
摘要:大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的TB/PB级数据仓库解决方案。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。在本文中北京多点在线高级架构师杨洋分享了基于MaxCompute构建Noxmobi全球化精准营销系统。
本文内容根据演讲视频以及PPT整理而成。
多点在线属于泛娱乐行业的公司,主打产品是Nox夜神模拟器,其主要用于在PC端玩手游,该产品目前已经稳居国内市场占有率第一两年多的时间了,处于行业领导者的地位。Nox下面主要有两个品牌:Noxmobi和Influencer。
PPT材料下载地址:https://yq.aliyun.com/download/2727
视频地址:https://edu.aliyun.com/lesson_1010_8791?spm=5176.10731542.0.0.UvzDru#_8791
产品地址:https://www.aliyun.com/product/odps
演讲嘉宾简介:
杨洋,多点在线高级架构师。
本文分享将主要围绕以下三个方面:
一、行业及公司背景介绍
二、广告业务和系统
三、相关技术及MaxCompute应用
一、行业及公司背景介绍
行业介绍:什么是数字营销
目前全球广告市场规划约6000亿,其中约30%为互联网和移动互联网广告,所以这块蛋糕也是很大的。数字营销、互联网广告、在线广告、计算广告、程序化广告等所说的基本上都是同一件事情,这些主要解决的问题就是如何在互联网媒体上投放广告的问题。
行业介绍:什么是数字营销?

数字营销主要有三方参与者:广告主、媒体和中间商。
广告主(需求方):其需求往往是面对流量和库存的,其最大需求就是如何成本更低,效果更好。而效果的定义往往是不同的,一般分为品牌和效果两种。对于品牌而言,比如可口可乐打广告,人们看到广告可能不会立即去买一瓶喝,但是品牌广告会深植在人们的心里,进而产生长期的效应;而效果广告比如在头条上看到一个广告,用户当时看到有兴趣可能就会点击之后进行下载了,这样就能发生直接的转化效果,这种就叫做效果广告。
媒体(供应方):其需求比较简单,就是如何收益更高。收益具有长期和短期之分,媒体往往不能因为短期的高利益而放弃媒体的形象,这样才能让长期的利益更高。
中间商:主要就是通过连接供需来赚差价。有些广告宣传的中间商不赚差价基本上是不可能的,只不过是怎么赚和什么时候赚的问题。赚取差价的主要手段就是规模效应和垄断,而无论是广告主和媒体只要能够垄断就能够具有更高的议价权。
总而言之,数字营销就是应用最新的互联网技术来提高营销效率,会应用比较前沿的人工智能、机器学习、经济学上的博弈论等。广告主会追求减少浪费,让最合适的人看到广告,这也是数字营销相比传统营销的特点。媒体则是将广告为卖给最需要的人,最需要的人则将会通过出价体现自己的需要。中间商则是高效地撮合交易。如下图所示的是广告行业的简单生态图,图中的DSP大概就是前面提到的需求方,也就是广告主。其右边是流量方也就是媒体,下面这部分则是赚取差价的中间商。

