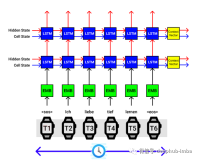
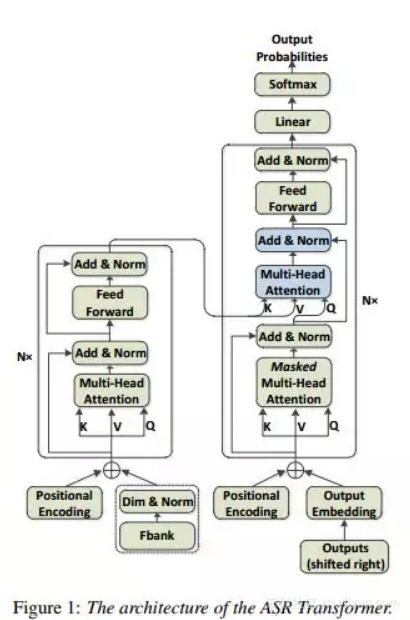
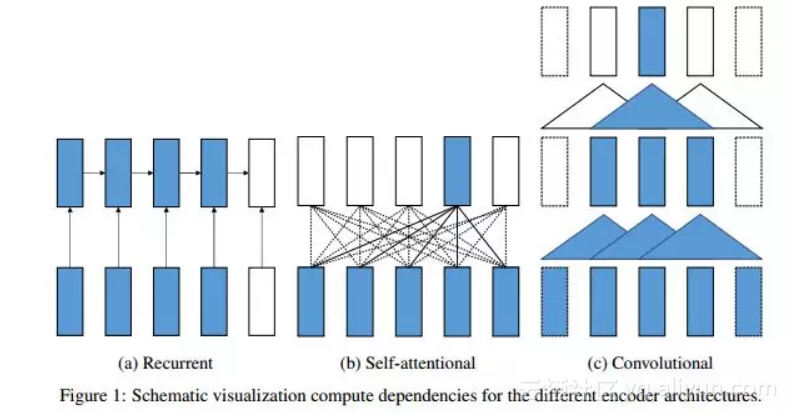
10. 普通话中基于音节的序列 - 序列语音识别的基于音节的序列 - 序列语音识别
作者:周世宇,林浩东,许旭,许波
由INTERSPEECH2018接受
机构:中国科学院大学
摘要:基于序列注意的模型最近在自动语音识别(ASR)任务中显示出非常有希望的结果,该任务将声学,发音和语言模型集成到单个神经网络中。在这些模型中,Transformer是一种新型的基于序列到序列注意的模型,完全依赖于自我注意而不使用RNN或卷积,从而实现了一种新的单模型最先进的神经机器翻译BLEU(NMT ) 任务。自从Transformer的出色表现以来,我们将其扩展到语音,并将其作为中文普通话ASR任务中从序列到序列注意模型的基本架构。此外,我们调查了基于音节的模型和基于上下文无关音素(CI音素)的模型与Transformer在汉语中的比较。另外,提出了一种具有Transformer的贪心级联解码器,用于将CI音素序列和音节序列映射为单词序列。对HKUST数据集的实验表明,基于音节的Transformer模型比基于CI音素的模型表现更好,并且实现了\ emph {$ 28.77 \%$}的字符错误率(CER),这对于状态 - 基于联合CTC注意力的编码器 - 解码器网络的$ 28.0 \%$-CER。
期刊:arXiv,2018年6月4日
网址:
http://www.zhuanzhi.ai/document/0637b1a811b59874909de6270c73a5bb
11. Sockeye:神经机器翻译工具包(Sockeye:用于神经机器翻译的工具箱)
作者:Felix Hieber,Tobias Domhan,Michael Denkowski,David Vilar,Artem Sokolov,Ann Clifton,Matt Post
摘要:我们描述了Sockeye(版本1.12),这是一种用于神经机器翻译(NMT)的开源序列到序列工具包。Sockeye是一个用于培训和应用模型的生产就绪框架,也是研究人员的实验平台。用Python编写并构建于MXNet上,该工具包为三种最突出的编码器 - 解码器架构提供了可扩展的培训和推理:注意力递归神经网络,自我注意变换器和完全卷积网络。Sockeye还支持广泛的优化器,规范化和正则化技术,并从当前的NMT文献中推断改进。用户可以轻松运行标准培训食谱,探索不同的模型设置,并纳入新的想法。在本文中,我们重点介绍Sockeye' 并在2017年机器翻译会议(WMT)的两种语言弧上针对其他NMT工具包进行基准测试:英语德语和拉脱维亚语 - 英语。我们报告了所有三种体系结构的竞争性BLEU分数,包括Sockeye变压器实施的总体最佳分数。为了便于进一步比较,我们发布了我们实验中使用的所有系统输出和培训脚本。Sockeye工具箱是基于Apache 2.0许可证发布的免费软件。
