Zhan Qin1,2, Ting Yu2, Yin Yang3, Issa Khalil2, Xiaokui Xiao4, Kui Ren1∗
1Dept of Computer Science and Engineering SUNY at Buffalo USA
3College of Science and Engineering Hamad Bin Khalifa University Qatar
2Qatar Computing Research Institute Hamad Bin Khalifa University Qatar
4School of Computer Science and Engineering Nanyang Technological University Singapore
1引言
随着图分析的进步,通过挖掘社交图可以获得很多宝贵的知识,社交图包含关于人与人之间关系和交互的信息。但是,这样的信息可能是敏感和私密的,例如,不是每个人都愿意向陌生人发布她的联系人列表。对于整个社交图可用于单个参与方的在线社交网络,存在在特定隐私保证下发布图数据[23,42,45]或分析结果[24,32,36,46]的解决方案,例如差分隐私[11]。如果图形是分散的,这意味着没有一方能够访问,问题就更具挑战性到整个图表。这发生在物理世界中的许多敏感的社交图。例如,考虑分布式社交网络,例如Synereo [27]。显然,对于这样一个图(i)每个人都有一个局部视图(例如那些与自己有直接关系的人),
和(ii)将不受限制的整个图作为单个数据集进行收集是不可行的。事实上,即使对于诸如面对面交流和电话联系等较不敏感的关系,由于人们倾向于拒绝透露私人关系,因此收集分散的社交图很困难。此外,当具有整个图表的一方(电话/电子邮件服务提供商)不与试图分析数据的研究人员合作时,社交图表(例如,电话呼叫网络或电子邮件通信)被有效地分散。在这些情况下,隐私保护图发布和分析的现有解决方案不适用,因为数据无法首先收集。
同时,很明显,通过分析分散的社交图可以提取有价值的知识,并且通过分析在线社交网络可能不容易获得这些知识。例如,现实世界中的关系(例如,我们外出的朋友)可能与在线情况(例如,我们与之聊天的ID)有很大不同,社区也是如此(例如,家长协会与游戏粉丝俱乐部) 。要获得关于分散式社交图表的知识,必须收集具有强大隐私保证的敏感本地观点。本研究侧重于根据本地差分隐私在一个真实的,分散的私人社区中生成一个综合社交图[25](在第2节中进行了解释),这是一个强大的隐私标准,已经在Google Chrome [16]和Apple iOS [2]。这样的合成图使数据科学家能够绘制意义见解,同时保护参与者和数据收集者本身免受侵犯隐私的风险。
这项研究的一个主要挑战是当地差别隐私研究的最新进展局限于收集简单的统计信息,如计数[25],直方图[16]和重击者[2]。在我们的问题中,需要使用详细的边缘级信息来收集大规模图。如稍后将会清楚的那样,以如此精细的粒度(例如,邻居列表)收集数据需要大量的噪声注入以满足局部差分隐私,这可能导致图形失真变得无用。另一方面,如果我们仅收集图统计量(例如节点度)并且仅从这些统计量生成合成图(例如,使用BTER [43]),则生成的合成图可能无法保留原始图的重要属性,除了它所产生的统计数据外,正如我们的实验所示。
在本文中,我们提出LDPGen,一种新颖的多阶段方法来生成局部差分隐私下的综合分散式社会图。一个关键的想法是,LDPGen通过在本地差分隐私下逐步识别和优化连接节点的集群来捕获原始分散图的结构。为此,LDPGen迭代地将节点分成组,在本地差分隐私下收集关于节点到组连接的信息,并根据这些信息聚集节点。获得这样的节点后集群,LDPGen应用图形生成模型,利用这些集群生成具有代表性的合成社交图。另外,我们描述了优化LDPGen的关键参数的技术,以提高生成的合成社交图的效用。
为了验证LDPGen的有效性,我们提出了一系列广泛的实验,使用了四个不同领域的实际社交图表,以及三种不同的用例:(i)社交图结构的统计分析,(ii)社区发现[5]和iii)社会建议[31]。评估结果显示,使用LDPGen生成的综合社交图获得了所有用例和数据集的高效用性,而基准解决方案在大多数情况下都无法获得有竞争力的实用程序,除了少数特殊优化的用例。
我们的主要贡献总结如下:
•我们制定了地方差别隐私下分散式社交图的合成数据生成问题。据我们所知,这是文献中第一个定义和解决这个问题的努力。
•我们描述依靠现有的本地差别隐私和合成图生成技术的秸秆手段方法,并详细分析它们的局限性。
•我们提出LDPGen,这是一种新颖且有效的多阶段方法,用于合成分散式社交图生成,并描述优化关键参数的方法。
•我们使用多个真实数据集和用例进行全面的实验性研究,结果表明LDPGen能够生成高效率的合成图。
以下第2部分提供了本地差分隐私的背景。第3节定义了局部差别隐私下合成分散式社会图形生成的问题,并讨论了两种稻草人解决方案。第4节介绍了建议的解决方案LDPGen,并证明它满足当地差别隐私。第5部分包含大量实验,第6部分回顾相关工作,第7部分以未来指导结束,蒸发散。
2本地化差分隐私
最近提出了本地化差分隐私(LDP)的概念[25],作为一种强有力的隐私措施,即使数据收集者也能保护个人的敏感信息。与经典差分隐私模型[10]的设置不同,在数据分析和发布过程中保证隐私的地方,本地差分隐私侧重于数据收集过程。具体来说,在本地差分隐私下,每个数据提供者使用随机机制局部扰乱她自己的数据,然后将其数据的嘈杂版本发送到数据收集器。在下面,我们首先提供一个简要介绍审查差异性隐私,然后在社交网络环境中引入本地差分隐私。
我们说一个随机化机制M满足ε-差分隐私,当且仅当任何两个相邻的数据库D和D'在一个记录中有不同,并且任何可能的s∈ranana(M),我们具有
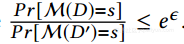 差分隐私确保从任何机制M的输出s,攻击者无法高度置信地推断输入数据库是D还是D'。隐私保护的强度由系统参数ε控制,通常称为隐私预算。显然,ε越小,M(D)和M(D')的分布越接近,因此M提供更高的隐私。
差分隐私确保从任何机制M的输出s,攻击者无法高度置信地推断输入数据库是D还是D'。隐私保护的强度由系统参数ε控制,通常称为隐私预算。显然,ε越小,M(D)和M(D')的分布越接近,因此M提供更高的隐私。
差分隐私最初是为集中式设置而设计的,其中可信数据管理员使用多个用户的确切数据记录处理数据库,并使用随机机制从数据库发布扰乱的统计数据或其他数据分析结果。在本地差分隐私设置中,
这是本文的重点,数据馆长不信任;相反,每个用户使用不同的私人机制在本地扰乱她的数据。在此设置中,输入数据库D只包含单个用户的数据。什么构成D的邻近数据库D'取决于用户数据的类型和隐私保护的目标。例如,用户的数据可能是她浏览器的主页[16]。由于用户不希望数据收集器以高置信度推断她的真实主页,所以不管该主页是什么,邻居数据库将是任何其他任意网站。在这种情况下,对于机制M来满足局部差分隐私,它需要确保对于任何两个网站w和w'以及对于任何s∈ranana(M),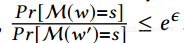