二、广告业务和系统
Nox夜神介绍:Three major product systems support to capture high-LTV users with low cost
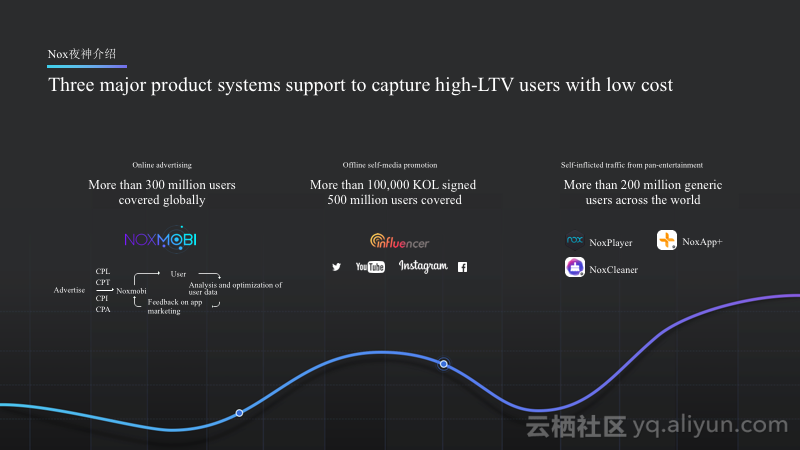
上图中最左边是Noxmobi广告平台;中间的是Influencer,在国外基本上就是网红;最右边的NoxPlayer和NoxCleaner就是Nox自有的媒体流量,多点在线的广告也主要会投放在这些广告上。
Nox夜神介绍:Manage Every Marketing Stage

如上图所示的是夜神在发行前期、中期和后期所应该使用的相应产品。
Nox夜神介绍:Pre-Launch and Launch Marketing

如上图所示的就是Nox流量上的广告位,图中右侧是模拟器的启动图和Launcher部分的广告位,这些广告也不会非常影响用户的体验。Nox主要是做海外的生意,而国内和海外的广告市场是不同的,所以也是分开来做的。
NoxInfluencer示例

如上图所示的是目前主推的Influencer,目前也有一波流量红利,找网红推送APP,右图是Nox为Keep做的广告,比如在健身教练所发出的视频或者直播,给教练一些收益,一起来做视频,也可以看到Keep的广告收益也是非常好的。目前Nox也对于自己的流量端产品用Influencer进行营销,花费大约10万,使得自然新增达到了每天1万,APP开发者都知道这其实是一个非常可观的数字,因为自然新增能够将应用在GooglePlay上的排名推到很高的位置,使得NoxCleaner在一些国家直接达到工具排行榜的前三。
广告业务流程介绍:Online advertising
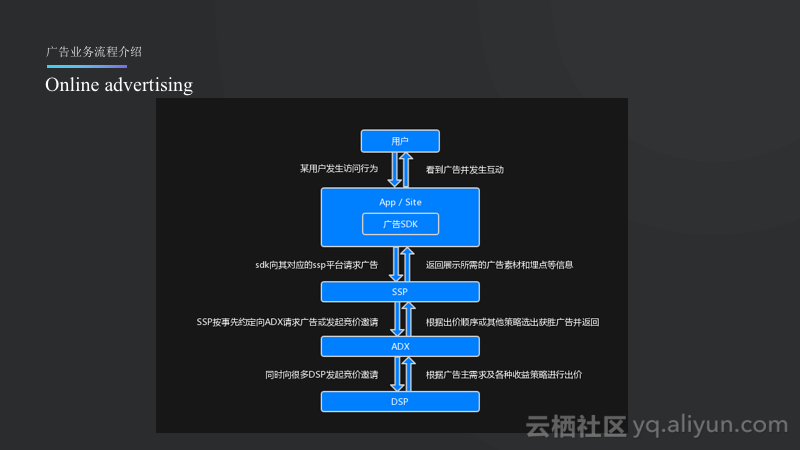
在线广告业务的基本流程可以从用户的访问开始,用户首先打开一个APP或者访问一个页面,当发生了用户访问行为之后,一般在APP里面会有广告的SDK,之后SDK就会触发展示然后去请求广告的内容。SDK一般会与一个SSP关联,属于某一家SSP,然后去SSP上请求广告。SSP再对接ADX,也就是之前所提到的中间商,其主要负责撮合交易。ADX又会对接很多的DSP,并向很多的DSP发起竞价邀请,DSP则将会代表广告主决定是否需要投广告以及广告的出价是多少,并在ADX进行多家的比较,做一次竞价的拍卖,价高者得,但是按照第二高价收费,再将获胜者一步步返回给用户,用户最终就会看到赢得本次竞价的广告。广告后续还会发生一些点击、下载、安装等行为,并进行进一步跟踪。
Nox广告系统演进
