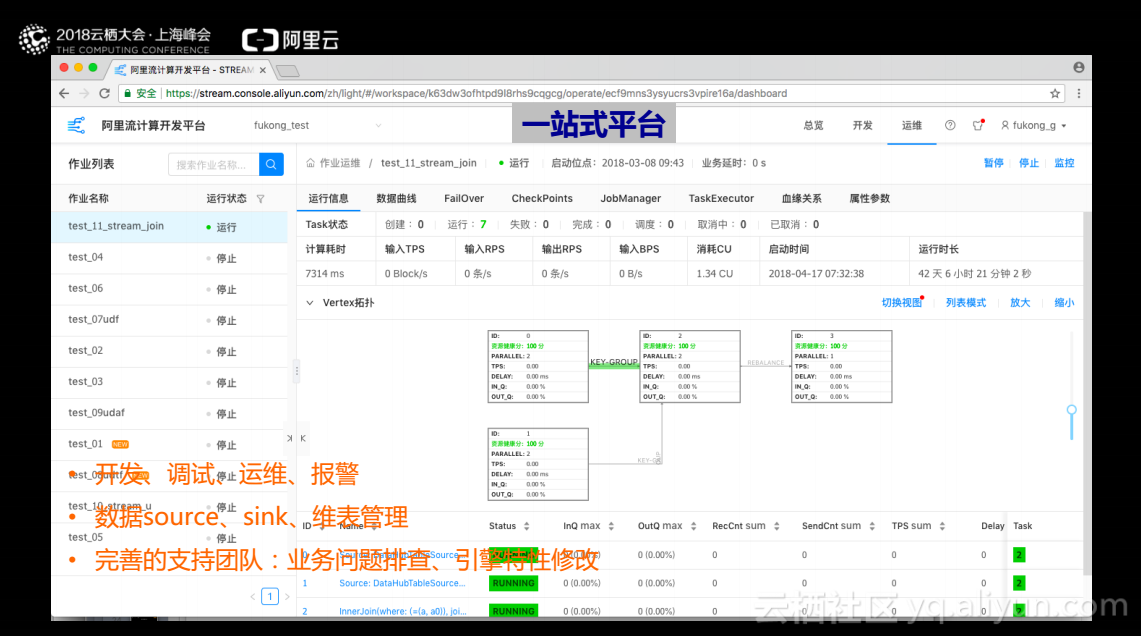
阿里云的一站式流计算平台相当于提供了一个web的IDE。流计算本身的开发、调试、运维和报警都可以在自己的平台中执行。流计算的上下游例如数据的存储、source、sink和中间的一些维表也可以通过自己的平台进行管理。该平台提供完善的支持,用户遇到的业务问题可以很快得到解决,同时支持团队根据用户合理的需求可以进行功能上的扩展开发。
数据生态
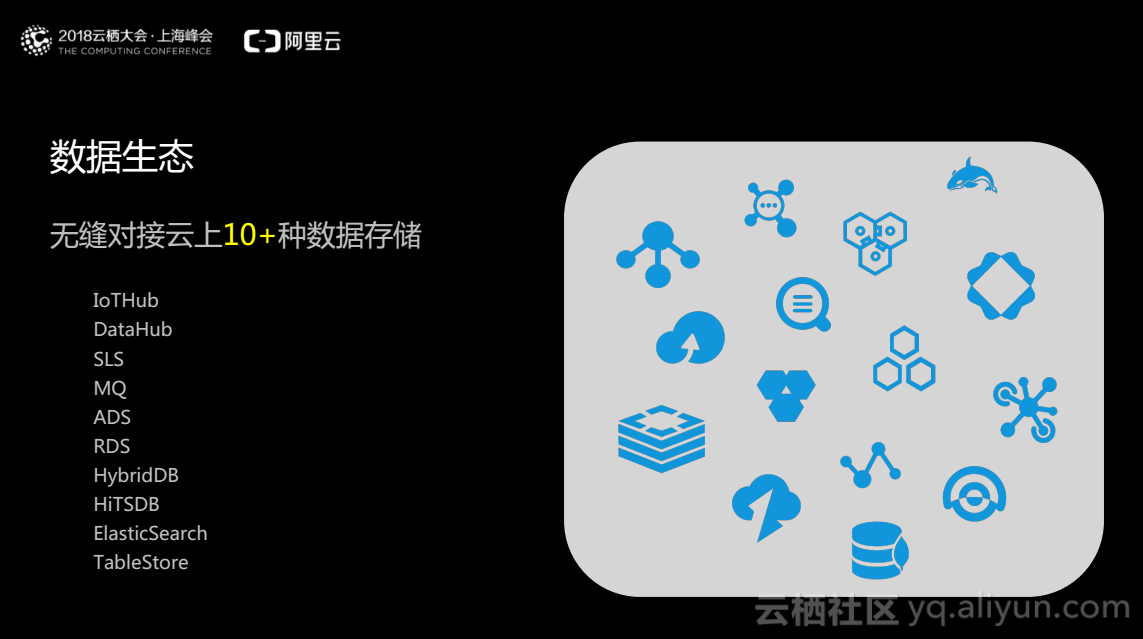
阿里云的流计算平台无缝对接阿里云上的十多种数据存储,所谓无缝对接,是指用户不需要进行数据迁移,用户注册后可以直接使用原来地方存储的数据,表现为一键式的流式大数据环境构建的处理系统。
Blink

