
摘要: 大数据计算服务(MaxCompute)是一种快速、完全托管的 GB/TB/PB 级数据仓库解决方案,目前已在阿里巴巴内部得到大规模应用。来自阿里妈妈基础平台大规模数据处理技术专家向大家分享了MaxCompute在阿里妈妈数据字化营销解决方案上的典型应用经验。首先介绍了广告数据流,分析了MaxCompute 是如何解决广告的问题;然后通过阿里妈妈内部的应用经典场景来介绍其如何使用MaxCompute;最后介绍了MaxCompute提供的高级配套能力以及在计算和存储方面的优化。
PPT材料下载地址:https://yq.aliyun.com/download/2730
视频地址:https://edu.aliyun.com/lesson_1010_8790?spm=5176.10731542.0.0.Zy64Up#_8790
产品地址:https://www.aliyun.com/product/odps
演讲嘉宾简介:
梁时木(载思),阿里妈妈基础平台大规模数据处理技术专家。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。

本次的分享主要分为两部分:
一、 题外话:该部分主要介绍在听完之前的分享后,嘉宾的几点个人感受 。
二、广告数据流介绍: 该部分主要是对没有中间商赚差价的广告数据流的基本介绍以及为什么MaxCompute能解决广告的问题。
三、典型应用场景:该部分主要通过阿里妈妈内部的应用经典场景来介绍其如何使用MaxCompute,包括数据分层体系、报表和BI、搜索引擎索引构建和算法实验。
四、高级功能和优化:该部分主要就阿里妈妈在五六年的MaxCompute内部使用和管理过程中的相关高级功能和优化进行公开分享,包括MaxCompute提供的高级配套能力以及在计算和存储方面的优化。
一、题外话
开始之前先聊一点题外话,是我在听完刚才的分享之后的几点感受。其实我从2013年就开始在内部项目中使用MaxCompute,阿里妈妈作为第一批登月用户,踩了很多坑。听了刚才的分享,我的第一感受是,MaxCompute有好多功能我们都没有关注过,作为一个资深用户,很多功能都不知道听起来好像有点不太合格,但转念一想这可能是MaxCompute作为一个平台、一个生态解决方案应该具备的一种能力。就是说它让一个终端用户只需要看到你所关注的东西,有一些你不太关注的,而对于整个生态链上又必须有的东西它可能潜移默化的帮你做了,在我看来这其实是一种很强的能力。在听完分享后的另一个感受就是我还是蛮庆幸在阿里这边做这些事情的,一些中小公司在基础设施服务这块很需要一些第三方平台的支持,因为你会发现它们如果从头搭建的话,成本会特别高,而MaxCompute、阿里包括钉钉这样的产品,撇开商业化这个因素,它们更多的其实是帮助我们推动互联网技术的进步,帮助我们做一些基础上的事情,从而让我们有更多的精力去关注与自己业务相关的事情。
二、广告数据流
聊完题外话,下面正式开始我的分享。首先向大家介绍一下广告数据流。下图是广告数据流的一个简化版本,因为我们今天的主题是大数据相关的计算,所以我们站在整个数据流的角度简化介绍传统广告,如搜索广告和定向广告。在图中可以很清楚的看到,从角色上来说,比较受关注的是广告主和网民两个角色。