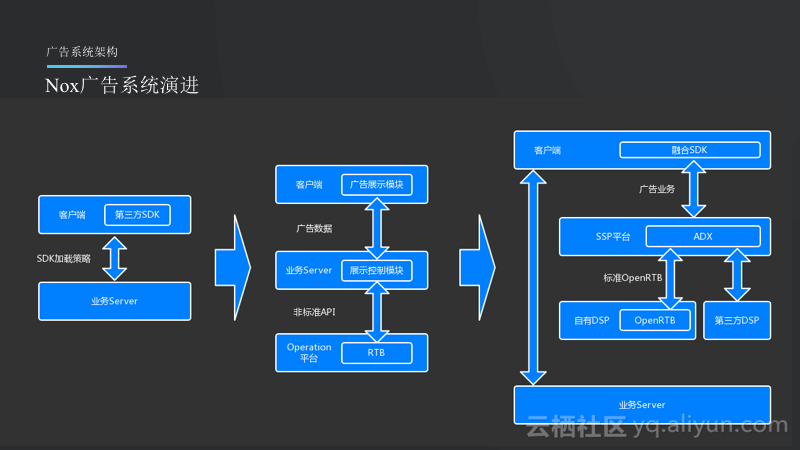
如上图所示的是Nox广告系统的演进情况,首先可能与小开发者一样直接集成第三方的SDK,而第三方的SDK的广告是完全不能被控制的,只不过会每天给Nox一定的收益,而在这个阶段其实收益也是比较低的。后来,Nox就自己做了一个广告展示模块,由业务同学去接国外的离线Offer,在国外某些广告主或者品牌会放出来一些离线的Offer,这样的收益就比第一阶段高出了很多,这个阶段的系统会自己在客户端做展示模块,而在业务Server里面则会有相应的展示控制模块,再往后就是在接到Offer之后做一些简单的CTL预估,之后再做一些比较并将收益比较高的投放出去。第三个阶段系统展现图中的中心部分就是广告业务,最外层的两个模块就是原来的业务系统,最外层两个模块之间的连接就会变得很细,基本上只做流量切分的工作,而中心部分就是前面所提到的DSP、SSP以及集成的ADX模块,从而形成一个完整的广告生态。在这里,除了自己本身的DSP还会和第三方的DSP进行竞价保证流量的收益最大化。此外,SDK还可以做成融合的,虽然其不开放,但是将做成展现其他第三方SDK也会产生一些收益。
三、相关技术及MaxCompute应用
DSP 系统数据流及相关服务
SSP和ADX相对而言比较简单,因此在这部分将会重点讲述一下DSP系统数据流。Rtb就是Runtime Bidding,也是DSP里面比较重要的一个部分,主要是做实时竞价的。所以广告流程一般而言就是从Rtb模块开始,在竞价的过程中会产生Bidding的Event,并将Bidding的Event都输入到Kafka里面,Kafka里面会有订阅的消息,一直更新大的Cache,这里面的数据会通过流式计算做成feature再反馈给Rtb系统。Pixel就是事件服务,比如发生了展现或者安装之后就会访问到这个服务,而这个服务将会Tracking到本次广告的所有Session,这样的数据也会流入Kafka,同样由Updater和流式计算进行处理。而从Kafka里面会另外分出来一只数据流通过高速通道回流到中心节点,也就是MaxCompute上面。MaxCompute会进行一些离线的报表计算和特征,报表就会输出到DSP Report上面(比如RDS)。
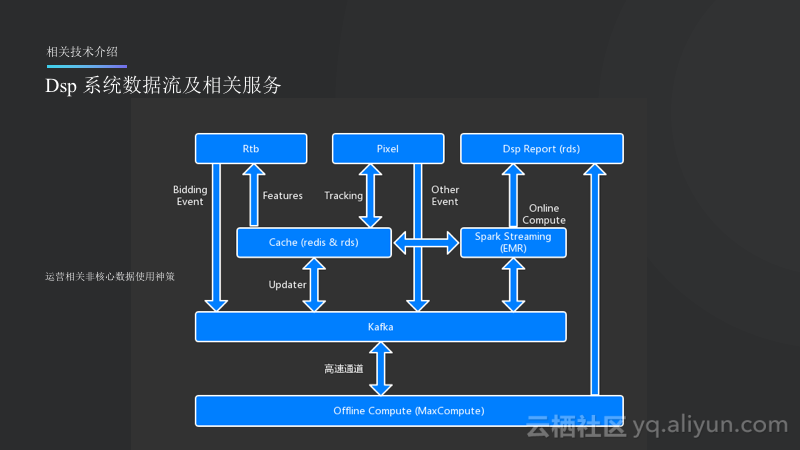
其实Nox设计的所有广告的核心数据将会走这样的一套比较复杂的流程,而一些运营相关的非核心数据则会主要使用了自己搭建在阿里云上的神策这款BI服务,其也属于企业级的应用服务。
流式计算Spark Streaming应用
流式计算Spark Streaming主要用于实现实时的报表以及实时特征的计算。因为业务的主要要求是必须稳定并且能够实现7*24小时的可用。可以接受秒级延迟,比如广告投出去了,晚10秒钟展现在报表里也是没问题的。可根据吞吐量横向扩展,比如突然新接了几家SSP,突然变得流量很大,不能在这个时候让系统挂掉。此外,因为业务在全球都有,所以需要全球的聚合任务,需要通过一个平台看到各个国家的数据。
