介绍
随着神经网络的发展,很多过去曾被认为是难以完成的任务现在已经可以完成了例如图像识别、语音识别,在数据集中发现更深的关系等已经变得更加容易了。所以我们应该衷心感谢这一领域的杰出研究人员,他们的发现帮助我们发挥了神经网络的真正力量。
如果你真的有兴趣将机器学习作为一门学科,深入了解深度学习网络对你来说是至关重要。大多数ML算法在给定具有多个变量的数据集时往往会失去准确性,而深度学习模型在这种情况下会产生奇迹。因此,了解它的工作原理非常重要!
在本文中,我将解释深度学习中使用的核心概念,即什么样的技巧可以提高模型的准确性。除此之外,我还会分享各种建模技巧,并深入了解神经网络的历史。
目录
- 神经网络的历史
- 单层感知器
- 多层感知器
- 初始化参数
- 激活函数
- 反向传播算法
- 梯度下降
- 成本函数
- 学习率
- 动量
- Softmax
- 多层感知器(MLP)总结
神经网络的历史
神经网络是当今深度学习领域技术突破的基石。神经网络可以看作是大规模并行的处理单元,能够存储知识并应用这些知识进行预测。
1950年,神经心理学家卡尔拉什利的论文发表,他将大脑描述为分布式系统。神经网络的设计模仿大脑,网络通过从学习过程中获取知识。然后,使用称为突触权重的干预连接强度来存储所获得的知识。在学习过程中,网络的突触权重被有序地修改以达到期望的目标。
神经网络与人脑进行对比的另一个原因是,它们像非线性并行信息处理系统一样运行,这些系统可快速执行模式识别和感知等计算操作。因此,这些网络在语音、音频和图像识别等领域表现非常好,就是因为其中输入信号本质上是非线性的。
在Hebb1949年出版的“行为组织”一书中,第一次提出了大脑连接性随着任务变化而不断变化的观点。这条规则意味着两个神经元之间的连接同时处于活动状态。这很快成为开发学习和自适应系统计算模型的灵感来源。
人工神经网络有能力从所提供的数据中学习,这被称为自适应学习,而神经网络创建自己的组织或信息表示的能力被称为自组织。
15年后,Rosenblatt于1958 年开发出了感知器(perceptron),成为了神经元的下一个模型。感知器是最简单的神经网络,能将数据线性地分为两类。后来,他随机地将这些感知器互相连接,并使用了一种试错方法来改变权重以进行学习。
1969年,在数学家Marvin Minsky 和Seymour Parpert发表了一篇对感知器的数学分析后,这个方向的研究在接下来的 15 年里陷入了停滞。他们的研究发现感知器无法表征很多重要的问题,比如异或函数(XOR)。其实,那时的计算机还没有足够的处理能力来有效地处理大型神经网络。
1986年,Rumelhart,Hinton和Williams宣布了反向传播算法的发展,它们可以解决XOR等问题,于是又开启了神经网络时代。在同一年,出版了由Rumelhart和McClelland编辑的《Parallel Distributed Processing: Explorations in the Microstructures of Cognition(并行分布式处理:认知的微结构中的探索)》。这本书一直使得反向传播的影响力越来越大,目前,反向传播已经成为多层感知器训练中最流行的学习算法。