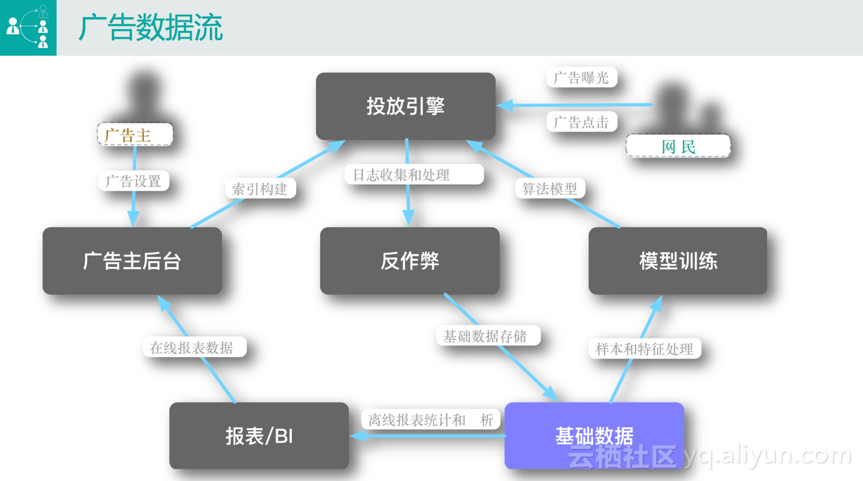
广告主后台
一般来讲,广告主首先会在广告主后台进行相关的广告设置,举个最简单的例子,一个广告主要做一次广告投放,首先需要设置一些基本信息,如将广告投给“来自北京”的“男性”,或者当用户搜索“连衣裙”的时候将广告投给他(她)。
投放引擎
广告主做完设置之后,会用到最重要的一个服务,即投放引擎。它的作用是当广大网民在百度或淘宝键入搜索信息后想其投放相关的广告。比如淘宝搜索“连衣裙”,结果页里面显示的一部分是自然搜索结果,还有一部分是带有“广告”图标的结果,这些结果就是通过投放引擎投放给广大网民的。
与网民最相关的两个行为是广告曝光和广告点击。当网民在使用某个平台进行搜索的时候,比如淘宝,投放引擎里面会用到两个很关键的模块来决定将什么广告投放给网民,即索引和算法:
· 索引构建。当用户键入某个搜索关键词后,如淘宝搜索“连衣裙”,会有上万条商品满足该关键词,不可能将所有的商品都投放给用户。 这个时候的解决方案是首先从广告库中查询有多少广告买了该商品,这个数据需要广告主在后台设置,即哪些广告可以投放给该关键词。
· 算法模型。假如有一万个广告候选集,相关的评分服务会根据一系列的特征和后台训练出来的模型对所有的广告进行打分排序,最终按照一定的规则展现给用户。
反作弊
上面介绍的是网民看到广告的过程,相应的在系统后台会产生一些日志,最典型的是广告的曝光和点击日志,会用到反作弊的模块。因为很多时候网民的行为不一定人操作的,有些是通过API或工具等恶意的手段进行竞争,反作弊模块的作用就是对这些行为进行判断并给出相应惩罚决策,如扣费。
基础数据
经过反作弊模块的数据我们认为是可信赖的,会将其存储在基础数据平台中,此处的基础数据平台是一个抽象的概念,最终其实就是MaxCompute。
报表/BI
有了数据之后,最常见的两个应用场景是做报表/BI分析和模型训练。
· 报表/BI分析。主要有两种情况,一种情况是广告主在设置了广告投放之后,想要了解广告的投放效果,此时会有相应的统计数据到广告主后台;另一种情况下BI运营的人员也会对这些数据进行分析,如某些广告位的表现情况。
· 模型训练。前面已经提到,投放引擎第一步只能拿到一个很大的广告候选集,如何筛选用户预估分最高的广告并投放给用户是模型训练这个模块要做的事情。该模块需要用已经存储的原始基础数据去跑各种各样的模型,从最传统的逻辑回归到现在的深度学习,跑完的数据再推送到投放引擎,这个时候就可以实现广告的在线评分功能。
以上是广告的简要数据流的介绍,接下来分享为什么我们这么久以来一直坚持用MaxCompute。总结一下主要有三点,即数据友好、生态完善持续改进和性能强悍。
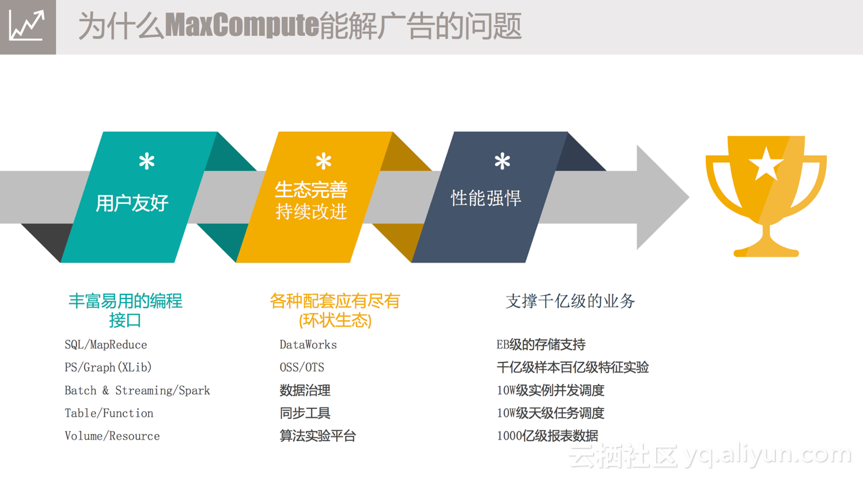