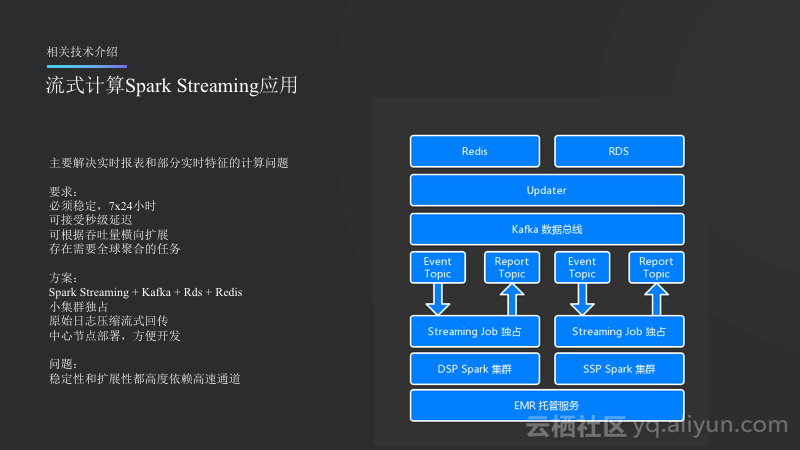
Nox选择的方案就是:Spark Streaming能够将上面几项需求全部满足,另外就是配合Kafka、RDS以及Redis做输出。在部署上面,需要实现小集群独占,这里所用到的就是阿里云EMR,其可以帮助客户托管集群,Nox只需要在阿里云EMR上面申请一个小集群,比如三到五台机器,这些机器申请之后就不再释放掉了,会一直独占着,并且7*24小时地跑流式计算任务。原始日志压缩流式回传,这个是因为Nox在各个数据中心都有Bidder或者Pixel的服务,会产生很多数据,之前的一种方案是在每个中心先将数据计算成半成品,之后在进行回传,这样所用的带宽就会比较小,但是如果采用这样方案,那么所有的功能都需要开发两套,在本地先计算,之后传回来再进行聚合计算,这样就会比较复杂,因此最终决定将日志进行压缩,以流式方式进行回传,这样的方案在验证之后发现所占的带宽不是很大,而因为是流式传输,因此带宽也比较平稳,虽然这里所用的带宽属于高速通道带宽,因此成本也可以接受。而压缩则使用了Kafka,其是能够支持压缩协议的。此外,中心节点部署能够方便开发。
上图中最底层就是阿里云的EMR托管服务,在其上是DSP平台和SSP平台,他们的集群是分开的,如果流量特别大,某一个平台被打挂掉了,另外一个平台是不会受到影响的。而托管服务的好处就是能够托管很小的集群,对于企业而言也没有什么成本。Kafka里面输入的就是Event的Topic,之后还会输出回Kafka,这样Updater再将Kafka里面的数据放到Redis或者RDS用于构建模型和计算报表。这样的设计的唯一问题就是比较依赖于高速通道,这样稳定性和扩展性就有可能受到限制。
离线计算MaxCompute应用
离线计算部分,Nox主要使用了MaxCompute。几乎使用了MaxCompute来解决各类数据计算问题,BI数据、广告报表、反作弊、标签抽取、特征数据计算、统一用户标识、爬虫数据处理等。其实在一开始,Nox也是自建Hadoop集群,购买了阿里云的ECS搭建集群,从最开始的6台一直到后来的十几台,这时候实在扛不住了,机器经常宕机,因为使用的是Spark,因此内存很容易占满,某一天用户突然增多了,数据就没了。此外,这样的成本也非常高,因为当时主要运行BI数据,所以基本上都是在晚上运行的,而白天机器则处于空闲状态,因此成本很高。后来采用了EMR的按量付费集群,晚上申请之后跑数据,但是白天能够释放掉,但是这样的过程则是比较漫长的,需要10到20分钟。后来Nox开始接触到MaxCompute,使用起来非常好,其带来了很多优势。