期刊:arXiv,2018年6月1日
网址:
http://www.zhuanzhi.ai/document/7ee4491f760e5bcdb1a0fe2c56b54653
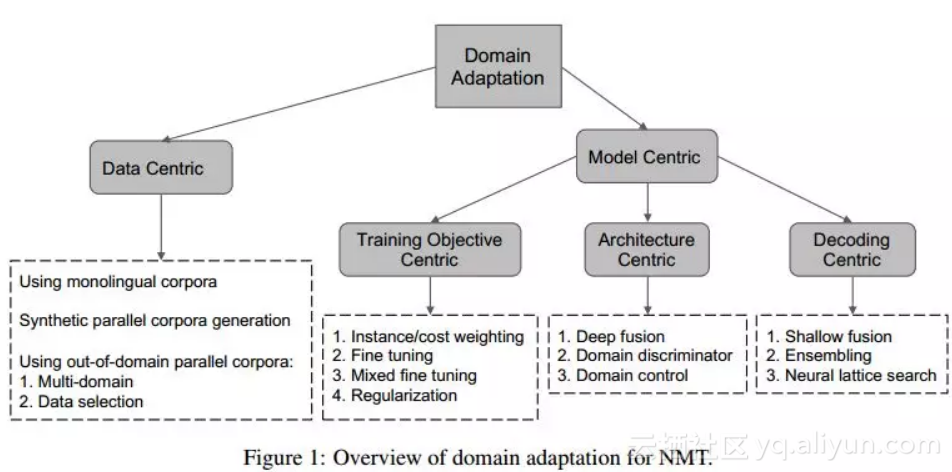
12. “ 神经机器翻译域自适应的综述”的域调整调查
作者:陈会辉王瑞
COLING 2018
机构:大阪大学
摘要:神经机器翻译(NMT)是一种基于深度学习的机器翻译方法,它可以在大规模平行语料库可用的场景下获得最先进的翻译性能。尽管高质量和特定领域的翻译在现实世界中至关重要,但特定领域的语料库通常是稀缺的或不存在的,因此在这种情况下,香草NMT表现不佳。利用域外平行语料库和单语语料库进行域内翻译的域自适应对于域特定翻译非常重要。在本文中,我们对NMT的最先进的领域适应技术进行了全面的调查。
期刊:arXiv,2018年6月1日
网址:
http://www.zhuanzhi.ai/document/2fcc4b9db4faa4c2d65235969c5e2a00
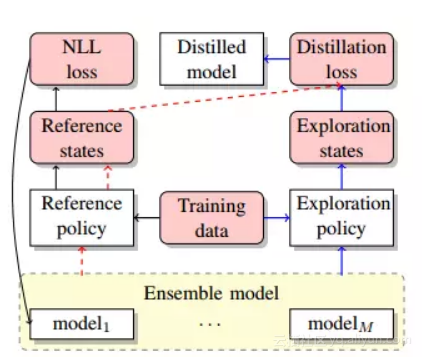
13. 基于 搜索的结构化预测抽取知识(提炼基于搜索的结构化预测的知识)
作者:刘义佳,车万祥,赵怀鹏,秦兵,刘挺
出现在ACL 2018
摘要:许多自然语言处理任务可以建模为结构化预测,并作为搜索问题解决。在本文中,我们将用不同初始化训练的多个模型集成到一个模型中。除了学习在参考状态上匹配集合的概率输出之外,我们还使用集合来探索搜索空间并从勘探中遇到的状态中学习。在两个典型的基于搜索的结构化预测任务 - 基于转换的依赖分析和神经机器翻译的实验结果表明,蒸馏可以有效地提高单个模型的性能,最终模型在LAS和2中实现1.32的改进。
期刊:arXiv,2018年5月29日
网址:
http://www.zhuanzhi.ai/document/4432c8f9db5de053b6936c5ca7738c6e
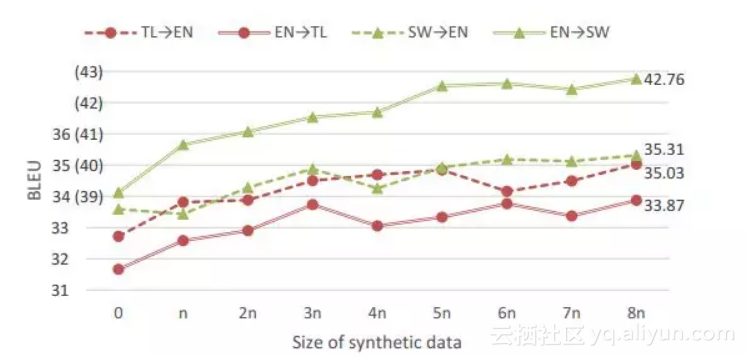
14. 双向神经机器翻译与合成并行数据(Biotropy Neural Machine Translation with Synthetic Parallel Data )
作者:Xing Niu,Michael Denkowski,Marine Carpuat
在第二届神经机器翻译和生成研讨会上被接受(WNMT 2018)
机构:马里兰大学
