想不到我和MongoDB的第一次亲密接触竟然是这样开始的。

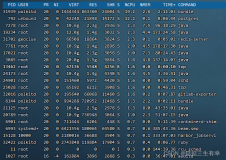
当我对公司的一个内部系统性能无可忍受时,意外发现在这个内存仅为 32G 的服务器上,运行着一个 MongoDB 数据库,其主进程 mongod 占用了 30.705 G的虚拟内存空间。这立刻引起了我的兴趣,必须要研究一下其工作原理。
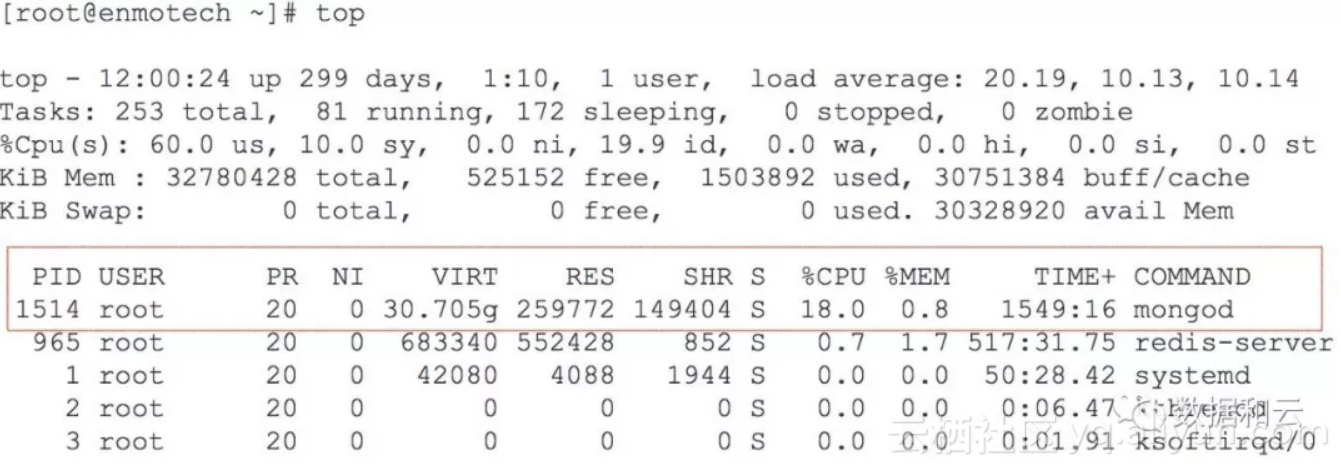
这个数据库的版本是 3.0 :
[root@enmotech bin]# ./mongod --version
db version v3.0.12
那么,为什么 MongoDB 会消耗这么多内存呢?
通过数据库的状态查询,可以看到同样内存分配情况,Resident的固有内存分配了254M,Virtual的虚拟内存分配了 31,441M:
> db.serverStatus().mem;
{
"bits" : 64,
"resident" : 254,
"virtual" : 31441,
"supported" : true,
"mapped" : 15498,
"mappedWithJournal" : 30996
}
再看一下存储引擎,当前数据库使用的存储引擎是 mmapv1 :
> db.serverStatus().storageEngine;
{ "name" : "mmapv1" }
MMAPv1 实际上就是 MongoDB 在 3.0 以前原有的存储引擎,在 3.0 版本它也继续作为 MongoDB 的默认存储引擎,而在 MongoDB 3.2 版本默认存储引擎已经改为 WiredTiger。
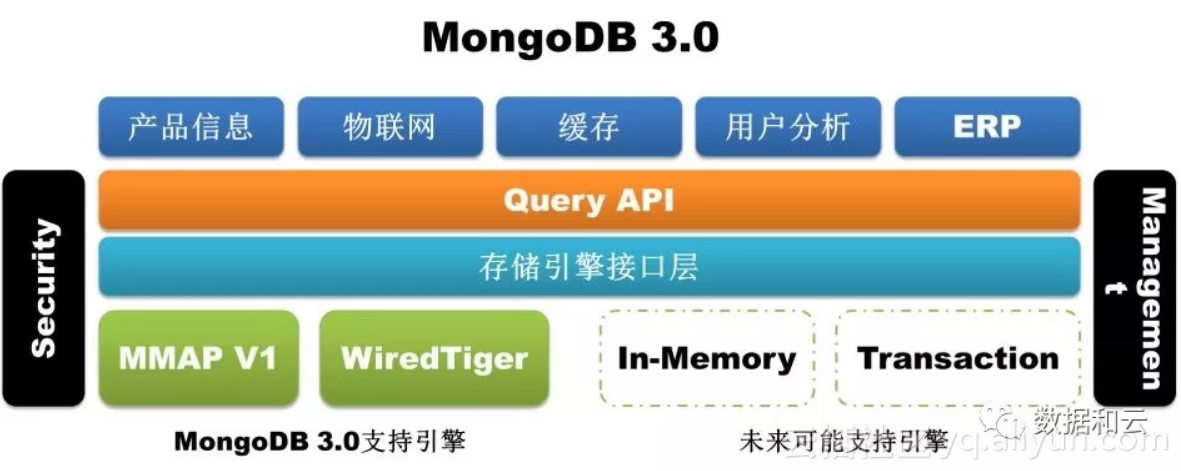
这个变化,就类似MySQL的存储引擎从 MyISAM 变化到 InnoDB 一样,性能是关键。在 3.0 版本之前,MMAPv1 对锁请求的做法是,以 Database 为单位加锁, 3.0 版本,MMAPv1 则开始使用以 Collection 为单位的加锁(collection-wise locking)。但是这仍然不够,WiredTiger 使用的实际为 Document 级的乐观锁机制,最终替代了 MMAPv1 .