首先,不再需要运维集群了,此外其计算速度很快,虽然说Spark的计算速度很快,但是小集群的Spark和大集群的Hadoop是无法比拟的,所以大集群的Hadoop其实计算速度是很快的。MaxCompute是真正的按量付费,因此成本也能够大大降低,而自建Hadoop、使用EMR以及使用MaxCompute的成本是成量级降低的。差距也是非常大的。主要使用SQL开发,效率比较高,也便于调试,文档也比较清晰。此外,MaxCompute还提供了一个还不错的调度系统,如果是自己搭建这样调度系统还是比较困难的。
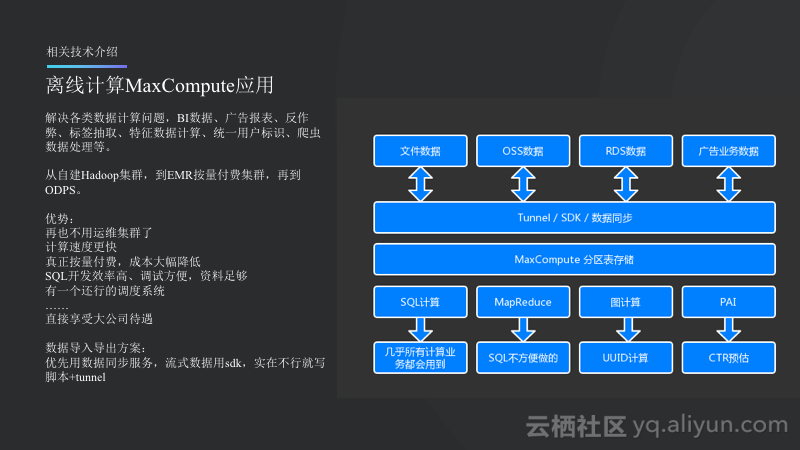
对于数据的导入和导出而言,因为Nox有很多海外的服务,有些服务是不能覆盖到的。所以Nox采取的策略是优先使用数据同步服务,而流式数据则使用SDK,当数据同步和SDK都不合适就写脚本+tunnel导入和导出数据。
如上图所示的文件数据主要是爬虫,因为一些服务的日志是达到OSS上的,并且有一些外部数据也是先上传到OSS上面的。RDS则是什么都有的,广告业务数据就是前面所提到的,这些数据会选择合适的方式统一进入到MaxCompute的分区表里面。SQL计算基本上都会用到,MaxCompute则是在SQL写起来很费力或者运行很慢的情况下使用。图计算使用的并不多,只是会在计算同一用户UUID的情况下使用,这里应用了最小连通域的算法,比如一个用户使用了多个设备,则需要将这些设备统一地关联到同一个用户身上。而PAI平台对于广告的CTL预估非常重要。
特征计算和标签抽取
如下图所示的某第三方DMP的对外标签体系的示例,大概分了几类,比如人口学、设备信息等大类,在每个大类下面还会有多个标签。特征一般而言就是连续值,标签则是指将连续值做一些规则之后所打的标签。举例而言,定义特征,最近一周内活跃天数,则有0~7的取值。而定义标签规则,则是一周内活跃0天、1天、2~3天、4~5天、6~7天的分别是不活跃、低活跃、中活跃、高活跃、极高活跃用户。当在做好定义之后,就要看大家的SQL写的是好是坏了。之前在不支持with的时候,SQL代码一般都要写很大一堆,而且很难改动。此外,在写SQL的时候注意代码分隔还是很重要的。另外的一些建议就是优先使用內建函数,虽然一些內建函数和UDF的功能差不多,可能一个UDF能够实现两三个內建函数的功能,但是效率却相差了很多,虽然使用內建函数会让代码看起来丑一些,但是绝对比UDF运行速度要快得很多,所以在內建函数无法满足需求的时候再去考虑UDF,实在不行就可以用MapReduce实现,比如对一大批特征做等频离散化。

上述这些都是DMP的标准功能,但是Nox目前还没将其实现平台化,都是使用标签写的。而阿里云上有标签服务,目前也在考虑使用。
Targeting