在社交图的背景下,根据隐私要求,可以设计隐私机制来满足边缘差分隐私[4]或节点差分隐私[26]。该
前者确保随机化机制不会揭示个体的特定边缘的包含或移除,而后者隐藏包含或移除节点及其所有相邻边缘的节点。对于本地差分隐私,我们有以下正式定义。令U = {u1,...。 。 。,un}是社交网络中所有用户的集合。用户u的邻居列表可以表示为n维位矢量(b1,...,bn),即,bi = 1,i = 1,...。 。 。,n,如果并且只有在社交图中存在边(u,ui)的情况下;否则bi = 0。
定义2.1(节点本地差分隐私。)。随机化机制M满足ε节点局部差分隐私(ε节点
LDP)当且仅当对于任何两个邻居列表γ和γ'以及任何Pr [M(γ)= s]ε。
s∈ranдe(M),我们有
定义2.2(边缘本地差分隐私)。当且仅当对于任意两个邻居列表γ和γ',使得γ和γ'仅在一个比特上不同时,随机化机制M满足ε-边缘局部差分隐私(ε-边缘LDP),并且任意s∈ranдe(M ), 我们有
局部差分隐私也是可组合的:给定机制Mi,i = 1,...。 。 ...,t,它们中的每一个满足εi-边(或节点)局部差分隐私,Mi(v)的序列满足Íit=1εt-edge(节点)本地差分隐私。
节点LDP显然比边缘LDP更强大的隐私保证(实际上节点LDP意味着边缘LDP)。例如,我们将在后面看到,在边缘LDP下,用户仍然可以以合理的准确度显示她的学位,即使在隐私预算相当大的情况下,在节点LDP下也几乎不可能。根据应用和社交图谱的性质,一个隐私模型可能比另一个更合适。例如,在收集用户的联系人列表时,边缘LDP就足够了,因为用户通常不介意分享她的联系人数量。她想要保护的是她的联系人究竟是谁。对于其他一些社交图(例如性关系图),甚至用户的程度可能高度敏感,因此应该采用节点LDP。我们注意到节点LDP的强大隐私保证在实用性方面具有很高的价格。即使在全球隐私设置中,节点差分隐私难以实现,而对社交图数据的效用没有显着的负面影响[26]。在本地隐私设置中这样做会更具挑战性。在本文中,我们专注于实现边缘LDP和设计技术以促进社交图分析
3问题描述和直观的方法
考虑一个分散的社交网络,用户U = {u1,...。 。 。,un}。
不失一般性,我们假设G是一个有向图;对于无向图,我们简单地将边无向边视为两个有向边。每个用户都在本地维护一个邻居列表,如前所述,它可以建模为一个n维二进制向量。我们的问题在于设计技术,使得(i)不受信任的数据馆长能够在满足边缘本地差别隐私的同时从每个个人用户收集信息; (ii)从收集的数据中,数据管理者能够构建G的代表性合成图。合成图的代表性可以从不同的角度反映出来,我们将在第5节中详细讨论。注意,这项工作着重于由于在LDP边缘下问题已经非常具有挑战性,因此边缘LDP定义较弱。即使在集中式设置中,节点差分隐私也非常困难,并且它可能不会在我们的目标应用程序(如社区发现)中产生有意义的效用。因此,我们将节点LDP作为我们未来的工作。
在下文中,我们将讨论两种基于现有局部差分隐私和合成社交图生成技术的简单解决方案。
3.1随机邻居列表方法
实施本地差分隐私的常用方法是随机响应[13]。我们的第一个非常直观的方法,即随机邻居列表(RNL),直接应用随机响应来收集用户的邻居列表。具体而言,在RNL中,在给定隐私预算ε的情况下,每个用户以概率p = 1 +1eε翻转其邻居列表中的每个比特,并将扰乱的邻居列表发送给数据管理者。后者然后将来自所有用户的噪声邻居列表组合在一起以形成综合社交图。
定理3.1。随机邻居列表方法满足ε-边缘局部差分隐私。
证明。将随机邻居列表机制表示为M,并且将Pr [x→y]表示x∈{0,1}变为ε的概率
在随机位翻转之后y∈{0,1}。让qeε。由于ε> 0,我们有q> p。
假设γ=(b1,...,bn)和γ'=(b1',...,bn')是仅在一个比特中不同的两个邻居列表。不失一般性,假设b1,b1'。给定任何来自M的输出s =(s1,...,sn),我们有
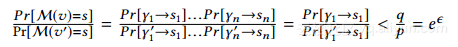
尽管RNL实现了我们的隐私目标,但其生成的合成图并不能很好地代表原始的分散式社交图。一个明显的问题是,它往往会返回比原来更密集的图。一般来说,真实的社交图往往是稀疏的:即使有众多关联的中心用户的程度与社交网络的整体人口相比也要小得多。因此,真正的邻居列表通常比1更多。然而,在随机位翻转之后,即使隐私预算相对较大,1的数量也会显着增加,从而导致合成图的密度更高。特别是,如果原始图的密度为r,则在应用随机邻居列表方法之后,所获得的合成图的期望密度变为(1-p)r +(1-r)p。考虑一下
安然电子邮件图(详见第5节),其原始密度为0.01%。即使有相当小的翻转概率p = 0.01,邻居列表随机化后图的预期密度将变为2%,增加200倍。
3.2基于度的图生成方法
在社会计算文献中,已有许多现有的合成社交图生成算法,如Erdos-Renyi [14],Chung-Lu [1]和BTER [43]。通常,这样的算法将一些图形统计信息(如节点度,
并基于社交图模型生成合成图。换句话说,该算法以图模型的形式引入关于社交图的先验知识,并将这些知识适配到输入图的高级结构特性。基于度的图生成(DGG)的想法是将这样的社交图生成模块应用于我们的问题。
请注意,并非所有合成社交图生成算法都可以应用于我们的问题。原因在于,在我们的设置中,每个用户仅以邻居列表的形式具有有限的局部视图。另一方面,一些图生成算法需要整个图的全局信息,例如克罗内克图模型[28]中的邻接矩阵的子矩阵。因此,这种算法不能用于DGG。我们对DGG的实施基于BTER [43]的改编版本,如下所述。
使用DGG,每个用户计算她的节点度,扰动ε边缘差分隐私下的度数(例如,使用拉普拉斯机制[10]),并将产生的噪声度发送给数据管理员。后者收集来自所有用户的这种扰动程度,并运行BTER算法以生成合成图。具体而言,BTER首先根据其程度形成节点群集。特别是,具有相似程度的节点聚集在一起。集群的大小也取决于节点的度数它:节点度越大,簇大小越大。之后,对于每个群集,BTER会生成随机的群集内边缘,其数量取决于群集中的节点度数和连接参数,由于缺少全局图统计信息,因此该参数在DGG中设置为默认值。最后,BTER根据每个节点的剩余程度和每个群集的大小生成群集间边缘。
DGG明确地满足了我们的隐私要求,因为每个用户只将她的扰动程度发送给策展人,该策展人在ε-边缘本地差分隐私下随机化。同时,对于相当大的ε值,扰动程度预计接近其真实值,因为用拉普拉斯机制注入的噪声1有一个方差[11]。因此,合成图生成ε2
DGG准确捕捉节点度。但是,由于DGG仅收集节点度数,因此会丢失底层图形的所有其他信息。例如,具有相似程度但在原始图中相距很远的两个用户可以被放置在合成图中的相同群中。此外,DGG通常不能捕获除节点度外的图结构的其他方面,正如我们在第5节中的实验中所示。
3.3观察
我们观察到,上述的两种非常直观的方法RNL和DGG代表了数据收集的两个极端:RNL收集细粒度信息(即邻居列表),并支付满足当地差别隐私所需的重扰动的价格。另一方面,DGG仅仅精确地收集粗粒度统计量(即节点度),因为它们只需要少量噪声来满足局部差分隐私,但是它也丢失了底层图的重要细节。另一个有趣的观察结果是,DGG引入了关于社交图的先验知识,而RNL则没有。