这其中的主要原因是 2014 年 12 月,MongoDB 收购了 WiredTiger 公司,WiredTiger 为 MongoDB 3.0 开发了一个专用版本的存储引擎,我们不得不钦佩 MongoDB 的英明之处,想一想 MySQL 的历程,当 MySQL 的最佳存储引擎 InnoDB 被 Oracle 釜底抽薪收购(2006年)之后,MySQL 最后被 SUN 收购(2008年),辗转落入 Oracle 之手(2009年),当然自2009年 MySQL 5.5 开始 InnoDB 就成为了 MySQL 默认存储引擎。
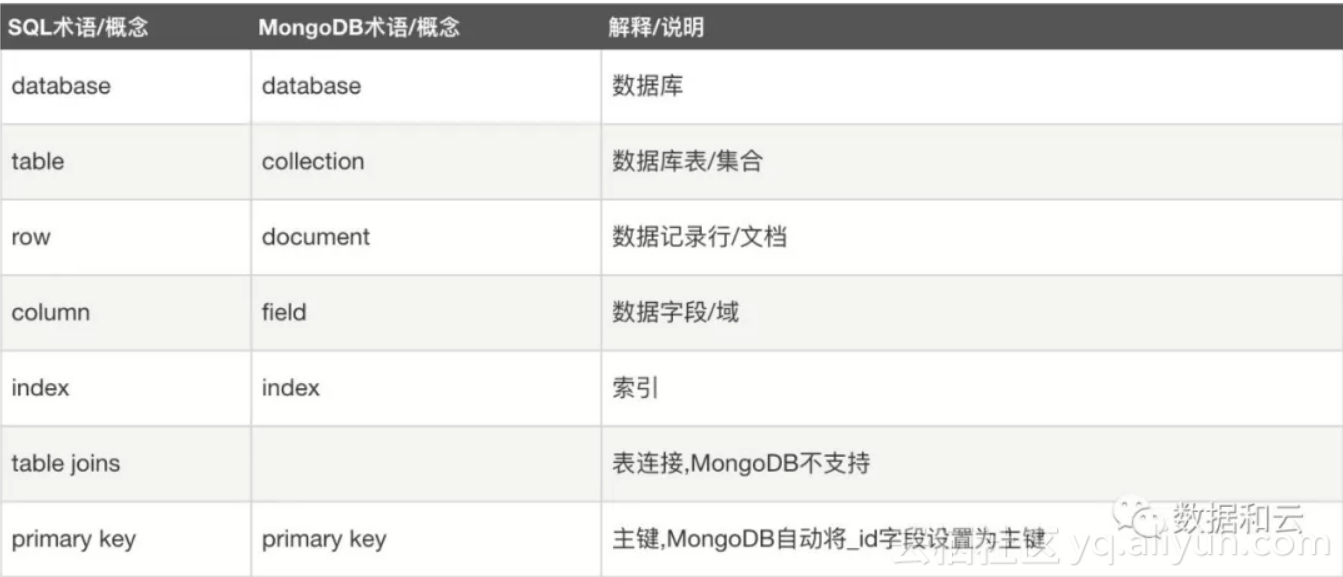
通过下图和关系型数据库的对比,我们更好理解MongoDB的概念,虽然从 Database 级别锁到 Collection 级别,但是仍然不够:
回过头来,MMAPv1之所以叫 MMAP,是因为这个存储引擎会把数据直接映射到虚拟内存上,即 “memory mapping”。由于MMAPv1使用mmap来将数据库文件映射到内存中,MongoDB总是尽可能的多吃内存,以映射更多的数据文件,并且页面的换入换出基本交给OS控制。
根据官方文档描述:
With MMAPv1, MongoDB automatically uses all free memory on the machine as its cache. System resource monitors show that MongoDB uses a lot of memory, but its usage is dynamic. If another process suddenly needs half the server’s RAM, MongoDB will yield cached memory to the other process.