摘要:尽管在资源丰富的环境中取得了令人瞩目的进步,但神经机器翻译(NMT)仍然在低资源和域外情况下挣扎,往往无法与短语翻译的质量相匹配。我们提出了一种新技术,结合了回译和多语种NMT,以提高这些困难情况下的表现。我们的技术针对语言对的两个方向训练单一模型,使我们能够在不需要辅助模型的情况下回溯源或目标单语数据。然后,我们继续对增强后的并行数据进行培训,为可以结合任何源,目标或并行数据的单个模型实现一个改进循环,以改善两种翻译方向。作为副产品,与单向模型相比,这些模型可显着降低培训和部署成本。
期刊:arXiv,2018年5月29日
网址:
http://www.zhuanzhi.ai/document/06afeb45d9fc334f67848252ff512a0d
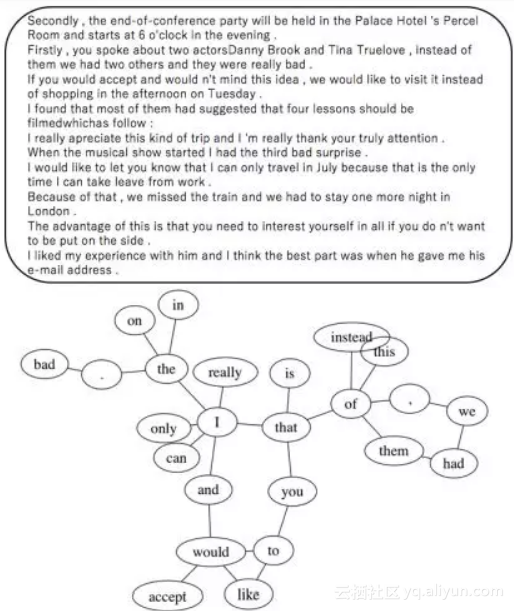
15. 编码器 - 解码器模型的基于图表的词外单词过滤(基于图的编码 - 解码模型用于词汇表外单词过滤)
作者:Satoru Katsumata,Yukio Matsumura,Hayahide Yamagishi,Mamoru Komachi
2018年ACL学生研究工作坊
机构:东京都立大学
摘要:编码器 - 解码器模型通常只使用训练语料库中经常使用的词来降低计算成本并排除噪声。但是,这个词汇集可能仍然包含干扰编码器 - 解码器模型中的学习的词汇。本文提出了一种通过不仅利用频率而且利用HITS算法捕获的同现信息来选择更适合学习编码器的单词的方法。我们将我们提出的方法应用于两项任务:机器翻译和语法错误修正。对于日语到英语的翻译,此方法的BLEU分数比基线高0.56分。它也优于英语语法错误修正的基准方法,F0.5-测量值高出1.48点。
期刊:arXiv,2018年5月29日
网址:
http://www.zhuanzhi.ai/document/6cfea9920eb3b1dcb5bebb3bcf6b5534
16. 用神经机器翻译来引导文法(用于神经机器翻译的归纳语法)
作者:Ke Tran,Yonatan Bisk
在NMT研讨会上接受(WNMT 2018)
机构:华盛顿大学阿姆斯特丹大学
摘要:机器翻译系统需要语义知识和语法理解。神经机器翻译(NMT)系统通常假定这些信息被确保流畅性的注意机制和解码器所捕获。最近的工作表明,结合显式语法减轻了对两类知识建模的负担。但是,要求解析是昂贵的,并且不会探讨模型在翻译过程中需要什么语法的问题。为了解决这两个问题,我们引入了一个模型,该模型在诱导依赖树的同时进行翻译。通过这种方式,我们可以利用结构的好处,同时调查NMT必须引发的语法以最大限度地提高性能。我们显示我们的依赖树是1.语言对依赖和2.提高翻译质量。
期刊:arXiv,2018年5月28日
网址:
http://www.zhuanzhi.ai/document/c9a3205a7c29820bbc408e01dd0c967a