阿里云的流计算平台采用Blink作为底层引擎。Blink可以认为是开源引擎Flink的企业版。阿里巴巴在底层引擎方面进行了很多优化,包括二级调度、增量checkpoint和异步IO等,在关键部分上有着10倍的性能提升。

上图展现Apache Storm、Spark Streaming和Flink的区别,Flink将Apache Storm和Spark Streaming在流处理上的优点进行了集合,窗口作为流计算非常重要的特性,Flink在窗口方面表现得更好,想要在流计算中处理有限的数据通常需要使用窗口,Flink支持比较完善的事件窗口、时间处理窗口和会话窗口。
三、 如何用流计算
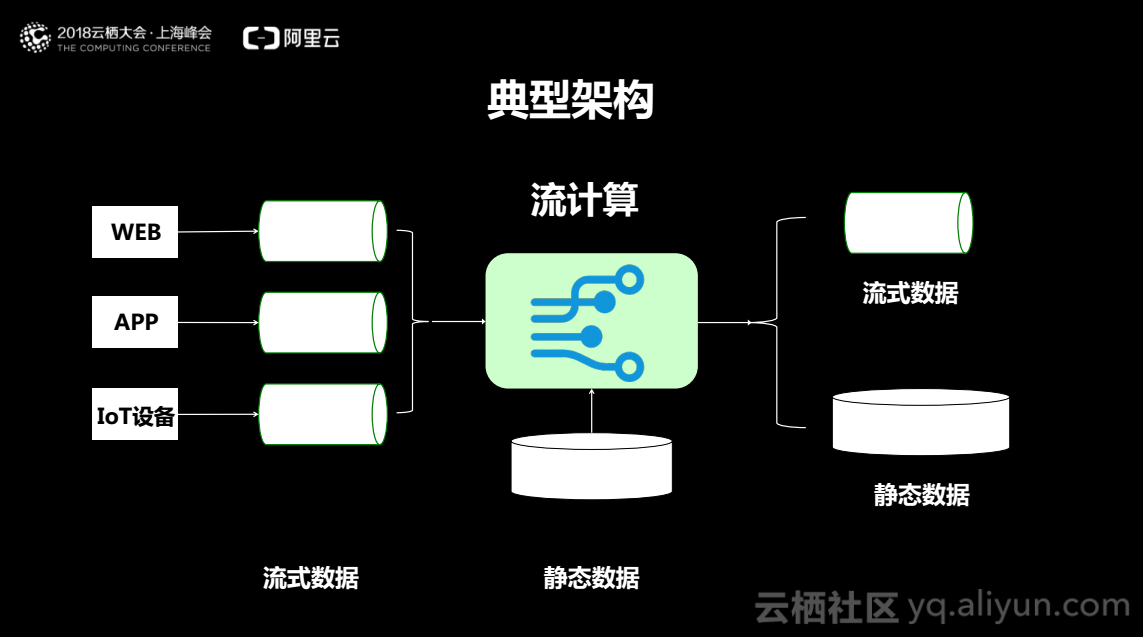
如图为流计算的典型架构,一般地当用户拥有一个web、app或者作为IoT的厂商时,日常中会实时地产生日志,这些日志本身是流式的,可以推送到消息队列的服务器中,然后流计算订阅这些消息,在这一过程中可以关联一些用户的静态数据,