使用MMAPv1,MongoDB会自动将机器上的所有可用内存用作缓存。
Technically, the operating system’s virtual memory subsystem manages MongoDB’s memory. This means that MongoDB will use as much free memory as it can, swapping to disk as needed. Deployments with enough memory to fit the application’s working data set in RAM will achieve the best performance.
从技术上讲,操作系统的虚拟内存子系统管理MongoDB的内存。 这意味着MongoDB将使用尽可能多的空闲内存,并根据需要交换到磁盘。 具有足够内存的部署可适应应用程序在RAM中的工作数据集,从而实现最佳性能。
MongoDB 采用mmap将数据文件映射到内存,同时带来的好处是,当MongoDB重启时,这些映射的内存并不会清除,相对于其它自己维护Cache的数据库,MongoDB在重启后并不需要进行缓存重建与预热。
[root@enmotech mongodb]# bin/mongod -f mongod.conf
about to fork child process, waiting until server is ready for connections.
forked process: 31489
child process started successfully, parent exiting
[root@enmotech mongodb]# top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
31489 root 20 0 30.610g 163112 132612 S 0.7 0.5 0:01.65 mongod
那么在 MMAPv1 存储引擎下,数据库是怎么组织的呢?到底这个数据库占用了多少空间呢?
每个 Database 由一个 .ns文件 及若干个数据文件组成,以下这个示范数据库,只有一个数据文件,大小是 64M:
[root@enmotech data]# ls -l en*
-rw------- 1 root root 67108864 May 31 09:36 enmotech.0
-rw------- 1 root root 16777216 May 31 09:36 enmotech.ns
如果空间继续扩展,MongoDB MMAPv1 引擎的扩展规则是,每次存储文件容量翻倍,直至增加到 2G 大小,下图是我们一个较大的数据库,其数据文件的扩展情况,可以清楚的看到从 64M、128M、256M、512M、1204M、2048M的扩展历程:
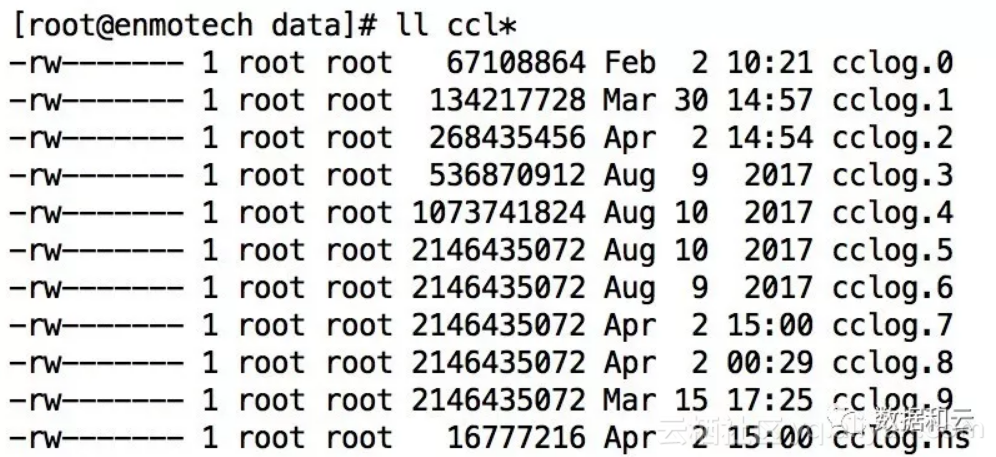
每个数据库中包含一系列的 collection ,.ns 文件事实上就用于记录不同 collection 的位置,相当于是元数据。那么如何实现快速的HASH查找呢?
