序列学习是近年来深度学习的热点之一。从推荐系统到语音识别再到自然语言处理,它的潜力似乎无穷无尽,推动着业界不断创新,涌现出前所未有的解决方案。
序列学习的实现形式多种多样,如机器学习域的马尔可夫模型、有向图等,深度学习域的RNNs/LSTMs等等。

在本文中,我们将使用一种尚不太为人所知的叫做紧致预测树(CompactPredictionTree,CPT)的算法来进行序列学习。这种方法简单得让人吃惊,并且比一些著名算法如马尔可夫、有向图等更为强大。
在深入阅读本文之前,我推荐你先读一读“你必读的序列模型(附用例)”一文,作者Tavish在这篇文章中介绍了序列模型及其典型用例和应用场景。
本文目录:
序列学习入门
当我们需要预测一个事件之后可能会发生的某个特定事件时,就需要进行序列学习。序列学习广泛应用于各个行业,例如:
序列学习还可能应用到许多其他的领域。
解决方案现状
为了在这一领域发掘更多解决方案,我们推出了“序列学习黑客马拉松”。参与者各有路数,其中最受欢迎的是LSTMs/RNNs,使用率在私人排行榜前10名。
LSTMs/RNNs已经成为序列建模的热门选择,无论是文本、音频等。然而它们有两个基本问题:
初探CPT(紧致预测树)
紧致预测树(CPT)是一种比传统的机器学习模型(如马尔可夫模型)和深度学习模型(如自动编码器)更精准的算法。
CPT算法的独特之处是其快速的训练和预测时间。我能够在4分钟内对上面黑客马拉松的序列数据集完成训练并进行预测。
不幸的是,这个算法目前只能用Java实现,因此它还没在数据科学家之间流行起来(尤其是那些使用Python的数据科学家)。
为此,我根据算法初创者的文档,创建了一个Python版本的库。Java代码当然有助于理解本文的某些部分。
这个公开的Python库可以在这里(https://github.com/analyticsvidhya/CPT)获得,欢迎您对它作出贡献。从某种意义上说,这个库仍然是不完整的,它还没有得到算法初创者的推荐,但它已经足够好,在黑客马拉松排行榜上获得了0.185分,并且一切都在几分钟内完成。我相信这个库完整之后,性能应该能够和RNNs/LSTMs相匹敌。
在下一节中,我们将介绍CPT算法的内部工作原理,以及它如何比马尔可夫链、DG等传统机器学习模型的性能更优。
理解CPT中的数据结构
作为先决条件,首先需要理解PythonCPT接受的数据格式。CPT接受两个.csv文件--训练和测试。训练文件里是训练序列,而测试文件包含每个序列需要预测的接下来的3项。为了清晰起见,训练和测试文件中的序列定义如下:
1,2,3,4,5,6,7
5,6,3,6,3,4,5
.
.
请注意,序列的长度可以不相同。此外,热编码序列也不适用。
CPT算法使用了三种基本的数据结构,我们将在下面做简要介绍。
1. 预测树
预测树带有多个节点,每个节点有三个元素:
预测树基本上是一种TRIE数据结构,它将整个训练数据压缩成一棵树的形式。如果您不知道TRIE结构是如何工作的,下面两个序列的TRIE结构图将说明问题。
Sequence 1:A, B, C
Sequence 2:A, B, D
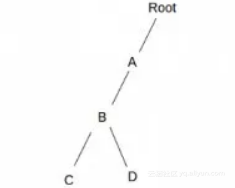
TRIE数据结构从序列A、B、C的第一个元素A开始,并将其添加到根节点。然后B被添加到A后,C被添加到B后。对于每个新的序列,TRIE会再次从根节点开始,如果一个元素已经被添加到结构中则跳过。
产生的结构如上所示。这就是预测树如何有效地对训练数据进行压缩。
2. 倒排索引(II)
倒排索引是一种字典,其中的键是训练集中的数据项,值是该项出现的序列的集合。例如:
Sequence 1:A,B,C,D
Sequence 2:B,C
Sequence 3:A,B
上述序列的倒排索引如下所示:
II = {
‘A’:{‘Seq1’,’Seq3’},
’B’:{‘Seq1’,’Seq2’,’Seq3’},
’C’:{‘Seq1’,’Seq2’},
’D’:{‘Seq1’}
}
3. 查找表(LT)
查找表是一个字典,带有序列ID和预测树中的序列的终端节点的键。例如:
Sequence 1:A, B, C
Sequence 2:A, B, D
LT = {
“Seq1” : node(C),
“Seq2” : node(D)
}
用CPT进行训练和预测
下面通过一个例子来理解CPT算法是如何训练和预测的。示例训练集为:

训练集有3个序列。让我们用ID表示序列:seq 1、seq 2和seq 3。A、B、C和D是训练集中的数据项。
1. 训练阶段
训练阶段会同时建立预测树、倒排指数(II)和查找表(LT)。整个训练过程如下。
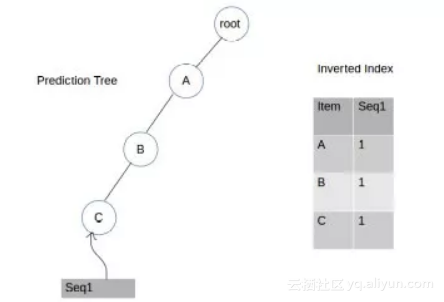
第一步: 插入A,B,C
查找表
先得到一个根节点和一个初始设置为根节点的当前节点。
我们从A开始,检查作为根节点的子节点A是否存在。如果没有,我们将A添加到根节点的子列表中,在带有值为seq 1的倒排索引中添加一个A的条目,然后将当前节点移到A。