上述观察表明,需要在加入噪声以满足不同隐私之间取得平衡,并且由于以较粗粒度收集信息而导致信息损失。一个棘手的问题是,这种平衡本身是依赖于数据的,因此可能会泄露私人信息。接下来描述的所提出的方法LDPGen在边缘局部隐私约束下迭代地发现这样的平衡。此外,与DGG类似,它利用社会图的先验知识来增强合成图。
4 LDPGEN
第4.1节概述了拟议解决方案LDPGen的总体框架,涉及三个阶段。 4.2-4.4节分别实例化这三个阶段。 4.5节证明LDPGen符合我们的隐私要求。 4.7节提供了关于LDPGen算法设计的额外讨论。
4.1总体框架
LDPGen基于以下想法。假设我们有一种方法将社交图中的所有用户划分为k个不相交的组ξ= {U1,..., 。 。,Uk}。那么对于每个用户,我们可以定义一个度向量δu=(δ1u,...,δku),其中δiu(i = 1,...,n)是Ui中u个邻居的数量。例如,考虑到所有用户被分成两个不相交的组U1和U2。假设用户u与U1中的节点(或U2)有5(7)个连接。那么,u的度向量是(5,7)。显然,如果两个用户的邻居列表相似,那么他们的度量向量也是如此。因此,数据管理者可以使用局部差异私人机制收集每个用户的度数矢量,并使用这些矢量生成合成图。
事实上,第3节中描述的两种非常直观的方法RNL和DGG都可以看作是上述总体框架的极端情况。特别地,当每个分区仅包含一个用户时(即,当k = n时,其中k和n分别是图中的分区和用户的数量),RNL处于一个极端。同时,当整个图被认为是单个分区(即k = 1)时,DGG处于相反的极端,并且每个节点的度向量退化为单个节点度。如第3节所述,两种方法都不理想:RNL会产生过多的噪音,而DGG则会造成过度的信息损失。 LDPGen遵循相同的总体框架,并通过选择适当的用户分区方案在噪声和信息损失之间取得良好的平衡。
然而,选择合适的用户分区方案的主要挑战是最好的用户分区方案取决于数据集:直观地说,类似的用户应该组合在一起。这导致循环依赖:(i)收集数据,我们必须知道k的值和分区方案; (ii)决定k的最佳值,我们必须首先收集数据。 LDPGen通过多阶段设计解决了这个问题。特别是,在LDPGen中,数据管理员可以多轮收集用户的数据;每一轮细化用户划分方案,然后以更高的准确度再次从用户收集数据以用于下一轮,例如通过使用隐私预算的较大部分。通过这个过程,结构紧密的用户将逐渐分组在一起。
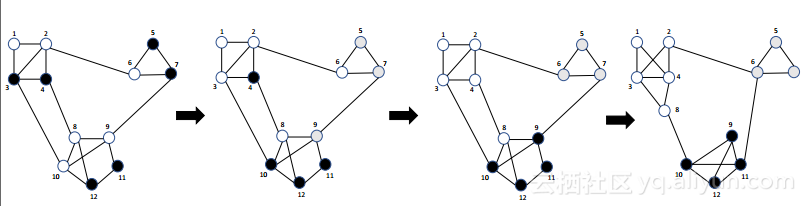
图1 LDPGen算法样例分析
一旦获得了良好的分组,LDPGen就会应用社交图生成模型来生成综合社交网络。图1举例说明了LDPGen,其中用户分为三组,分别用黑色,白色和灰色。最初,分组是相当随机的,并且只有两个组,而图中可以观察到三个用户簇。之后,分组被细化,因为(i)用户被划分成3个组而不是2个,并且(ii)相似的节点逐渐移动到相同的集群。
具体而言,我们的LDPGen设计由三个阶段组成:初始分组,分组细化和图形生成。该
前两个阶段涉及从用户收集数据。我们分别为每个阶段分配隐私预算ε1和ε2,使得ε1+ε2=ε。由于差分隐私的序列组合性质[11],这两个阶段一起满足ε边缘LDP。 ε1和ε2的选择将在4.7节中讨论。图生成阶段是边缘LDP机制输出的后期处理,因此不会消耗任何隐私预算。
阶段I:初始分组。在这个阶段,数据管理者没有关于图结构的任何信息。因此,它将用户随机分为k0个相同大小的组(其中k0是系统参数,将在4.7节进一步讨论),并将此分组方案ξ0传达给所有用户。数据管理者和用户之间的高效通信将在4.7节中进一步讨论。之后,每个用户根据ξ0形成她的度向量,根据为阶段I分配的隐私预算ε1添加噪声,并将噪声度向量发送给数据馆长。一旦数据管理者从所有用户那里收到噪声度矢量,它就使用(i)从收集的度数矢量中获得的所有用户的估计度分布和(ii)隐私预算,计算具有k1个分区的新分组方案ξ1 ε2分配到阶段II。请注意,与初始分组不同,新分区的大小可能不同。
这个新的分区ξ1被传回给用户。第二阶段:分组细化。在这个阶段,用户现在再次报告基于ξ1的噪声度向量以及为阶段II分配的隐私预算ε2。数据管理员进行另一轮用户分组,并根据用户的第二轮噪声程度向量将用户划分为k1个簇。请注意,阶段II可以重复多次,每次都会根据前几轮收集的程度向量逐步细化分组。这个问题将在4.7节中进一步讨论。
第三阶段:图形生成。在这一步中,数据管理者根据BTER模型生成合成社交图。与在DGG中用户仅基于其度数进行聚类的情况不同,在LDPGen中,数据管理员从阶段II中获得的用户分区开始,并使用收集的度向量生成边缘。在图1的例子中,LDPGen以阶段I(最左边)的用户随机划分为k0 = 2个组开始。然后,数据管理者从用户收集度数矢量,并根据(第二左)细化用户分组。之后,在第二阶段,用户分组再次进行另一轮数据收集。最后,在阶段III(最右边)中,基于用户分组和度向量生成合成图。接下来,我们详细介绍每个阶段的设计。
4.2阶段I的设计
如上所述,数据管理者首先将所有用户随机分为k0个相同大小的组。我们称这个分区为ξ0。然后每个用户u基于ξ0计算她的度矢量δu=(δ1u,...,δku0)。为了确保边缘LDP,你加入每个δiu,i = 1,...。 。 。,k0一个随机
从拉普拉斯分布Lap(0,ε11)中提取噪声,其中ε1是分配给阶段I的隐私预算。令得到的噪声度向量为(δ〜1u,...,δ~ku0),其与数据馆长。
直观地说,由于这些k0组不重叠,因此向用户添加或删除一个边缘会在其度数矢量中正好改变一个δiu的值1。由DP [11]的并行组合特性,共享(δ〜1u,...,δ~ku0)仍然满足ε1-边LDP。我们
请在第4.5节中提供此隐私保证的正式证明。
从噪声度矢量中,数据管理者为u导出一个无偏度的估计量η:
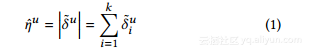
第一阶段的主要任务是为下一阶段提供一个良好的用户分组。为此,我们需要确定(1)适当的组数k1; (2)如何将用户划分为k1组。为了解决第一个问题,我们需要定义一个目标函数,其优化将导致保存一个图的结构信息。回想一下,社交网络最重要的信息之一是其社区结构。因此希望确保具有相似(不相似)邻居列表的节点在分区之后仍然可能具有相似(不相似)的度向量。测量两个向量的相似度有许多方法。在我们的设计中,我们选择L1距离作为相似度函数。
为了便于分析,考虑具有相同程度的两个用户u和v(即,ηu=ηv),并且让du,v,du,v和d〜u,v表示L1
它们的邻居列表,度矢量和噪声度矢量之间的距离(以及当上下文清晰时用于简化符号的d,d和d〜)。为了确保两个用户在分割和噪声扰动后保持相似性(不相似性),噪声度向量d〜之间的期望L1距离和邻居列表d之间预期的L1距离应该接近。
因此,我们将目标函数定义为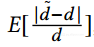 即,期望d〜和d之间的相对误差。
即,期望d〜和d之间的相对误差。
在本小节的其余部分,我们提出一个分析,将组数k1与目标函数相联系,然后扣除使目标函数最小化的近似最优k1值。