17. 一种用于神经机器翻译的随机解码器(神经机器翻译的随机解码器)
作者:菲利普舒尔茨,威尔克阿齐兹,特雷弗科恩
接受ACL 2018
机构:墨尔本大学阿姆斯特丹大学
摘要:钍翻译电子过程是模糊的,因为有一个给定的句子通常许多有效的反式办法第十四。这导致了平行相位的显着变化,然而,目前大多数机器翻译模型没有考虑这种变化,而是将问题视为确定性过程。为此,我们提出了一个机器翻译的深层生成模型,其中包含一系列潜在变量,以便考虑并行语料库中的局部词汇和句法变化。我们对训练深度生成模型的变分推理中遇到的陷阱进行了深入分析。对几个不同语言对的实验表明,该模型在强基线上一直得到改进。
期刊:arXiv,2018年5月28日
网址:
http://www.zhuanzhi.ai/document/a965bbe38aa4ebeda78d17196e0afd71
18. 基于递归神经网络的英日机器翻译预排序(基于递归神经网络的英日机器翻译预处理)
作者:Yuki Kawara,Chenhui Chu,Yuki Arase
ACL-SRW 2018
机构:大阪大学
摘要:源语言与目标语言之间的词序严重影响机器翻译的翻译质量。预先排序可以有效解决这个问题。先前的预先排序方法需要手动特征设计,使得语言相关的设计成本高昂。在本文中,我们提出了一个预先递归神经网络的方法,可以从原始输入中学习特征。实验表明,所提出的方法在翻译质量方面达到了可比较的水平,达到了最先进的方法,但没有手动特征设计。
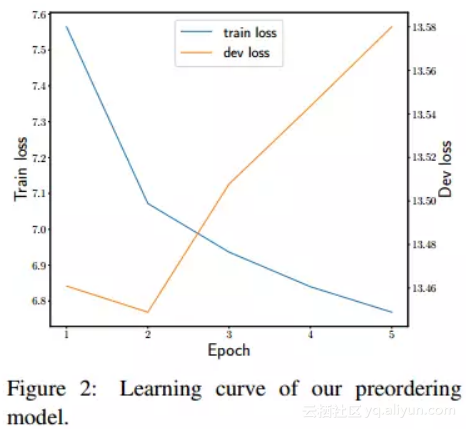
期刊:arXiv,2018年5月25日
网址:
http://www.zhuanzhi.ai/document/47872f75ac6c27428ed637fbd32ddb06
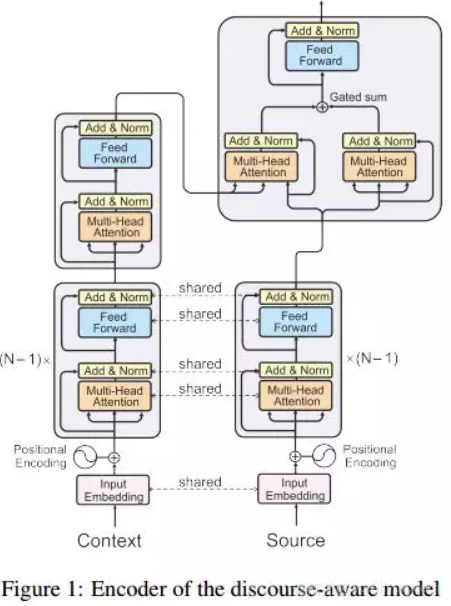
19. Context-Aware Neural Machine Translation Learns Anaphora Resolution (上下文感知神经机器翻译学习回指解析)
作者:Elena Voita,Pavel Serdyukov,Rico Sennrich,Ivan Titov
ACL 2018
机构:爱丁堡大学阿姆斯特丹大学
摘要:标准机器翻译系统单独处理句子,因此忽略超额信息,即使扩展的上下文既可以防止模糊情况下的错误,也可以提高翻译的一致性。我们引入了一种上下文感知的神经机器翻译模型,它可以控制和分析从扩展上下文到翻译模型的信息流。我们尝试了一个英文 - 俄文字幕数据集,并观察到我们的模型所捕获的大部分内容涉及改进代词翻译。我们测量引起的注意分布和共因关系之间的对应关系,并观察模型隐含捕获照应。这与代词在翻译中需要性别化的句子的收益是一致的。除了照应案件的改进之外,