在源码中可以看到非常详细的设计,『我们在这里用全零填充剩余空间,因为它们是确定性的对于给定的操作序列,它们具有的字节数。 这使得测试和调数据文件更容易。如果分析表明这种方法是一个重大瓶颈,我们可以有一个版本我们用于不填零的读取,并保持调零行为写入。』

不论如何,MMAPv1 存储引擎已经渐渐属于过去时,而在网上同样发现 Wiredtiger 存储引擎,缺省的同样会尽量使用更多的内存来缓存数据,很多朋友同样遇到内存耗尽的问题。
在MongoDB源码中(wiredtiger_init.cpp),有这样一段,说明了其使用Cache的方式。注释说明,当用户不未提供cache Size时,我们选择为系统和二进制文件保留 1GB 内存。在程序算法中,使用 memSizeMB - 1G 之后的 60% 作为缓存。

在 Wiredtiger 存储引擎下,合理的规划MongoDB的内存使用,可以通过参数设置 wiredTigerCacheSizeGB 来限制其使用的Cache大小。
以下是一个设置示范:
在经过分析之后,我想我需要更换存储引擎,从 MMAPv1 更换到 wiredTiger 上去了。由于 MongoDB 3.0.12 版本,本身就支持 wiredTiger 存储引擎,所以这一步不变更版本。
首先导出数据:
[root@enmotech mongodb-rhel-3.0.12]# ./bin/mongodump -h 127.0.0.1 --port 12088 -o mongbkp
17:36:41.150 writing enmo.UsOp to mongbkp/enmo/UsOp.bson
17:36:41.150 writing CU_ENMOTECH.MicroPost to mongbkp/CU_ENMOTECH/MicroPost.bson
。。。。
17:37:53.150 [######################..] enmo.UsOp 17657623/18819781 (93.8%)
17:37:56.151 [#######################.] enmo.UsOp 18593062/18819781 (98.8%)
17:37:56.854 writing enmo.UsOp metadata to mongbkp/enmo/UsOp.metadata.json
17:37:56.854 done dumping enmo.UsOp (18819781 documents)
设置新的参数文件,注意,我在 8888 端口启用了一个新的实例,隔离原数据库,防范问题,当升级完成之后,进行调整,应用再连接到这个新的数据库:
[root@enmotech mongodb-rhel-3.0.12]# cat moneygle.conf
port = 8888
bind_ip = 172.16.26.129
dbpath = eygle
logpath = logs/eygle.log
logappend = true
fork = true
storageEngine = wiredTiger
启动新的数据库:
[root@enmotech mongodb-rhel-3.0.12]# ./bin/mongod -f moneygle.conf
about to fork child process, waiting until server is ready for connections.
forked process: 13673
child process started successfully, parent exiting
执行数据恢复:
[root@enmotech mongodb-rhel-3.0.12]# ./bin/mongorestore -h 172.16.26.129 --port 8888 mongbkp
building a list of dbs and collections to restore from mongbkp dir
reading metadata file from mongbkp/enmo/UsOp.metadata.json
....
restoring indexes for collection cclog.UsOp from metadata
finished restoring cclog.UserOperationLog (18819781 documents)
done
完成存储引擎的更换,接下来我想把MongoDB升级到新版本3.6上来。
发现如果直接从3.0升级到3.6,会出现错误:
about to fork child process, waiting until server is ready for connections.
forked process: 16204
ERROR: child process failed, exited with error number 62
在日志中会记录明确的提示:
** IMPORTANT: UPGRADE PROBLEM:
The data files need to be fully upgraded to version 3.4
before attempting an upgrade to 3.6;
see http://dochub.mongodb.org/core/3.6-upgrade-fcv for more details.