所谓Targeting就是人群定向,相对于把特征输入模型而言,标签式Targeting主要是方便人来操作,使用投放人的经验通过标签定向的方式来优化表达。比如在广告投放初期可以比较好地缩放盲打范围。另外一种则是Look-alike方式,Look-alike方式的定向为寻找相似的人,种子用户为正例,从所有用户中找到正例概率较大的人群。以上就是定向的两种主要方式。
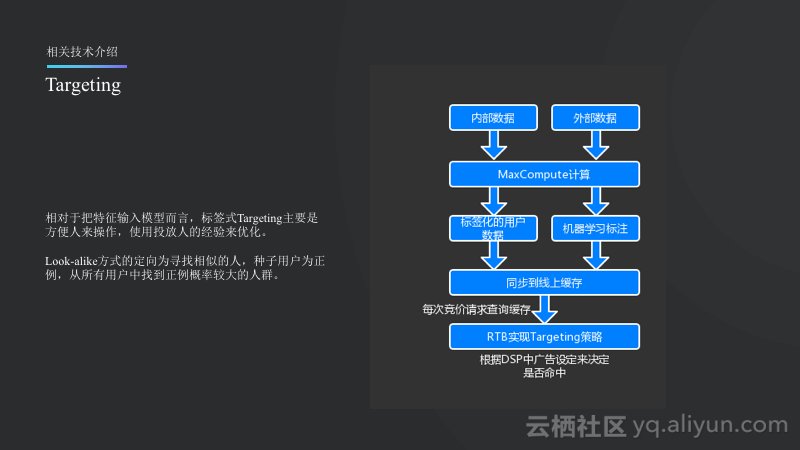
如上图所示的定向的主要做法就是将内部和外部的数据输入到MaxCompute里面,经过各种计算将标签化的数据或者用机器学习标注好的数据同步到线上并缓存好。之后在进行实时竞价RTB里面查询缓存,命中之后就在DSP里面由广告主配置,命中了就投放广告,否则就不投放。
Ctr预估
Ctr预估是Nox投入比较多的一项工作。Ctr预估并不一定是预估Ctr,还可能去预估Cvr甚至是Ctr和Cvr的乘积,这些统称为Ctr预估。其作用是首先计算Ecpm的值,Ecpm就是每次展现的期望收益,期望是一个概率论上的概念,其等于用单价乘上本次收益可能的概率。Ecpm也将指导绝大部分投放相关策略。
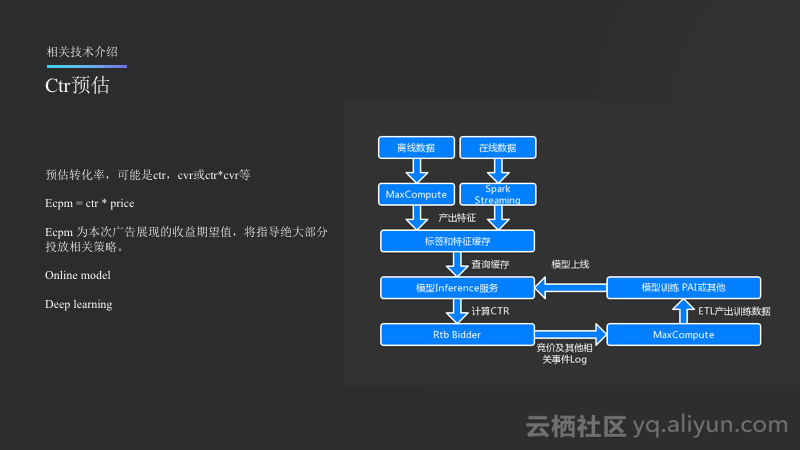
如上图所示,主要分为两条线,一条是离线数据会走MaxCompute,而在线则会走Spark Streaming。总体最后会输入到标签和特征的大Cache里面,Cache中的数据有一部分直接加载到内存里面,另外一部分比如用户特征无法加入内存就会在Inference服务查询缓存,这里就会组合出一个特征的向量,用来计算Ctr的值,并将值返回给Rtb的Bidder,在Bidder做一系列的策略,最终得出竞价的决策。竞价完成之后,是否参与、是否竞价成功以及是否展现等日志都会灌入回MaxCompute或者Spark Streaming进行模型训练,最终对已有模型进行更新,形成一个整体的闭环。Online model需要使用Spark Streaming,而Deep learning就需要用TensorFlow等了。
Pacing
Pacing比较复杂一些,其就是不止考虑单次展现的收益,而要在单次竞价时考虑对全局收益的影响,比如考虑一天之内总收益如何,比如可能将转化率最高的Offer在一天开始的两小时内都投完了,但是其他的Offer都没有投出去,这样计算下来总收益并不如将全部广告都投完的收益高。Pacing的整体思路就是通过对流量分层和分时的统计和预估,用数学方法来保证全局收益的最大化。Nox则根据Yahoo的论文实现了自己的方案,这里面最核心的就是将Ctr估算准确,并将分层和分时的各种统计值计算好,然后按照其策略执行即可。
Nox目前也在寻求更多的合作伙伴,希望更多与具有出海意向的开发者进行深入合作。

如需了解更多关于MaxCompute产品和技术信息,可加入“MaxCompute开发者交流”钉钉群;
群号11782920,或扫描如下二维码加入钉钉群。