目标函数分析。在展示我们的分析之前在目标函数中,我们详细阐述了度向量的一个性质:很容易看出,如果u和v的两个不同的邻居被划分到同一个用户组中,他们对度向量的L1距离将被相互抵消。因此,度向量之间的L1距离总是小于原始邻居列表的L1距离,即d≤d,因此| d-d | = d - d。基于这个属性,我们有: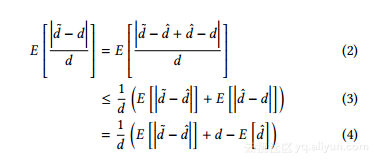
从方程式中扣除 2到3是基于三角不等式。
由等式 4,目标函数由公式(4)从上面限定。
在下面,我们将首先分析h i之间的关系k1和E d〜-d,即代表由所引入的误差拉普拉斯噪声扰动。
LaplaceNoisePerturbationAnalysis。 由三角形不等 - 我们有
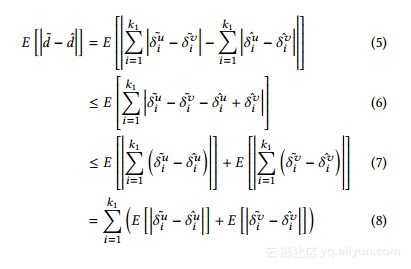
观察δ_iu遵循拉普拉斯分布Lap(δiu,ε12)。AC-因此,其平均绝对偏差是:
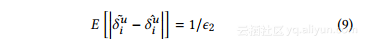
因此,等式的右边。 8等于2k1。 综上所述,给出ε2相应噪声注入过程的隐私预算ε2,引入度矢量(或拉普拉斯噪声变量之和)的预期误差为:
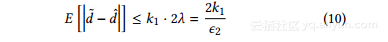
度向量转换分析。接下来,我们分析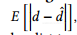 ,即通过变换近邻点引入的误差,
,即通过变换近邻点引入的误差,
bor列表到度矢量。注意到u和v的共同邻居对它们之间的L1距离没有任何影响
度向量。因此,我们只会关注不同的邻居.在我们对
的分析中,
u
和
v
的
bors
。可以证实这些邻居的数量应该等于
d
。
假设所有用户随机分成k1个组。设θd表示分割d个用户的方式的数量。我们有

其中S(n,k)是第二类斯特林数(或斯特林分区数)。
令θd= t表示d = t的分区数。很容易看出两个度向量之间的L1距离相等
θd= t,并且以度向量之间的概率θd的L1距离t的期望为:

我们现在关注θd= t的推导。我们首先考虑两个与u和v相连的不同邻居。如果这两个邻居分配到同一个用户组中,它们对度向量L-1距离的贡献就是0,即它们相互“抵消” 。给定d和t作为邻居列表和度向量之间的L-1距离,“取消”邻居对是d-t,以及从每个邻居中选择d-t个邻居的方法的数量用户进一步配对是d / 22。此外,通过枚举t / 2所有可能的组合,我们可以推导出,将两个用户的这些取消邻居配对的方法的数量是·d-t!,并且在那里有k1种方法可以在k1组中分配它们。
同时,如果两个不同的邻居被分配到不同的组,他们对L1距离的贡献将是2,并且有t / 2个这样的节点对。类似于上面的推导过程,给定相邻列表之间的L1距离d和度向量之间的L1距离t,方法来选择相应的“不取消”对。另外,对于任何dis-由k1分区产生的t分布,有k21t / 2种方式在k1个分组之间分配这些对。
结合上面的分析,我们得到导致度向量距离t的分区数量为:
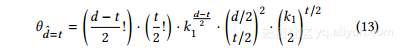
替代Eq。 11和13进入方程如图12所示,我们可以推导出它们的度向量之间的期望的L1距离是:
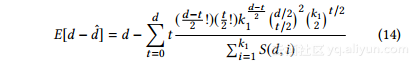
最佳组数推论:最后,我们把上面的内容一起导出组数k1的最佳值的近似值。
首先,我们用方程10和14进入方程4并获得:
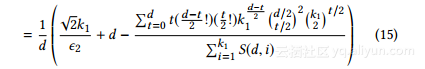
方程式中的最后一项。 15没有封闭的形式。幸运的是,通过将dx,y和k1限制在一个范围内(例如,0到50之间,这适用于大多数社交网络),我们可以得到一个很好的近似闭合形式,如下所示:
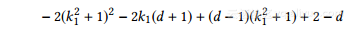
用等式16进入方程15,我们可以得到一个封闭的形式目标功能:
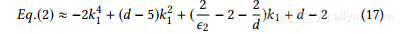
当ε2d时,17被最小化
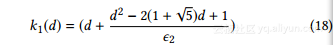
此外,对于具有相同度η的节点,我们使用下式来估计它们潜在的L1距离d:

给定图G的度直方图H = {pη},其中pη是具有度η的节点的百分比,我们可以推导G的k1值的一般近似值为:
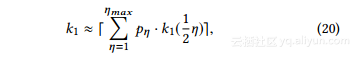
其中ηmax是H中的最大节点度数。注意,我们的分析可以适用于上述两个参数大于50的情况,但该公式将包含许多附加项。为了可读性,我们省略了这些案例的讨论。
在推导出合适的k1后,数据管理者可以简单地将所有用户随机分为k1个相同大小的组。但是,我们观察到,如果两个用户在阶段I中报告的噪音程度向量相似,则他们更可能在结构上相似。因此,如果我们根据它们的噪声度向量而不是随机地对节点进行分组,它可能有助于进一步识别阶段II中的结构紧密的节点。具体来说,在我们的设计中,数据管理者运行标准k-均值算法,根据所有用户的噪声程度向量将用户分成k1组。结果聚类形成下一阶段的分区ξ1。
4.3阶段II的设计
考虑到阶段I的用户分组ξ1,每个用户使用隐私预算ε2再次向数据管理者报告新的噪声程度向量。第二阶段数据管理者的任务是完善用户群。直观地说,由于分区ξ1具有最佳大小,并且更可能将具有相似结构的用户组合在一起(通过
k均值聚类),这一阶段报告的噪声程度向量将有助于进一步揭示分散式社交网络的结构。这是通过基于第二阶段开始时从所有用户新报告的噪声程度向量执行另一轮k均值聚类完成的。请注意,目标聚类的数量仍然是k1,即在第一阶段导出的近似最优值。我们称之为新的分区ξ2。
4.4第三阶段的设计
为了基于ξ2中的用户群生成合成图,数据管理者需要一种方法来估计每个群内的群内边缘以及不同群之间的群间边缘。这可以通过要求用户报告给定ξ2的噪声程度向量来完成。但是,如前所述,这会导致隐私预算在每个阶段进一步分裂。相反,我们的设计使用用户的噪声度向量来从阶段II的分区ξ1估计ξ2的阶向量。具体来说,令δ〜u =(δ〜1u,...,δku〜1)为用户u的ξ1= {U11,..., 。 ,Uk11}。给定ξ2= {U12,...。 。 。,Uk21},我们估计你的
ξ2中的一个组Ui2为:
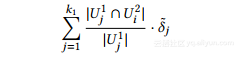
实质上,对于每个组Uj1,我们检查它的哪一部分也是ap-梨Ui2,我们估计你的Uj1的比例噪声程度到那个Ui2。
基于每个用户的估计度矢量,我们在合成图中的节点之间生成边。将δiu表示为对Ui2的估计程度。类似于着名的中青旅,Lu模型[1],我们计算分别连接属于组Ui2和Uj2的两个节点u和v的概率如下:
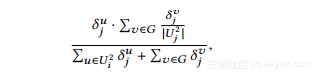
其中分母是组i和j之间的边的总数,通过聚合两组中的节点的相应度向量中的所有元素。
4.5隐私分析
这里我们表明LDPGen满足ε-边缘局部差分隐私。令(δ1,...,δk)为给定分区ξ的u度矢量。
回想一下,向数据管理器报告的噪声程度向量是(δ〜1,...,δ〜k),其中δ〜i =δi+ N,对于i = 1,..., 。 。,k和N是拉普拉斯分布Lap(0,e1)之后的一个随机变量。表示这一点机制为M.