1) 用户友好。从刚才的数据流介绍中,或多或少能看到一点,我们的应用场景有很多,比如反作弊的场景,再比如报表和BI分析的场景,针对此MaxCompute提供各种各样的计算能力和丰富易用的编程接口。最传统的是SQL的表达支持,如果SQL表达的语义不满足要求,加UDF仍然解决不了问题,MaxCompute还支持用户自己写一个MapReduce,提供原始数据用户可以自己去加工;还支持用户做一些图计算像Deep Learning;另外MaxCompute本身也是支持Batch和Streaming两种功能,包括之前提到的Spark Streaming;还有一点也是我比较喜欢的,在Hadoop生态圈中,大家其实更多的看到的是HDFS文件路径,那在MaxCompute中,我们更多的看到的是一堆一堆的表,表对用户来讲有Schema,比空洞的文件更容易理解一点,针对这些表MaxCompute提供API层面的操作支持,另外也提供相应的Function,包括UDF、UDTF类型的支持;同时MaxCompute还提供半结构化类型的支持,如Volume,支持用户操作相关的Resource。上述介绍的功能为用户的开发提供了便利。
2) 生态完善持续改进。MaxCompute是一个平台,一个生态系统。在体验过MaxCompute整套系统之后,我们发现其可以应用到我们开发、运维管理的整个过程中。从最开始数据产出之后,如果要加载到MaxCompute平台中,可以通过“同步工具”来完成;数据同步之后,如果想要做数据处理,可以通过“DataWorks” 跑一些的简单的模型来做数据分析和处理;复杂的数据处理可以通过“算法实验平台” 来完成,目前支持TensorFlow上的一些功能;数据处理完后,传统的做法是只看数据是否正确,但这对于系统管理人员来讲是远远不够的,还需要看结果好不好,是否有优化的空间,以保证投入产出比,比如传统的离线任务,分配资源的方式是基于plan的模式,用户需要预先预估一个instance需要多少CPU和Memory,但是会存在两个明显问题,一个是依靠经验的估计是不准确的,另一个是现在的数据量是在不停变化的,无法很好地估计。针对这个需求,“数据治理”会给用户相应的反馈。
3) 性能强悍。阿里妈妈作为业界数字化营销的厂商来说,数据量非常大。目前使用MaxCompute已经可以完成EB级别的数据存储;在具体的场景中,可以完成千亿级样本百亿级特征的训练实验;跑一个MapReduce或SQL的Job,MaxCompute可以实现十万级实例的并发调度,后台远远超过十万实例的并发度;阿里妈妈一个BU,目前一天之内跑在MaxCompute的Job数已经达到十万级别;最后是我们的报表数据,这其实也是最常见的一个场景,目前我们在MaxCompute的报表数据已经到千亿级别。
三、几个典型的应用场景
介绍完为什么使用MaxCompute之后,再给大家分享一下阿里妈妈的几个典型的应用场景中是如何使用MaxCompute的。
数据分层
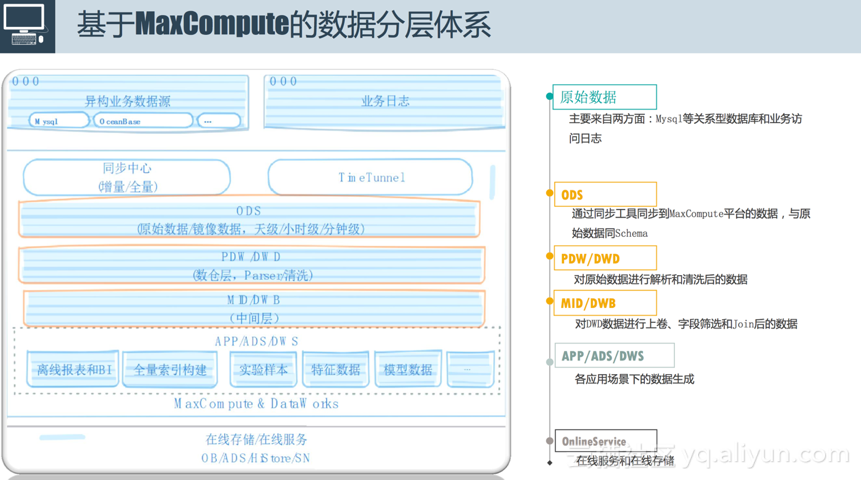
前面介绍了广告数据流,我们针对MaxCompute也对数据进行了划分(如上图所示),主要划分为六层 。
1) 第一层是原始数据层,原始数据的来源一般有两个,一个是我们的业务数据库,比图MySQL或Hbase,另一个是我们的业务访问日志,如刚才提到的广告的曝光和点击日志,这些数据是放在我们的服务器上面的。
2) 第二层是ODS层,即通过同步工具同步到MaxCompute平台的数据,与原始数据同Schema。原始数据要做离线处理的时候(包括Streaming处理),我们内部使用同步中心平台进行全量和增量同步,同时也会使用TimeTunnel进行整个服务器日志的采集。最终同步到MaxCompute平台的数据与原始数据是同Schema的,但是它能以天级、小时级、分钟级实时或准实时的将数据同步到离线平台里面。