进而得到结果,结果可以为流式的例如同样为消息队列的日志,也可以为静态的例如流计算实时地更新用户写入的数据,使数据保持实时更新的状态。
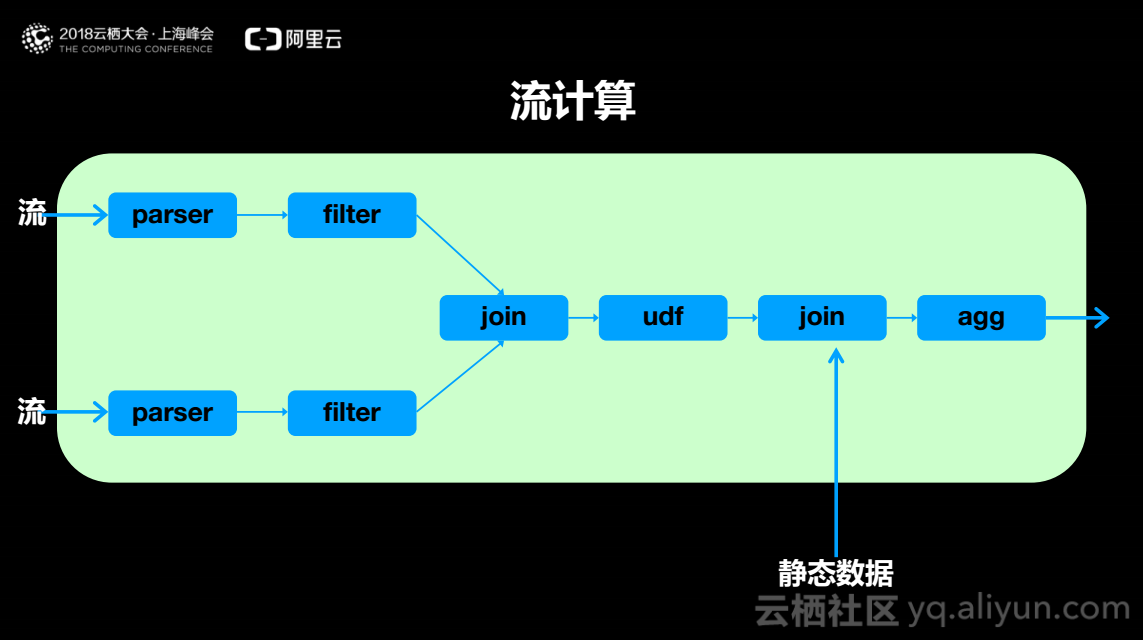
进一步来说,流计算可以对数据流进行解析和过滤,两个数据流可以进行join(结合),同时用户可以定义一些函数即udf,处理一些特殊的逻辑,在流计算的过程中可能会关联一些其它静态的数据,获取数据的一些属性,最终经过汇总和统计产生结果。
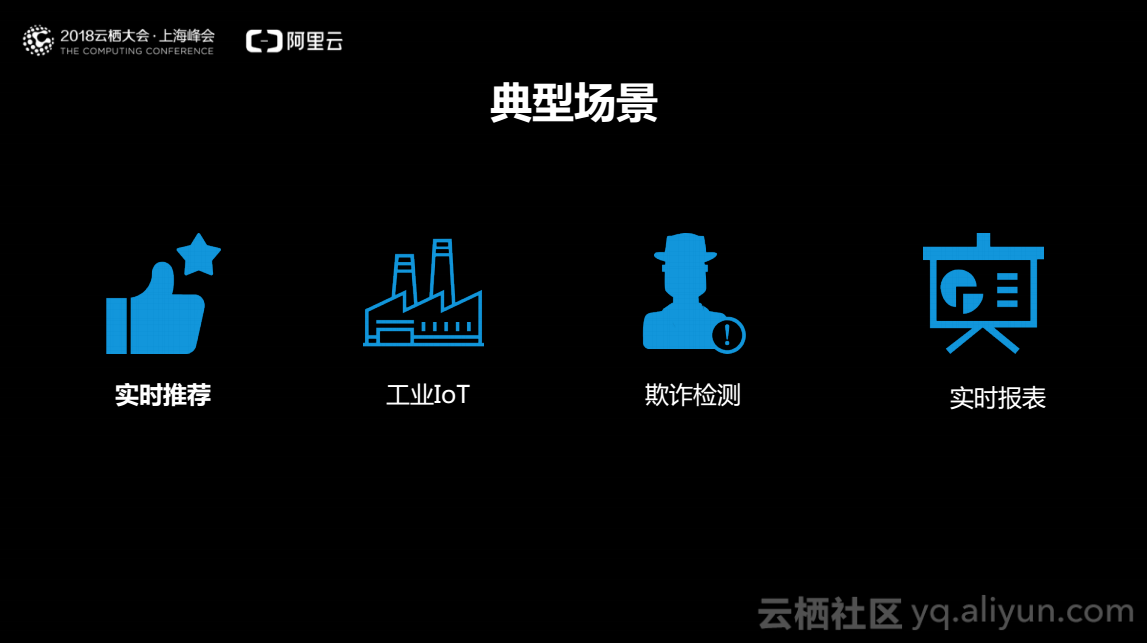
下面介绍流计算的典型应用场景包括实时推荐、工业IoT、欺诈检测和实时报表。
实时推荐
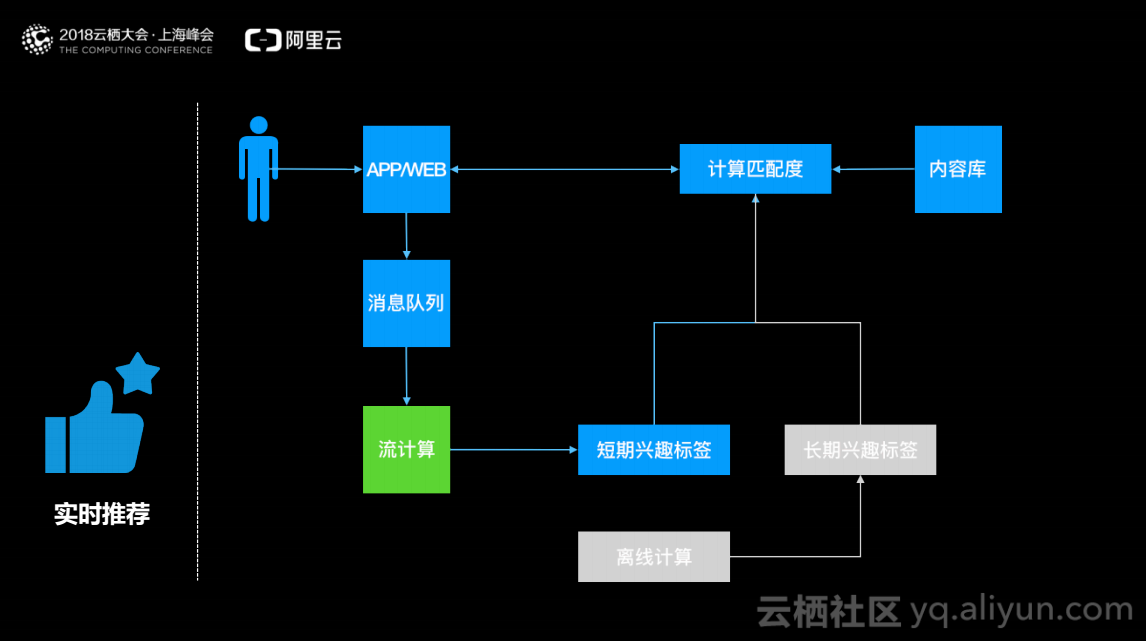