定理4.1。上述噪声度向量机制M满足ε-边缘局部差分隐私。
证明。给定两个邻居列表γu和γv,让δu=(δ1u,...,δku)和δv=(δ1v,...,δkv)为它们对于分区ξ的对应度向量。如果γu和γv恰好在一个位上不同,由于ξ是一个分区,很容易看出δu和δv在一个元素上是不同的。不失一般性,假设v。此外,我们有|δ1u - δ1v| = 1.给定任意向量s =(s1,...,sk)∈ranдe(M),我们有:
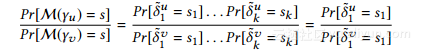
由于|δ1u - δ1v| = 1,根据Lap的PDF),我们有
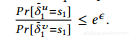
在LDPGen中,用户将噪声添加到她的学位向量中第一阶段和第二阶段分别为Lap(0,ε11)和Lap(0,ε12)。应有到边缘局部差分隐私的可组合性,由于ε1+ε2=ε,LDPGen的整体过程满足ε-边本地差分隐私。
4.6复杂性分析
关于通信复杂性,两种草帽人手段只需要用户和数据管理者之间的一轮通信。由于每个用户需要将一个潜在的大邻居列表传送给管理员,所以第一个吸管人员方法RNL在用户端成本最高,即O(n)。由于每个用户只需要向数据管理者报告他/她的学位,所以第二个稻草人DGG的成本更低,即O(1)。所提出的方法LDPGen涉及用户和数据管理者之间的两轮通信:在第一阶段,每个用户需要发送一个大小为k0的度矢量给数据管理者;在第二阶段,数据管理者首先将用户分区广播给每个用户,即O(n),然后每个用户发送一个大小为k1的度矢量给数据管理员。显然,LDPGen不可避免地比仅需要单轮通信的秸秆方法产生更高的成本,并且LDPGen的高准确度弥补了这种成本。
关于计算复杂度,无论是稻草人还是LDPGen方法,在用户端的计算开销都很低,这也是这类调查应用的重要设计目标。同时,在数据馆长一方,由于数据管理者需要一次性考虑节点之间每条边的概率,所以两种方法在生成合成图时的计算开销为O(n2),而LDPGen方法具有O(n2 + n(k0 + k1))的成本,这比非常直观的方法略高。
4.7讨论
回想一下,LDPGen的第二阶段通过根据用户新报告的噪声程度向量对用户进行重新聚类来优化第一阶段的分区。从技术上讲,我们可以继续这个过程,并进行更多轮次的分组细化,而不是在第二阶段停止。但是,我们拥有的轮数越多,每轮可以使用的隐私预算越少,这意味着需要将更多的噪音添加到度量向量中。这实际上可以减少而不是提高分组的质量。在第5节的图10中,我们通过实验显示了多轮分区细化对生成的合成图的效用的影响。
另一个问题是在前两个阶段分配隐私预算。在我们的实现中,我们选择均匀分割ε,即,
1 =ε2,基于两个阶段用户报告相同类型信息的直觉,并且倾向于对最终用户群集具有相同的影响。
在第一阶段,在收集用户的任何信息之前,数据管理员将所有用户随机分为k0个相同大小的组。
回想一下,基于这个随机分区的用户的噪声度矢量有两个目的。首先,数据管理者用它来估计用户的程度(回忆式1)。其次,它稍后也可用作特征向量来对所有用户进行聚类。为了获得最佳度数估计值,k0应该设置为1.然而,这意味着后面的聚类只有基于度才是必不可少的,如前面讨论的那样,这是不可取的(3.2节)。在我们的实现中,我们设置k0 = 2来达到直观的平衡。
在我们迄今为止的讨论中,我们隐含地假设数据馆长意识到分散式社交网络中的所有用户。这个假设是否成立取决于网络的具体情况。例如,如果社交网络涉及不同IP之间的通信,则所有IP的域都是公知的。当用户选择进行研究时,数据馆长也可能首先查询他们的社交网络ID,而这些ID不是(例如,他们的联系人列表网络的电子邮件地址)。当用户的社交网络ID无法直接显示时,他们可以改用其ID的哈希值与数据馆长进行交流。通过这样做,未知的用户ID空间被映射到定义良好的散列空间。我们的方案可以应用于这个散列空间。另外,馆长可以使用布鲁姆过滤器等压缩技术来广播用户组分区,以降低通信成本。
5实验评估
我们已经实施了LDPGen并运行了一套全面的实验来研究其有效性。特别是,我们的实验将LDPGen与第2节中描述的两种非常直观的方法RNL和DGG进行比较。同时,实验还研究了阶段1中的组数k1的影响(在4.2节中描述),以及LDPGen是否获得此参数的适当值。对于每个实验,我们报告10次执行的平均结果。实验涉及四个真实的社交图表,这些图表已被用作社区检测和推荐任务的基准数据集。他们是:
Facebook [30]是一个无向社交图,由4,039组成
使用Facebook应用程序从调查参与者收集的节点(即用户)和88,234边缘(Facebook上的连接)。
•安然[29]是一个无向电子邮件图,由36,692个节点(即安然的电子邮件帐户)组成,由183,831条边(电子邮件)连接。
•Last.fm [3]包含社交图和偏好图。
社交图由1,892个用户节点和12,717个代表朋友关系的无向边组成。偏好图包含相同的一组用户节点,以及17,632个项目节点,每个节点对应于一首歌曲。偏好图中的每条边连接用户和歌曲,权重对应于用户收听歌曲的次数。总共有92个,198个这样的直接用户到歌曲边缘。
•Flixster [21]还包含一个社交图和首选图,与Last.fm类似。在经过一些预处理(下面解释)之后,社交图包含通过1,269,306个无向边连接的137,372个用户节点,并且偏好图包含相同的一组用户,48,756个项目节点和超过700万个定向的用户到项目边缘。这里,每个项目节点表示电影,并且每个用户到项目边缘对应于由相应用户评级的与权重相关联的电影评级,即,范围为[0,5]中的评级。
由于我们需要基础事实来验证LDPGen的有效性,因此实验大多使用集中式社交图。在这些数据集中,安然包含电子邮件通信,通常将其建模为分散数据,因为通常没有服务器具有所有用户之间的所有电子邮件通信。
综合社交网络的实用性取决于它在不同应用中的用途。在我们的实验中,我们使用三种用例来验证LDPGen的有效性,如下所示。