3) 第三层是PDW/DWD。有了同步的数据后,大家知道,数据的格式是千奇百怪的,以日志为例,我们线上回流的日志是遵循一定的协议的,想要把数据真正用起来还需要经过一系列的操作。第一步会进行数据清洗,包括上面提到的反作弊也是一种清洗的方式;然后会对数据进行简单的拆解,将其拆解成可以理解的字段。
4) 第四层是中间层MID/DWB。数据量过大的情况之下,比如阿里妈妈一天产出的业务数据高达几十亿,这个数据量根本无法实现直接处理分析,所以我们的做法是使用中间层,对DWD数据进行上卷、字段筛选和Join,后续业务的应用基本上是基于中间层来做的。
5) 第五层是各种应用场景生成的数据层APP/ADS/DWS。具体的场景包括离线报表和BI、全量索引构建、模型训练,后面会从这三个方面的的场景来具体介绍以下如何使用MaxCompute。
6) 最后是在线服务和在线数据存储层。
报表和BI
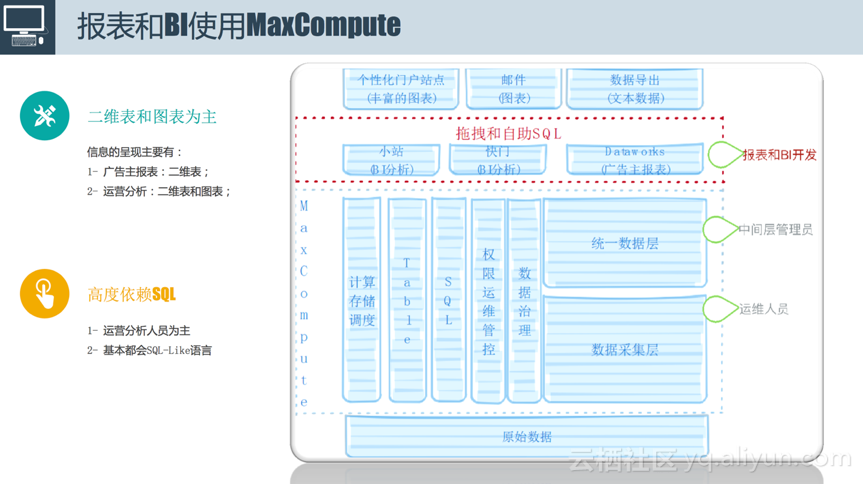
首先介绍一下报表和BI是怎么使用MaxCompute的。对于一般的用户来说,我们只需要了解两部分内容,包含什么Table,用SQL怎么处理它们。报表和BI具备以下两个特点:
1) 二维表和图表为主。对于广告主来讲,信息的呈现主要通过二维表来完成,通过过滤排序就能看到想要了解的结果;而对于运营人员来讲,除了二维表之外,可能还需要一些图表的具体分析。我们会提供这样一种能力,这种能力就是,比如想要给广告主来看的话,提供数据导出功能,将数据直接导到线上,供广告主在后台直接查看效果;其次在部门内部发送支持邮件;再次我们提供类似小站的功能,即个性化门户站点,后面会通过简单的demo进行展示。
2) 高度SQL。上述介绍的所有功能都是高度依赖SQL的,大部分情况下是不需要做一些Java开发的,也不需要去写太多的UDF,用户在报表和BI中只需要去写SQL,有些甚至只需要拖拽几下就可以得到想要的结果。
下图是报表和BI使用MaxCompute的demo截图。用户输入简单SQL表达之后,通过简单的预处理就能看到想要的数据,这个数据不仅可以在系统中查看,还可以通过邮件的方式发送,或者推送的线上进行展示。
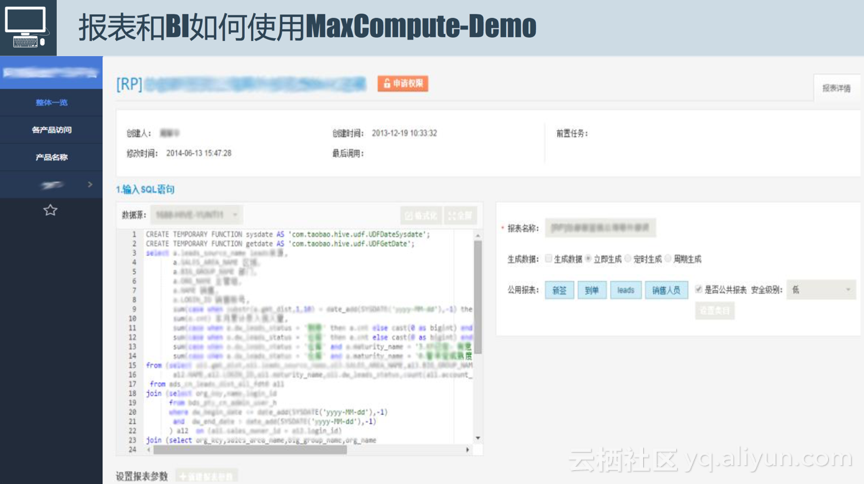
索引构建
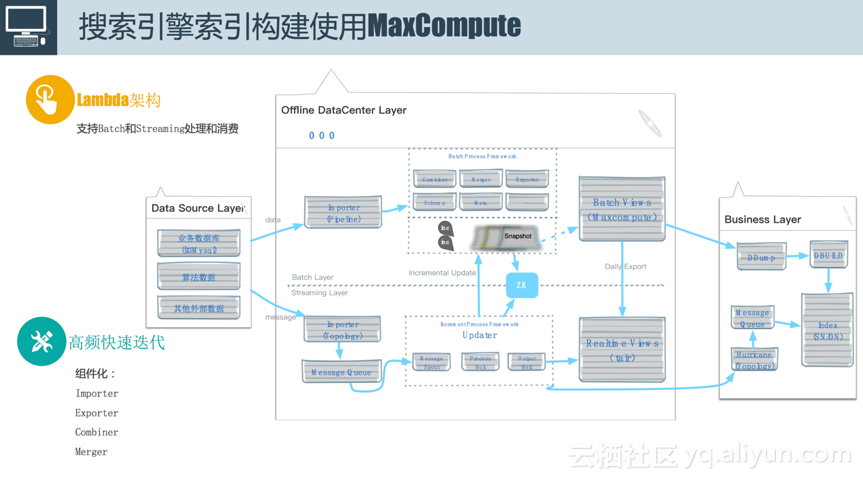
广告主在后台更改投放设置之后,一旦数据量达到百万、千万甚至上亿级别的时候,需要针对在线查询做专有的引擎服务。阿里妈妈广告搜索引擎索引构建使用MaxCompute如上图所示,使用的是Lambda架构,支持离线和在线,可以使用Batch和Streaming处理和消费。使用该架构的背景是当时阿里妈妈在做索引更新的时候,每天伴随着各种各样的实验来查看效果,常常会加很多字段,而且这种情况下并行的需求很高,所以我们对系统的要求是必须支持高频的快速迭代,当时我们定的目标是加一个字段要在半天或者一天之内搞定,并将结果推上线,同时要支持多人同时做这个事情,为了实现该需求,我们当时也做了一些类似于组件化的工作。