实时推荐中,系统获取用户画像,在内容数据库中进行相似度的匹配,找到与用户画像比较相近的内容推送给用户。为了解决实时性,将用户画像分为长期兴趣标签和短期兴趣标签两部分。长期兴趣标签指基本不太发生变化或者发生变化频率比较低的用户画像,例如用户的性别、年龄、地理位置、消费习惯等,由于长期兴趣标签对实时性要求不高,可以通过离线的方式进行更新。短期兴趣标签例如用户5分钟一直对汽车比较感兴趣,不断刷新汽车相关的网页。系统通过web或app记录用户的行为,发送到消息队列,流计算订阅消息队列实时地计算用户的短期兴趣标签,例如统计用户最近1分钟对所有类别的点击率,然后进行排序,获取点击率高的类别作为短期兴趣标签,经过内容匹配的搜索将结果返回给用户。
工业IoT
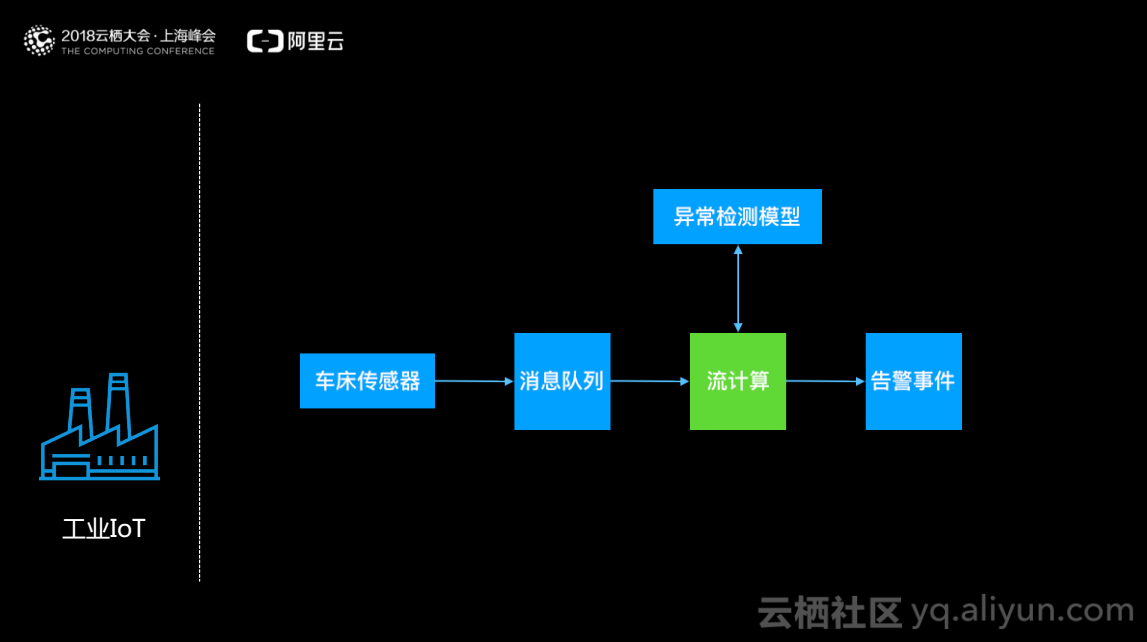
工业IoT中,相当于用户拥有一条生产线,想要获得生产线上实时的指标或者监控生产线上的良品率,防止产生更大的损失。