•社交图统计。作为最简单的用例,我们使用Facebook和Enron数据集来调查在局部差分隐私下生成的合成社交图是否保留了原始图结构的重要统计数据(详见5.1节)。
•社区发现。在第二个用例中,我们执行
社区发现原始和生成的合成图,并使用Facebook和Enron数据集比较结果。具体来说,我们的实现使用Louvain方法[5]进行社区发现,输出用户群列表。然后,我们比较从两个常用度量ARI和ARI上的真实和合成图获得的用户群AMI,在5.1节解释。
社交推荐。 在第三个用例中,我们使用Last.fm和Flixster数据集来研究如何将生成的合成图有效用于社会推荐•应用。 具体而言,我们假设社交图是私密的,并且偏好图是公开可用的(例如,当用户评价a电影,评级是公开可见的)。 然后,对于每个用户,我们推荐基于她朋友的项目偏好的top-k项目列表。 评估比较从真实和合成图计算出的建议项目清单。 社会推荐算法背后的详细推理可以在[31]中找到。
以下第5.1节描述评估指标; 第5.2节介绍主要评估结果; 5.3节讨论了LDPGen中的参数选择,特别是LDPGen是否能够为阶段I中的组k1选择合适的值。
(a) facebook (b)Enron
图2 epsilon对模块度的影响
5.1评估指标
如上所述,实验着重于效用的三个方面:图表统计的保存,社区发现的准确性以及推荐系统的有效性。首先,就图形统计而言,我们评估LDPGen及其竞争对手的图形模块性[19],聚类系数[48]和分配系数[18]。三者中的每一个都反映了结构并且在实践中有许多应用[7]。为简洁起见,我们省略其详细定义。
关于社区检测,效用度量关注于从生成的合成图和从原始图获得的社区的相似度。为此,我们遵循标准指标调整随机指数(ARI)[40]和调整互信息(AMI)[44],如下所示。
定义5.1(ARI和AMI)。给定一组N个元素G ={n1,...,nn}以及G,X = {x1,...,xr}(将G划分为r个子集)和Y = {y1,...,ys} G代入子集),X和Y之间的重叠可以概括为一个列联表,其中每个条目nij表示xi和yj之间共有的对象的数目:nij = |Xi∩Yj|,1≤i≤r ,1≤j≤s。令ai(或bj)为应急表中第i行(或第j列)的和,即ai =Íjnij和bj =Íinij。定义ARI和AMI如下:
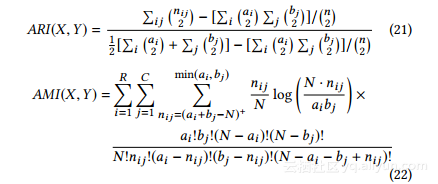
其中(ai + bj-N)+表示max(1,ai + bj-N)。
直观上,ARI量化了所有元素对之间所获得的两个聚类之间的一致性频率,并且AMI量化了两个聚类共享的信息。 ARI和AMI都对两个完全随机聚类之间的测量进行了折扣[6,35]。 ARI和AMI的较大值表明潜在的聚类更相似;在我们的实验中,比较真实和合成图上获得的结果更高
ARI / AMI值意味着更高的准确性。
最后,就社会推荐的有效性而言,我们将实用程度评估为从原始计算得到的推荐项目的相似度,以及从合成图表中获得的推荐项目的相似度。具体地,用于向用户u推荐项目i的分数μui被定义为:
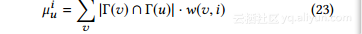
其中v是另一个任意用户,Γ(u)表示在社交图中与u直接相连的节点集合,w(v,i)是连接用户u和项目i的偏好图中的权重。
然后推荐系统向每个用户推荐一个关于u的分数最高的k项目列表。为了比较两个不同的top-k项目列表,我们使用归一化折扣累积增益(NDCG)[22]作为准确性度量,这是推荐系统有效性的常用度量[34]。具体来说,排序列表之间的NDCG分数定义如下。
定义5.2(NDCG)。给定两个排名列表的frankst和给定排名表中的项目vi,我们将其相关性评分定义为:
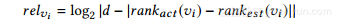
其中rankact(vi)(或rankest(vi))返回排名列表rankact中的第vi项的排名(直接地,更接近vi的估计的排名是其实际排名,相关性分数越高。鉴于实际的前k项v1,。 。 vk,估计等级列表的折扣累积增益(DCG)最先计算为:
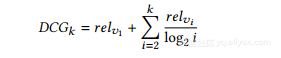
折扣因子log2(i)将给予更高等级项目的收益更多的权重。基本上,我们更关心重要项目(排名较高的项目)的正确排名。最后,通过与理想的DCG(IDCG)进行比较,我们将估计的排名列表的DCG归一化,当估计的排名列表与实际完全相同时(即,没有估计误差),其为DCG:
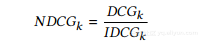
然后将合成图与社会推荐用例的总效用计算为平均值
NDCG对数据集中所有用户的集合进行评分。
5.2 LDPGen的实用程序
在本小节中,我们研究了LDPGen与两种非常直观的方法RNL和DGG相比较的效用。在所有实验中,最佳组数k1由数据管理员按照4.2中的描述进行计算。第5.3节将进一步研究k1的影响以及LDPGen的选择是否合适。
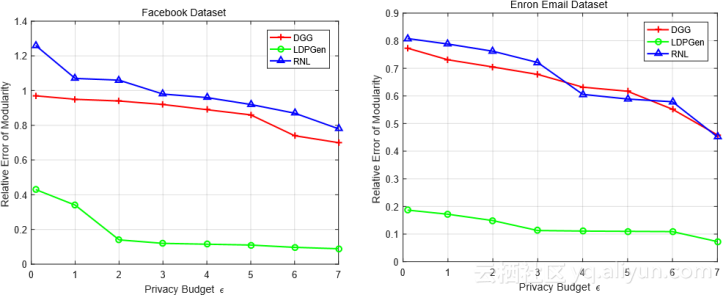
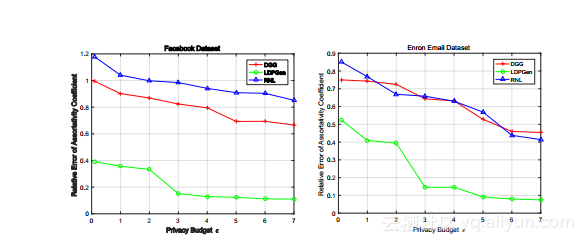
图结构统计的结果。图2a绘制了rel-使用Facebook数据集,提出的解决方案LDPGen和两个非常直观的方法RNL和DGG的误差,作为隐私预算ε的函数。在所有设置上,LDPGen都比RNL和DGG显示出明显的优势。特别是,除非我们使用非常高的ε值,即ε> 5,否则RNL和DGG的相对误差接近100%,这意味着它们的模块性结果在这些设置下是无用的。另一方面,当ε≥2时,LDPGen实现了较低的相对误差(<20%)。注意,这些ε值已经在局部差分隐私文献中普遍使用,例如[16,39]。这表明LDPGen在局部差分隐私下获得了模块化方面实际上有意义的结果。同时,LDP在极端ε值(即,当ε接近0并分别达到7)时也实现了对RNL和DGG的显着性能改进。这表明LDPGen在广泛的ε值上具有优于其竞争对手的内在效用优势。
图2b在安然数据集上重复上述实验。