对于整个索引构建服务,由于时间关系在此只展示业务层,业务处理过程中需要面对各种异构数据源,图左侧数据源层(Data Source Layer),如业务数据(来自MySQL)、算法数据和其他外部数据,最终将其沉淀到业务层(Business Layer)引擎的索引中,使其支持各种各样的查询。数据从数据源层到业务层需要经过离线数据中心层(Offline DataCenter Layer),分为上下两部分,上半部分是批量层(Batch Layer),下半部分是Streaming层(Streaming Layer)。数据源的接入方式有两种,一种是全量的方式,意思是将MaxCompute上面的一张表直接拖拽过来,然后跑一个离线的索引;但是还有一种情况,比如说广告主做了一次改价,这种更改需要快速地反映到索引中,否则索引中一直存放的是旧信息,将会造成广告主的投诉,因此除了全量流之外,还提供增量流,以将用户的更改实施反馈到索引中。
· 离线部分。我们提供一个类似同步工具的服务,叫做Importer,它是基于MaxCompute来实现的,大部分功能是跑在MaxCompute上的,因为这里面我们进行了组件化,需要进行一系列的类似于数据Combine、Merge的操作,还涉及到源数据的Schema和数据的多版本管理。离线数据存入ODPS中,通过Maxcompute的Batch views来查看。
· 在线部分。简单来讲,比如拿到一条MySQL增量,通过解析将其直接流入消息队列中,然后通过相应的平台包括Storm、Spark以及MaxCompute的Streaming等,利用和离线部分类似的组件跑索引。接下来通过Realtime views可以查到最新的数据,目前通过tair来实现。实时部分的数据每隔一定时间进行Merge,就会形成多版本的数据。它的作用有两个,一个是将这些数据直接批量往在线部分去灌,尤其是在线上数据出问题、走增量流程很慢的时候;另一个是在做离线索引构建的时候,为了避免索引膨胀的问题,需要定期做一次离线全量,为了保证数据实时更新,需要有一条增量流在此期间往全量部分注入数据,为了避免因为服务宕机导致的效率低下,我们提供了多个版本增量数据的保存。
算法实验
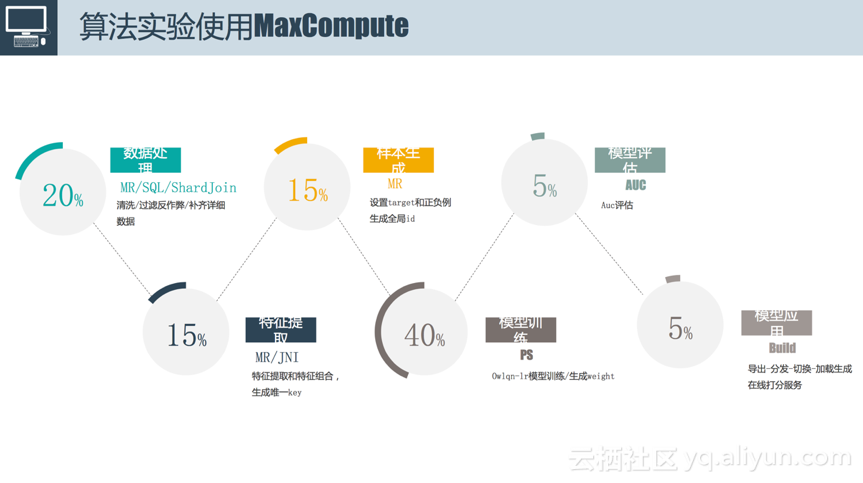
接下来介绍一下算法实验使用MaxCompute的场景。不仅仅是算法实验,包括我们每天往线上推我们的性能模型的时候,都是下图这套流程。整个流程的输入是线上日志,比如哪些用户浏览和点击了哪些广告,输出是对用户的浏览和点击分析后抽取的特征进行在线评分。中间大致可以抽象为六个步骤:
1) 数据处理。数据处理除了前面提到的清洗和过滤反作弊之外,做的最简单的是将多份数据合并成一份数据,这里面除了用到MapReduce和SQL之外,还用到了ShardJoin,是阿里妈妈和MaxCompute合作,为了应对在离线数据进行Join的过程中,两边数据都特别大时效率低的问题而开发的。原理很简单,就是将右表拆成很多小块,使用独立RPC服务去查。数据处理在整个过程中的时间占比约为20%。