在该数据流中,用户在车床上部署传感器实时地采集产品的特征,然后将特征的原始信息例如日志发送到消息队列服务器中,流计算订阅消息队列获取产品的原始数据计算产品的特征,通过udf调用产品合格率的检测模型进行判断,最后将结果个性化地展现给用户。
欺诈检测
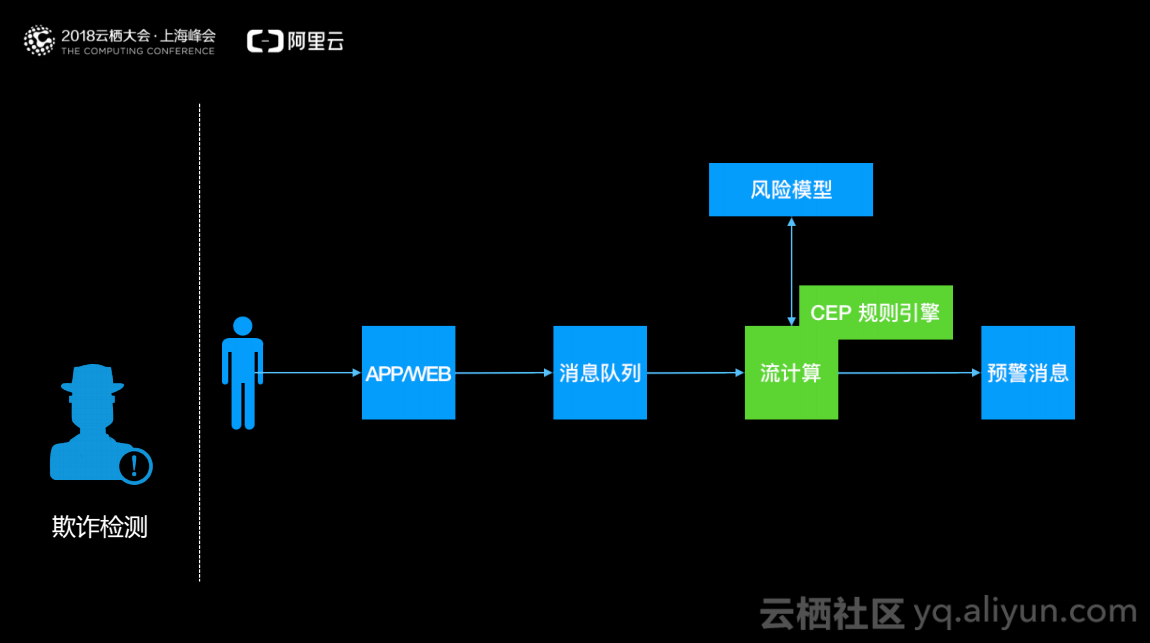
欺诈检测中,假设电商系统实时地监控用户的行为是否在薅羊毛,它的数据流类似于工业IoT,用户的行为通过日志发送到消息队列服务器,流计算实时地将用户行为特征化,然后调用风险模型对用户的行为进行一对一的判断。在这一过程中CEP规则引擎是流式系统中复杂的分析归类引擎,例如可以在CEP中定义用户先做了A,过了3分钟又做了B,之后做了3次C和1次D,将这些动作综合起来认为用户做了异常行为。综合CEP和风险模型可以实时地检测用户的行为是否有问题,进而发出报警避免更大的财产损失。
实时报表