也就是说,3.0 版本,要先升级到3.4,再升级到3.6。
这其中还有几个小步骤,首先从官方网站下载相应的版本,用 3.4 版本启动数据库,然后在 admin下执行必要的命令,将兼容性版本设置为3.4:
[root@enmotech mongodb-rhel-3.4.15]# ./bin/mongo 127.0.0.1:8888
MongoDB shell version v3.4.15
connecting to: mongodb://127.0.0.1:8888/test
MongoDB server version: 3.4.15
Server has startup warnings:
> use admin
switched to db admin
> db.adminCommand( { setFeatureCompatibilityVersion: "3.4" } )
{ "ok" : 1 }
> db.shutdownServer();
此时再用 3.6 版本的程序启动数据库,就一切正常了:
./bin/mongod --port 8888 -dbpath=./eygle/ -logpath=./logs/365.log --logappend --fork
about to fork child process, waiting until server is ready for connections.
forked process: 19098
child process started successfully, parent exiting
接下来修改兼容性版本,设置为3.6 ,现在我们已经拥有了一个 3.6 版本,使用 WireTiger 存储引擎的MongoDB数据库了。
[root@enmotech ]# ./mongodb-rhel-3.6.5/bin/mongo 127.0.0.1:8888
MongoDB shell version v3.6.5
connecting to: mongodb://127.0.0.1:8888/test
MongoDB server version: 3.6.5
Server has startup warnings:
> use admin
switched to db admin
> db.adminCommand( { setFeatureCompatibilityVersion: "3.6" } )
{ "ok" : 1 }
接下来修改兼容性版本,设置为3.6 ,现在我们已经拥有了一个 3.6 版本,使用 WireTiger 存储引擎的MongoDB数据库了。
在 WireTiger 网站上,至今还张挂着『We've Joined MongoDB!』的声明:
我们必须说,Oracle 的设计理念,在各种数据库中都可以看到类似的影子。比如 WireTiger 同样使用 『优先写日志 - Write-ahead Transaction Log 』原则。
这和 Oracle 的 Redo 日志原理相似,MongDB 在数据更新时,先将数据更新写入到日志文件,然后在 Checkpoint 操作开始时,将日志文件中记录的操作,刷新到数据文件。WiredTiger 日志文件会持续记录自上一次 Checkpoint 操作之后发生的所有数据变化,在 MongoDB 系统崩溃时,通过日志文件就能够还原从上次Checkpoint之后发生的数据更新。
以下是当前我的数据库中日志信息:
ls -l journal/
total 307200
Jun 14 17:15 WiredTigerLog.0000000087
Jun 14 17:10 WiredTigerPreplog.0000000001
Jun 14 17:10 WiredTigerPreplog.0000000002
Journal Files是存储在硬盘的日志文件,每个Journal File大约是100MB。
WiredTiger使用检查点在磁盘上提供一致性数据视图,并允许MongoDB从上一个检查点恢复。 但是,如果MongoDB在检查点之间意外退出,则需要使用日志记录来恢复上次检查点之后发生的信息。
通过日志记录,恢复过程:
查看数据文件以查找上一个检查点的标识符。
在日志文件中搜索与上一个检查点的标识符相匹配的记录。
自上次检查点以来,在日志文件中应用这些操作。
MongoDB WiredTiger 首先使用内存缓冲来存储日志记录,直到超过128 kB,才写入磁盘。根据以下时间间隔或条件,WiredTiger将缓冲的日记记录同步到磁盘:
3.2版新增功能:每50毫秒。
版本3.6中:MongoDB 设置检查点以60秒的间隔执行。
如果写入操作包含 j:true 的写入指令,则WiredTiger会强制WiredTiger日志文件同步。
由于MongoDB使用的日志文件大小限制为100 MB,WiredTiger大约每隔100 MB创建一个新的日志文件。当WiredTiger创建新的日志文件时,WiredTiger将同步前一个日志文件。
在写操作之间,当日志记录保留在WiredTiger缓冲区中时,在mongod强制关闭时更新可能会丢失。
原文发布时间为:2018-06-18
本文作者:盖国强