2) 特征提取。经过第一步之后输出的结果是一整个不加处理的PV表,包含一系列的属性字段,然后在此基础上进行特征提取,常用的是跑一个MapReduce,最重要的是有JNI的操作,实现特征提取和特征组合,生成唯一的key。比如我想要把UserId和Price联合算出一个新的特征。原始的特征可能只有几百个,但经过交叉、笛卡尔积等操作之后,特征可能会达到几百亿,这个时候前面所提到的MaxCompute支持千亿级别样本、百亿级别的计算能力便得到很好地发挥,这对于调度包括整个计算框架具有极其重要的意义。特征提取在整个过程中的时间占比约为15%。
3) 样本生成。一条样本出来后一般需要设置target和正负例,针对每一个特征会生成一个全局id,最后进行序列化。之所以进行序列化是因为每个计算框架对于输入样本会有格式要求,序列化实际上是对输入样本进行相应的格式转换。样本生成在整个过程中的时间占比约为15%。
4) 模型训练。模型训练的输入是上一步产生的千亿级别的样本,输出是每一个特征的权重。比如“男性”这个特征的权重,购买力是一颗星对应的特征的权重。模型训练在整个过程中的时间占比是40%左右,这个时间和模型复杂度有关,比如说是运行了简单的逻辑回归或者复杂的深度学习,时间是不同的。
5) 模型评估。有了训练后的模型,接下来要进行评估,使用Auc评估训练模型的效果。一般在样本生成的时候会对样本进行分类,分为训练样本和测试样本,使用测试样本对训练好的模型进行评估。模型评估在整个过程中的时间占比是5%。
6) 模型应用。模型评估达到一定标准之后就可以将训练好的模型推到线上,这个过程比较复杂,包括数据导出、数据分发、加载、切换生成在线打分服务。模型应用在整个过程中的时间占比是5%。
以上介绍的六个步骤和MaxCompute最相关的是数据处理(20%)、特征提取(15%)、样本生成(15%)和模型训练(40%),时间占比百分之九十以上的操作都是在MaxCompute进行的。
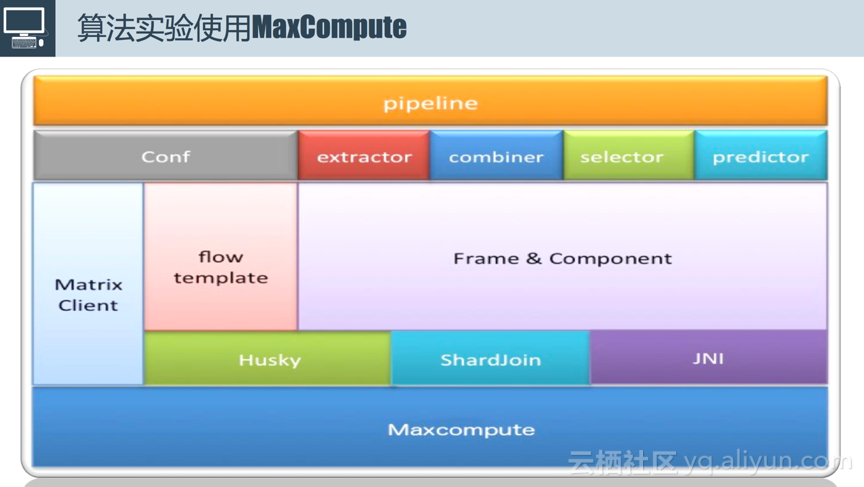
为了支撑算法实验,我们基于MaxCompute搭建了算法实验框架(如上图所示)。整个模型训练不需要开发太多的代码,一般来讲只需要做两个方面的改动,传统的逻辑回归需要增删改特征,深度学习中需要更改各种网络,整个流程是高度一致的。因此我们将这个过程抽象成为Matrix的解决方案。这套解决方案对外来讲是运行了一个pipeline,串联一系列任务,这些任务最终运行在MaxCompute上面。对外提供Matrix Client,用户大部分情况下只需要进行配置文件的修改,比如设置特征抽取的方式,知道原表的Schema抽第几行第几个字段;抽取的特征怎么做组合,如第一个特征和第二个特征进行叉乘生成新的特征;包括特征选择方式,如低频特征进行过滤。框架将上述功能组件化,用户只需要像拼积木一样将需要的功能拼接起来,每一个积木进行相应的配置,比如输入表是什么。样本输入模型之前,样本的格式是固定的,在此基础上我们实现了调度框架Husky,主要实现pipeline的管理,实现任务的最大化并行执行。其他功能由于时间关系在此不多做介绍。
四、高级功能和优化
高级配套能力
因为阿里妈妈在MaxCompute上曾经的资源使用量占比达到三分之一,从计算到存储。因此我们根据自己的经验,接下来分享一下大家有可能用到的MaxCompute的一些高级功能和优化。

MaxCompute提供了我们认为比较重要的四个功能有:
1) 实时Dashboard和Logview。Logview前面已经介绍过了,通过它用户可以不用再去扒日志,可以很快速地查看任务情况,查找问题原因,另外还提供各种实时诊断的功能。当集群出现问题的时候实时Dashboard可以从从各个维度帮用户分析当前运行集群的Project或Quta或任务相关信息,其后台依赖于一系列的源数据管理。当然,MaxCompute能提供的功能远不止实时Dashboard和Logview,但是这两个功能在个人、集群管理过程是被高度依赖的。
2) 强大的调度策略。主要有三种:
· 第一种是交互式抢占。传统的抢占方式比较粗暴,当用户提交一个任务的时候,比如分Quta,无论是Hadoop还是MaxCompute,都会分析是minQuta还是maxQuta,这种情况下一定会涉及到共享与资源抢占的问题。如果不抢占,一个任务会跑很长时间;如果直接将任务停掉,已经运行起来的任务可能需要重新再运行,导致效率低下。交互式抢占比较好地解决了这个问题,其提供了一种协议,这个协议需要和各个框架之间达成,比如说要kill掉某个任务之前,会在一定时间之前发送kill的命令,并给予任务指定的运行时间,如果这个时间结束之后仍然运行不完,则kill掉。
· 第二种是全局调度。阿里云的机器已经达到了万级,当某个集群的任务跑的很卡的时候,如果发现其他集群比较空闲,全局调度策略便可以发挥作用,将任务分配到较为空闲的集群上运行,这种调度过程对于用户来讲是透明的,用户只能直观地感受任务的运行速度发生变化。
· 第三种是兼顾All-or-nothing和Increment的资源分配方式。简单来讲,比如前者跑了图计算的训练模型,后者跑了SQL,这两种计算的资源分配方式有很大不同。对于SQL来讲,如果需要一千个实例来运行mapper,不用等到一千个实例攒够了再去运行,可以拿到一个实例运行一个mapper,因为这种计算实例之间没有信息交互;但是模型训练是一轮一轮进行迭代的,第一轮迭代运行完之后才能开始运行第二轮迭代,因此注定需要所有的资源准备好了之后才能运行,因此阿里云的调度人员在后台做了很多兼顾这两方面资源分配的工作。
3) 数据地图。帮助的用户描述数据、任务之间的关系,方便用户后续业务的处理。
4) 数据治理。任务运行结束对于集群或者任务管理人员来讲并没有结束,还需要去看任务跑得好不好,这个时候服务治理就可以提供很多优化建议,比如某个数据跑到最后没有人用,那与其相关的链路是否可以取消,这种治理不管对于内部系统还是外部系统来讲可以节省很多的资源开销。
计算优化
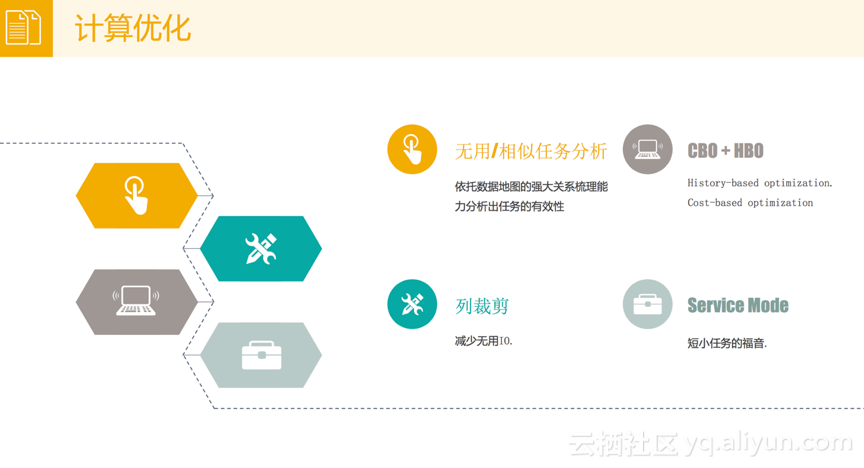
接下来就上面介绍的数据治理向大家分享一下我们的经验。在数据治理计算优化方面,我们主要的用到了MaxCompute的以下四个功能:
1) 无用/相似任务分析。这个很容易理解,它可以帮助用户分析出哪些任务是没有用的,哪些任务是相似的,这需要依托于数据地图的强大关系梳理能力分析出任务的有效性。