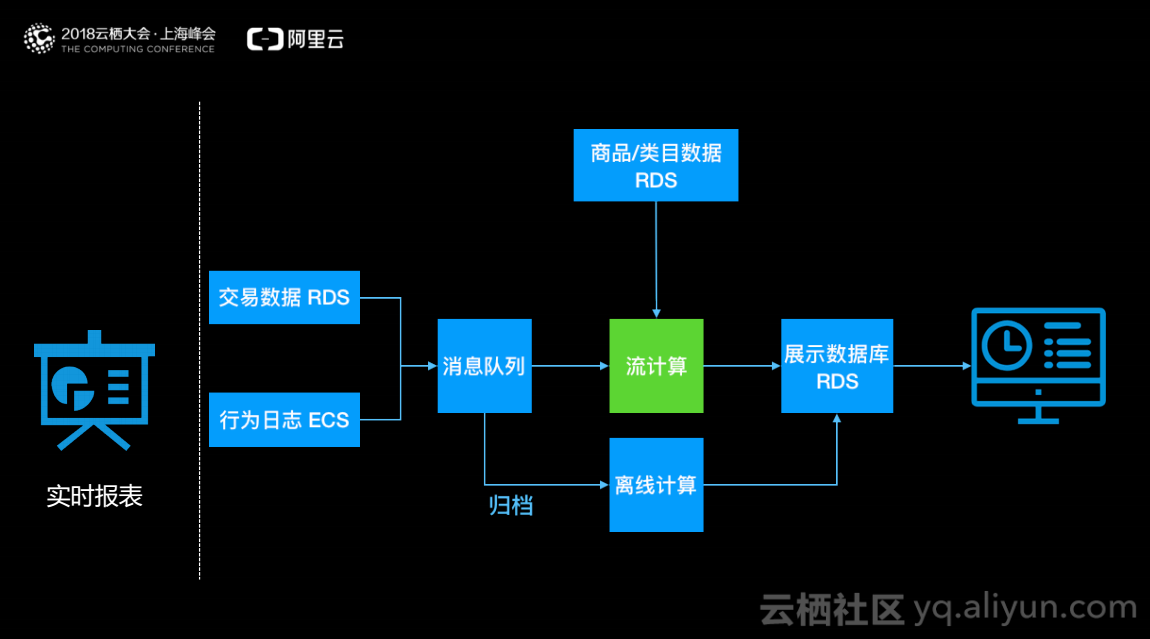
实时报表中,例如天猫的双十一大屏,将用户的交易数据和行为数据归组到消息队列中,消息队列读取数据关联到商品的属性,按照想要的维度进行统计,将结果存储在RDS中,展示系统读取RDS的内容进行结果展示。实时报表不仅仅只有展示作用,同时会产生一定的业务价值。

流计算应用的典型案例中,天猫双十一大屏的TPS(系统吞吐量)峰值是过硬的,每秒可以处理几亿条事务,从用户下单到数据汇总到大屏的整个全链路的延迟为3秒,同时拥有秒级别的流计算处理延迟。除了天猫,菜鸟和支付宝也在使用流计算进行实时的大数据处理,例如菜鸟通过流计算进行实时的仓库管理。流计算同时应用在城市大脑和工业大脑中,例如通过流计算进行实时地异常检测、实时地车辆检测、实时地监控、报表等。

如图所示除了阿里集团内部,阿里云流计算平台在公共云中已经拥有很多用户。实时化其实是一个非常横向的需求,覆盖行业范围广泛包括互联网、金融、IoT、国企和政府等。具有实时化大数据处理需求的用户都可以免费体验一个月的阿里云流计算平台服务,同时在试用的过程中会有专业人员进行辅导。

阿里云流计算平台在最近添加了一些新功能,包括独享集群、Datalake ETL和CEP。独享集群6月7日正式开始邀测,独享集群相对于公共云上的共享集群,在共享集群中所有的用户共享同一个集群,在独享集群中每个用户使用自己的集群,独享集群更加开放,用户可以定义很多的udf,网络与VPC的互通变得更加便捷,同时独享集群支持非常多的底层硬件例如GPU、FPGA等,可以实时地处理图像和视频。在Datalake ETL中用户可以进行数据的清洗、同步、分析等。CEP是在流式系统中进行复杂规则匹配的工具,集成于SQL,通过SQL定义复杂的模式进行匹配。
DT时代,数据是新能源,流计算让业务实时,让数据发电!
本文由云栖志愿小组丁匀泰整理