同样,LDPGen在所有设置上都大大优于RNL和DGG,其差异在于实际准确度(LDPGen在所有设置上的相对误差小于20%)和无用结果(RNL和DGG相对误差> 60%,当ε< 5)。这证实了LDPGen相对于RNL和DGG的性能优势是固有的,而不是依赖于数据。比较Facebook上的结果和安然,我们观察到(i)所有三种方法在安然上获得比Facebook更高的效用。一个原因是安然是一个很大的比Facebook更大的数据集;因此,注入的噪音满足当地差别隐私在后面的数据集上更加明显。 (ii)尽管RNL在Facebook上的表现略好于DGG,但其在安全方面的表现与RNL相当,这表明两种稻草人手段的相对表现取决于数据集。
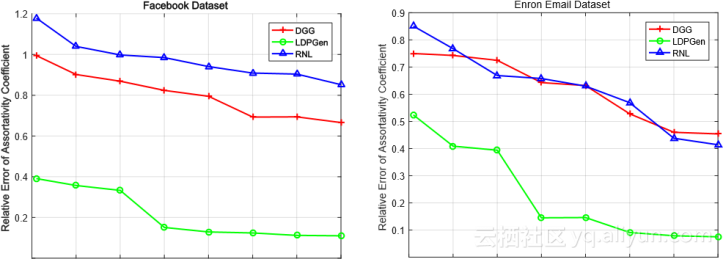
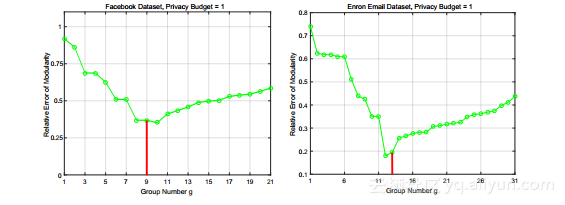
图3a和3b根据所生成的合成图的聚类系数的相对误差评估LDPGen,RNL和DGG的效用,使用Facebook和Enron数据集,spectively。 DGG在所有设置中获得最佳精度。这是预料之中的,因为DGG基于BTER算法(草绘在英寸中)第6节),它专门为返回精确的聚类系数而优化[33]。值得注意的是,LDPGen在所有环境中的准确度都接近于DGG的准确度,而RNL导致远低于其他两种方法的效用。
图4a和4b根据所生成的合成图中图形分配系数的相对误差显示效用结果。结果导致与模块化(图2a和2b)类似的观察结果,即LDPGen达到实际的准确性,而RNL和DGG导致无用的结果。这表明
这两种秸秆解决方案的效用非常低,除了它们专门针对优化的统计数据(例如,用于聚类系数的DGG)之外。另一方面是LDPGen的表现
(1) facebook (2)Enron
图3 Epsilon对聚类系数的影响
在所有度量标准中,在两个数据集上以及隐私预算ε的所有值下始终保持高水平。
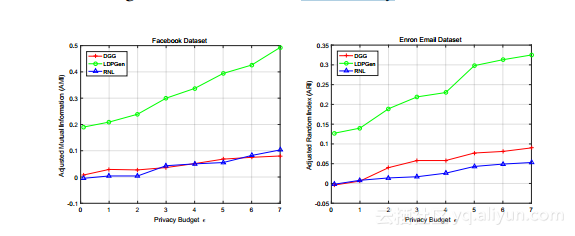
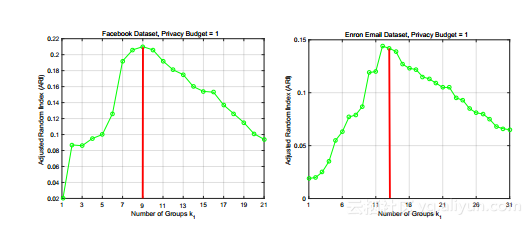
社区保护结果。在我们的第二套“我们评估了LDPGen,RNL和DGG生成的合成图如何在原始图中保留社区信息,使用第5.1节定义的两个度量ARI和AMI。图5a和5b分别显示了使用ARI度量的评估结果,分别在数据集Facebook和Enron上。请注意,ARI和AMI值越高,对应的准确度越高。
显然,在这两个数据集上,所提出的方法LDPGen显着优于非常直观的方法RNL和DGG。此外,随着隐私预算ε的增加,LDPGen的ARI值迅速增长,而RNL和DGG的ARI线保持几乎平稳。这些观察表明,LDPGen在收集本地差分隐私下的私人信息方面更为有效。比较两种非常直观的方法,DGG在较大的安全数据集上略胜于RNL;然而,与LDPGen相比,在所有情况下,DGG的ARI值仍然很低。
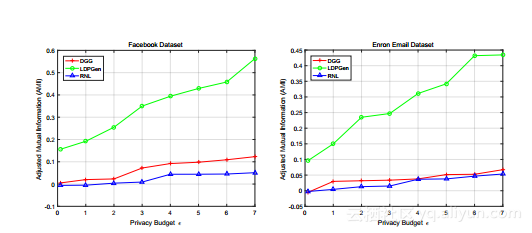
图6a和6b展示了使用AMI度量的社区信息保存结果,该度量也在5.1节中定义。这些结果导致与上述ARI结果相似的结论,
即LDPGen在每个环境中都能击败其竞争对手,并且性能差距随着隐私预算ε的增加而扩大。比较ARI和AMI结果,LDPGen在AMI方面的表现一直比ARI好,这表明LDPGen可能更适合高AMI值更重要的应用。
效用导致推荐系统。接下来我们评估 -在社会推荐用例中使用了LDPGen,RNL和DGG的有效性,使用了Section5.1,它衡量建议的物品清单的类似程度
(a)facebook (b)Enron
图4 epsilon对吸收性系数的影响
(a)facebook (b)Enron
图5 epsilon对调整的随机索引的影响
(a)facebook (b)Enron
图6 epsilon对调整的随机互信息的影响
(a)Last.fm (b)Flixter
图7 epsilon对正则化折现累积增益(NDCG)的影响
分别使用真实和合成数据。较大的NDCG值对应较高的准确度。
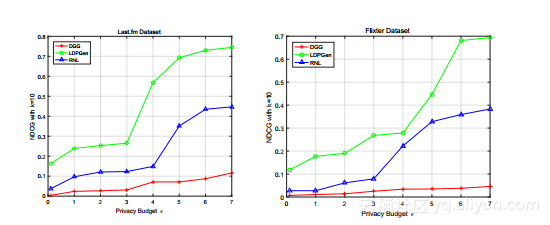
图7a和7b分别显示了使用Last.fm和Flixter数据集的所有三种方法的NDCG评分。一旦
再次,LDPGen在所有设置和两个数据集上都明显优于RNL和DGG。比较RNL和DGG,后者完全失败,NDCG得分不超过0.2,这意味着它推荐的项目与使用精确社会图计算的建议几乎没有共同之处。 RNL表现比DGG好得多;原因是在推荐应用程序中,只有紧邻的邻居才是重要的,RNL直接收集这些信息。尽管如此,LDPGen仍然比RNL获得更好的NDCG分数。
一个有趣的观察结果是,LDPGen的NDCG结果与隐私预算ε不成线性增长;相反,对于小的ε值,NDCG得分仍然很低,当3≤ε≤6时,NDCG得分会迅速增加,之后会变得平稳。原因是,对于每个用户u,建议的物品列表包含其邻居中评价较高的常见物品。当ε低时,社交图很嘈杂;然而,大多数用户评价的项目不仅仅是你的邻居。因此,NDCG分数主要反映这些项目,这些项目对于你的邻居列表有多吵闹不敏感。一旦ε达到一定水平,在u的邻居中被评为高但不是全局的项目会逐渐出现在u的推荐项目列表中,从而提高NDCG评分。最后,当推荐项目列表中包括大部分此类项目时,LDPGen的NDCG得分变得稳定;换句话说,在这个阶段,使用合成图和实际图计算出的推荐项主要在细节上有所不同,即用户的邻居不一致评价为高的项。
总结公用事业评估,LDPGen是明确的赢家,它在所有指标和所有数据集上都获得了高准确度。RNL和DGG只对它们专门优化的度量(例如DGG用于聚类系数)或者当应用程序主要使用它们直接收集的信息(例如推荐应用程序的RNL)时才具有竞争力。因此,LDPGen是实际应用中合成分散图生成的首选方法。
(a)facebook (b)Enron
图8 组个数k1对模块度的影响
(a)facebook (b)Enron
图9 组个数k1对调整随机索引(ARI)的影响
5.3 LDPGen的参数研究