2) HBO (History-based optimization) + CBO (Cost-based optimization)。它其实解决的是优化的问题,在跑计算任务的时候,不管使用的是SQL还是MapReduce,一定会预先设定CPU和Memory的值,但是预先设定往往是不准确的。解决的方式有两种,一种是先将任务运行一段时间,根据运行情况计算每个实例大概需要的CPU和Memory,这种方式就是History-based optimization;而第二种方式是Cost-based optimization,解决的是基于成本的优化,时间关系在此不多做介绍,后期如果大家感兴趣的话,会组织相关的高阶分享。
3) 列裁剪。它解决的问题是不用讲整个表中的所有字段都列出来,比如Select *,根据SQL语义,它可以实现十个字段只需要加载前五个字段。这对于整个任务的执行效率包括整个磁盘的IO有很大益处。
4) Service Mode。传统运行MapReduce的时候,会有shuffle的过程,这个过程会涉及到数据在Mapper和Reducer端的落盘,这个落盘操作是很耗时间的,对于一些中小型任务来讲(可能只需要两三分钟就运行完),是不需要落盘操作的。MaxCompute会预判任务的执行时间,短小任务通过Service Mode的方式来降低任务的运行时间。
存储优化
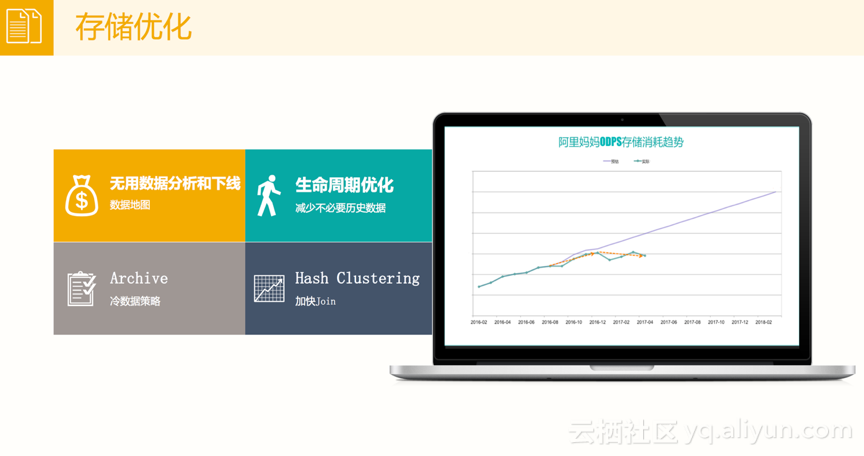
MaxCompute除了计算优化,还有存储方面的优化。存储优化主要体现在以下一个方面:
1) 无用数据分析和下线。这个前面也已经反复介绍过了,可以帮助用户分析无用的数据并下线,和无用Job分析是类似的原理。这里的难点是“最后一公里”,即数据从离线平台产出之后导到线上,最后这一公里的元素是很难去追踪的,这依赖于工具和平台高度的标准化,阿里内部的好处是这一块已经做到了标准化。随着后续阿里云暴露的服务越来越多,这个难点将有希望被攻克,能够帮用户分析出来哪些数据是真的没有人用。
2) 生命周期的优化。一份表到底要保存多少时间一开始是依靠人去估计和设置的,比如一年,但根据实际的访问情况你会发现,保存一天或者三天就可以。这个时候依托于MaxCompute的数据治理,会帮助用户分析出某张表适合的保存时间,这对于存储的优化具有极其重要的意义。
3) Archive。数据是有冷热之分的,尤其是分布式文件存储的时候,都是通过双备份的方式来存储数据,当然双备份尤其意义在,比如可以让你的数据更加可靠、不会丢失,但这样带来了一个问题是数据的存储将会变得大。MaxCompute提供了冷数据策略,不做双备份,通过一定的策略将数据变成1.5备份,用1.5倍的空间达到双备份的效果。
4) Hash Clustering。这个属于存储和计算优化中和的事情。每次在做MapReduce的时候,中间可能需要做Join操作, 每次Join操作的时候可能会对某个表做Sort操作,但是Sort操作没必要每次都去做,这样就可以针对Sort操作提前做一些存储上的优化。
下图展示了的阿里妈妈预估的ODPS存储消耗趋势,可以很明显的看到预期消耗随着时间推移几乎呈直线增长,但中间使用MaxCompute做了几次优化之后,明显感觉存储消耗增长趋势减缓。
介绍这么多优化的功能,最终目的是希望大家对MaxCompute有更多的了解和期待,大家如果有更多的需求可以向MaxCompute平台提出。
如需了解更多关于MaxCompute产品和技术信息,可加入“MaxCompute开发者交流”钉钉群;
群号11782920,或扫描如下二维码加入钉钉群。