单层感知器(SLP)
最简单的感知器类型具有连接输入和输出的单层权重。这样,它可以被认为是最简单的前馈网络。在前馈网络中,信息总是向一个方向移动; 它永远不会倒退。
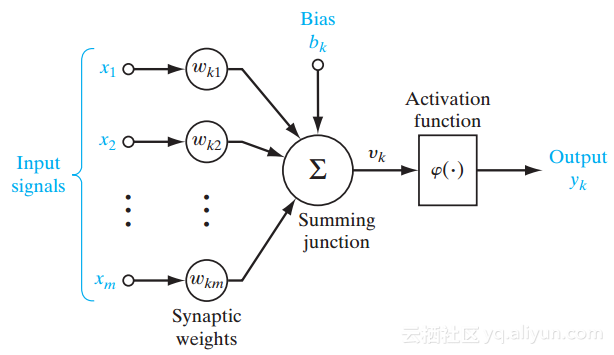
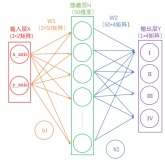
上图就是一个单层感知器,可以更容易地将概念接地和解释多层感知器中的概念。单层感知器表示了网络中一个层和其它层之间的连接的 m 权重,该权重可被看作是一组突触或连接链。此参数表明每个特征(Xj)的重要性。以下是输入的特征乘以它们各自的突触连接的加法器函数:
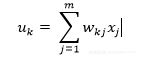
该偏差bk 作为对加法器函数的输出的仿射变换,Uk给出Vk诱导的局部域:
![]()
多层感知器(MLP)
多层感知器(也称为前馈神经网络)是由每一层完全连接到下一层的程序列组成。
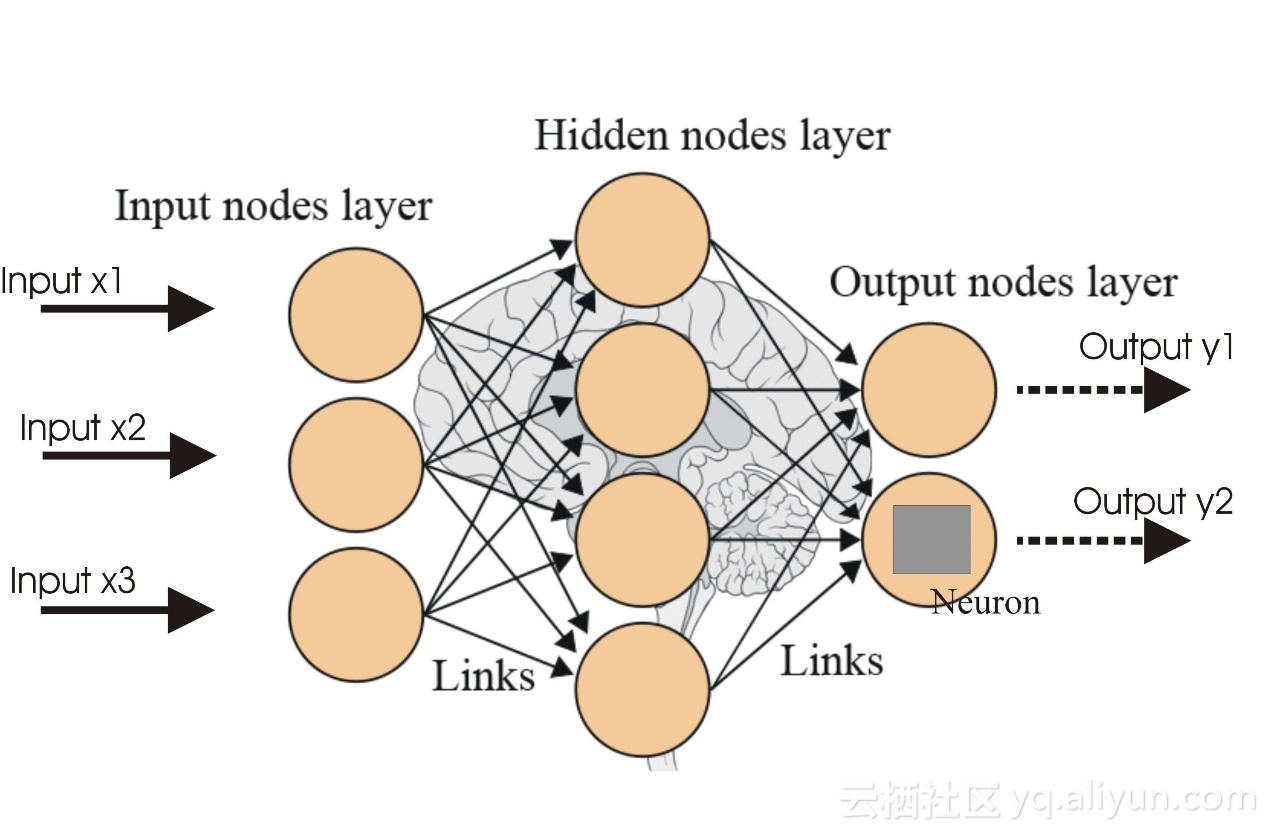
一个多层感知器(MLP)具有一个或多个隐藏层以及输入层和输出层,每层包含几个神经元,这些神经元通过重量链路彼此互连。输入图层中的神经元数量将是数据集中属性的数量,输出图层中的神经元将是数据集中给出的类别数量。
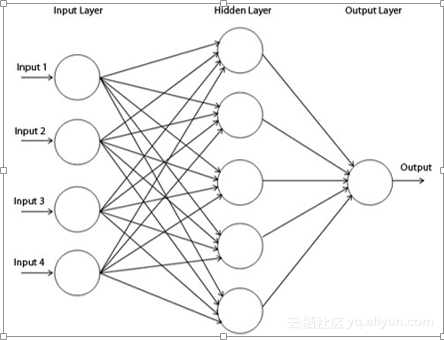
图2显示了一个多层感知器,为了使体系结构更加深入,我们需要引入多个隐藏层。
参数初始化
初始化参数,权重和偏差在确定最终模型中起着重要作用。
一个好的随机初始化策略可以避免陷入局部最小值问题。局部最小值问题是当网络陷入误差曲面时,即使有足够的上升空间,学习时也不会在训练时下降。
初始化策略应根据所使用的激活功能进行选择。
激活函数
激活函数是根据诱导的局部域v来定义神经元的输出为:
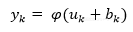
其中φ()是激活函数。以下是常用的激活函数:
1.阈值函数
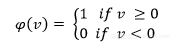
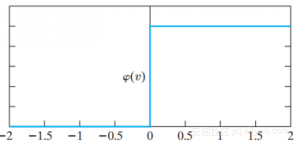
上图表明神经元是否完全活跃。但是,这个函数是不可微分的,这在使用反向传播算法时非常重要。
2.sigmoid函数
sigmoid函数是一个以0和1为界的逻辑函数,就像阈值函数一样,但是这个激活函数是连续的和可微的。
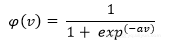
其中α是上述函数的斜率参数。此外,它本质上是非线性的,有助于提高性能,确保权重和偏差的微小变化引起神经元输出的微小变化。
3.双曲正切函数
φ(v)= tanh(v),该功能使激活功能的范围从-1到+1。
4.整流线性激活函数(ReLU)
ReLUs是许多逻辑单元之和的平滑近似,并产生稀疏活动向量。以下是函数的等式:
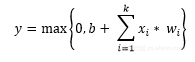
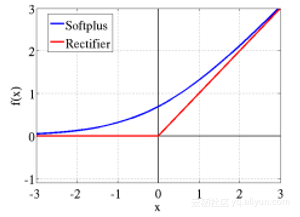
5.Maxout函数
2013年,Goodfellow发现使用新激活Maxout函数是dropout的最佳伴侣。
Maxout单元通过退出来促进优化并提高退出的快速近似模型平均技术的准确性。单个最大单位可以解释为对任意凸函数进行分段线性逼近。
Maxout网络不仅学习隐藏单元之间的关系,而且学习每个隐藏单元的激活功能。以下是它如何工作的图形描述:
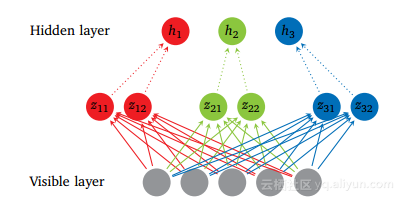
图4显示了Maxout网络,每个隐藏单元有5个可见单位,3个隐藏单位。
反向传播算法
反向传播算法可以用来训练前馈神经网络或多层感知器。这是一种通过改变网络中的权重和偏差来最小化成本函数的方法。为了学习和做出更好的预测,会执行一些训练周期,在这些周期中,由成本函数确定的误差通过梯度下降反向传播,直到达到足够小的误差。
梯度下降
1.mini-batch梯度下降
比方说,在100个大小的mini-batch中,向学习算法显示了100个训练示例,并且相应地更新了权重。在所有mini-batch都按顺序呈现之后,计算每个时期的平均准确性水平和训练成本水平。
2.随机梯度下降
随机梯度下降用于实时在线处理,其中参数在仅呈现一个训练示例的情况下被更新,因此在每个时期对整个训练数据集取平均准确度水平和训练成本。
3.full batch梯度下降
在这种方法中,所有的训练样例都显示给学习算法,并且权重被更新。
成本函数
成本函数有很多种,以下是一些例子:
1.均方误差函数;
2.交叉熵函数;
3.负对数似然损失(NLL)函数。
学习率
学习速率控制从一次迭代到另一次迭代的权重变化。一般来说,较小的学习率被认为是稳定的,但会导致较慢的学习。另一方面,较高的学习率可能会不稳定导致振荡和数值误差,但会加快学习速度。
动量(Momentum)
动量为避免局部最小值提供了惯性,这个想法是简单地将以前的权重更新的一部分添加到当前的权重更新中,这有助于避免陷入局部最小值。
SOFTMAX
Softmax是一种神经传递函数,它是在输出层中实现的逻辑函数的一般形式,这些概率的综合为1且限定于1。
多层感知器(MLP)总结
对于分类任务,softmax函数可以包含在输出层中,它将给出每个发生类的概率。激活函数用于通过使用输入、权重和偏差来计算每个层中每个神经元的预测输出。
反向传播是通过修改它们之间的突触连接权重来训练多层神经网络,以基于需要连续和可微的纠错学习函数来提高模型性能。以下参数已在实验中评估过:
- 隐藏层的数量。
- 隐藏层中的神经元数量。
- 学习速度和动量。
- 激活功能的类型。
本文由@阿里云云栖社区组织翻译。
文章原标题《demystifying-generative-adversarial-networks》,
译者:虎说八道,审校:袁虎。
文章为简译,更为详细的内容,请查看原文。