查看下一项,即B,看看B是否作为当前节点A的子节点存在。如果不存在,我们将B添加到A的子列表中,在带有seq1值的倒排索引中添加B的条目,然后将当前节点移动到B。
重复上面的过程,直到我们完成添加seq 1的最后一个元素为止。最后,我们将使用key=“seq 1”和value=node(C)将seq 1的最后一个节点C添加到查找表中。
第二步:插入A,B
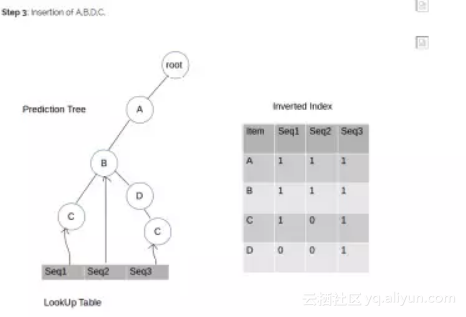
第三步: 插入A,B,D,C
第四步:插入B,C
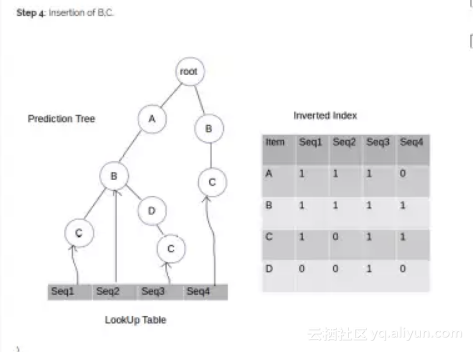
重复这个过程,直到穷尽训练数据集中的每一行(记住,一行表示单个序列)。现在,我们已经准备好了所有必需的数据结构,可以开始对测试数据集进行预测了。
2. 预测阶段
预测阶段以迭代的方式对测试集中的每个数据序列进行预测。对于单个行,我们使用倒排索引(II)找到与该行相似的序列。然后,找出相似序列的结果,将其添加到计数字典的数据项中,并给出它们的分值。最后,使用“计数”返回得分最高的项作为最终预测。下面详细阐述每一步的做法。
目标序列:A,B
第一步:查找与目标序列相似的序列。
利用倒排索引找出与目标序列相似的序列。通过以下几步来查找:
比如:
存在A项的序列集= {‘Seq1’,’Seq2’,’Seq3’}
存在B项的序列集= {‘Seq1’,’Seq2’,’Seq3’,’Seq4’}
与目标序列相似的序列=二者之交集= {‘Seq1’,’Seq2’,’Seq3’}
第二步:查找与目标序列相似的后续序列
对于每个相似序列,后续序列定义为在相似序列中目标序列最后一项发生后,减去目标序列中存在的项之后的最长子序列。
注意:这与开发人员在他们论文中的做法有所不同,但我的这种实现方式似乎比他们的更适合。
通过下面的例子来理解这一点:
目标序列= [‘A’,’B’,’C’] 相似序列= [‘X’,’A’,’Y’,’B’,’C’,’E’,’A’,’F’]
目标序列的最后一项= ‘C’
相似序列中‘C’发生后的最长子序列= [‘E’,’A’,’F’]
后续序列= [‘E’,’F’]
第三步:将相应的项添加到“计数字典”中,同时添加它们的分值。
将每个相似序列的后续项与得分一起添加到字典中。例如,继续上面的示例,随后的[‘E’,‘F’]项的得分计算如下:
计数字典的初始状态= {},是一个空字典。
如果字典中没有该项,那么:
得分= 1 + (1/相似序列的数量) +(1/当前计数字典中项的数量+1)*0.001,否则,得分= (1 + (1/相似序列的数量) +(1/n当前计数字典中项的数量+1)*0.001) * 旧分值
因此,对于元素E,即后续的第一项,得分是
score[E] = 1 + (1/1) + 1/(0+1)*0.001 = 2.001
score[F]=1 + (1/1) + 1/(1+1)*0.001 = 2.0005
经过上面的计算,计数字典为,
计数字典= {'E' : 2.001, 'F': 2.0005}
第四步:利用计数字典的值进行预测
最后,将计数字典中值最大的键作为预测值返回。在上述示例中,E作为预测值返回。
建模与预测
步骤1:复制GitHub存储库。
git clone https://github.com/NeerajSarwan/CPT.git
步骤2:使用下面的代码读取.csv文件,训练模型并做出预测。
#Importing everything from the CPT file
from CPT import *
#Importing everything from the CPT file
from CPT import *
#Creating an object of the CPT Class
model = CPT()
#Reading train and test file and converting them to data and target.
data, target = model.load_files(“./data/train.csv”,”./data/test.csv”)
#Training the model
model.train(data)
#Making predictions on the test dataset
predictions = model.predict(data,target,5,1)
尾注
在本文中,我们介绍了一种高效、准确的序列学习算法--紧致预测树。我鼓励你用序列学习黑客马拉松数据集(Hackathon dataset)尝试一下,祝你在私人排行榜上爬得更高!
如果您想要为CPT库贡献,可以自由地提出问题。如果您知道执行序列学习的任何其他方法,请在下面的注释部分中写入它们。别忘了给CPT库标注星号。
原文发布时间为:2018-05-11
本文作者:NSS