确立了LDPGen优于其竞争对手的优势后,我们现在调查LDPGen中参数k1的适当值的影响,即4.2节中所述的阶段I中的组数。直观地,较小的k1导致在每个用户的报告的邻居列表中较粗糙的粒度,并且同时需要较小量的随机扰动来满足局部差分隐私。对于更大的k1值,情况正好相反。因此,选择合适的k1对于LDPGen的整体性能至关重要。如第4.2节所述,LDPGen根据收集的度向量为k1选择一个值。因此,这些实验也评估了LDPGen选择k1的质量。
图8显示了在固定隐私预算ε= 1后,LDPGen在Facebook和Enron数据集上的模块性结果,具有不同的k1值。相同的数字还显示了LDPGen选择的值,如垂直线所示。对于这两个数据集,LDPGen的效用首先随k1增加,然后在k1达到最优值后随k1减小,这与LDPGen选择的非常接近。这证实了第4.2节中选择k1的方法的有效性。类似地,图9显示了k1对LDPGen社区发现效用的影响,以ARI指标以及LDPGen选择的k1值。显然,这些结果与模块化的结果是一致的。我们省略了k1的进一步实验结果,因为它们都导致相同的结论。
最后,图10显示了使用ARI / AMI指标和Facebook数据集对LDPGen的阶段II中的用户分组进行细化的轮次数的影响。隐私预算ε固定为1
在这些实验中。结果表明,两轮改进效果最好。这是因为更多轮次的分组细化导致在改善用户分组方面的收益递减,这不能弥补增加的隐私预算消耗。其他度量和数据集的结果导致相同的结论。因此,LDPGen总是针对用户分组进行细化,第一阶段结束时一个,第二阶
段一个,如第4节所述。
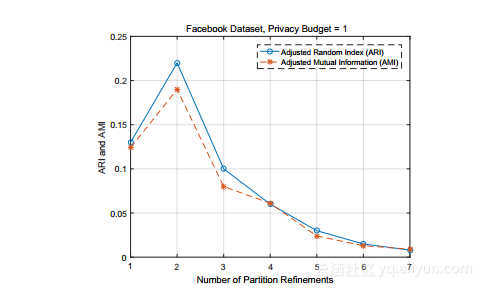
图10 Facebook数据集中ARI和AMI对于组细化迭代次数的影响
6相关工作
图形生成的正式模型有大量的工作。最早的模型是Erdos-Renyi(ER)模型[14],它假定图中的每一对节点都以独立且相同概率的边连接。 Chung和Lu提出了CL模型[1],它与ER模型在精神上相似,但允许每个边以不同的概率存在,以确保节点度遵循给定的分布。基于ER和CL模型,Seshadri等人提出区块两层
鄂尔多斯 - 仁义图模型(BTER)[43]使用标准的ER模型形成相对密集的子图(与社区相对应),然后利用CL模型添加额外的边,以确保结果图遵循给定边缘分布。随后,BTER模型的一些变体增加了更复杂的精确图形建模。此外,还有其他几种图模型,如克罗内克图模型[28],优先附件模型[38],指数随机图模型[41]。
上述图表模型在合成图的生成中没有考虑到对个人隐私的保护。为了解决这个问题,最近的工作[8,23,24,32,36,42,45,46,50]已经开发出图形生成方法,基于相同的基本原则确保集中式设置中的差异式隐私想法如下。给定输入图G,它们首先以满足差分隐私的方式导出G的一些噪声统计(例如度分布)。之后,他们送出嘈杂的状态 - *抽成一个图模型,然后返回合成图G*获得。由于G只取决于噪声统计(哪些是*差别私人)而不是输入图形,G也达到差别隐私。然而,这些方法要求数据发布者知道整个输入图G.结果,它们在我们的设置中不适用,其中数据发布者不能直接访问G并且需要来自每个用户的信息(即,每个顶点),同时确保本地差分隐私。请注意,我们的方法也可以在用户组在第二阶段进行完善后使用现有模型,只要该模型不需要单跳用户信息即可。
局部差分隐私(LDP)是一种隐私框架,它是根据传统的集中式差分隐私(DP)模型进行调整的,以解决数据在不同用户间分布的情况,因此没有收集者可以访问完整的数据集,或者收集者不希望负责收集最终用户的原始数据。然而,大多数现有的LDP方法仅限于最终用户数据是数值或分类值的元组,并且收集器计算诸如计数和直方图的简单统计数据的情况。包括[2,9,15,17,20,25,47,49] LDP在频率估计方面已经引入了一系列长期的研究。具体而言,华纳[47]的随机响应方法的先驱研究之后,一项研究将LDP模型形式化[25]。 Duchi等人[9]利用信息理论逆向技术提供了凸统计估计的极大极小误差界,而Hsu等[20]采用随机投影和浓度测量来估计重击者。然后,Bassily等人。 [2]提出了一个简洁的直方图估计算法与信息理论最佳误差。 Erlingsson等人[15]提出了扩展随机响应收集的分类值的频率,而Fanti等。 [17]进一步扩展它以处理分类值域未知的情况。之后,熊等人提出了一项有趣的工作。 [49],它通过提供传感器观测值与其压缩版本之间离散无记忆信道的优化来提供LDP。
Qin等人最近的工作。 [39]提出了一个两阶段LDP机制,称为LDPMiner,它处理更复杂的数据挖掘任务。具体来说,LDPMiner被证明可以提供准确的重击者估值。 [12]也对流数据中的频繁元素进行了私人估计。 Nguyen等人[37]提出了一种名为Harmony的LDP机制,作为用于收集和分析智能设备用户数据的实用,准确和高效的系统。 Harmony可以处理包含数值和分类属性的多维数据,并且支持基本统计(例如平均和频率估计)和复杂的机器学习任务(例如,线性回归,逻辑回归和SVM分类)。
上述LDP研究的共同主题是它仅限于收集简单的统计信息,如计数,直方图和重击者。另外,正如前面所指出的,在全球差别隐私框架下,图表生成方面已经做了很多工作。据我们所知,我们是第一个提出一种产生具有地方差别隐私的综合分散社会图的机制。
7结论
分散式社交网络中存在丰富而有价值的信息,图形信息仅由个人用户在其有限的本地视图中存储。在本文中,我们提出LDPGen,一种多阶段技术,逐步从用户中提取信息,构建底层社交网络的代表图,同时保证边缘局部差分隐私。 LDPGen相对于现有LDP和合成图生成技术的直接适应的优势通过对多个实际数据集进行全面实验来验证。
据我们所知,这项工作是第一个通过本地差异化隐私保护分散式社交网络的隐私保护图分析。许多具有挑战性的问题仍然存在,包括加入更强的隐私模型(例如节点本地差分隐私),处理具有边权重和节点/边属性的图,以及开发用于特定图挖掘任务的技术,例如三角计数和频繁子图结构挖掘。计划在我们未来的工作中解决。
8致谢
本文作者之一的萧小奎教授被新加坡教育部和新加坡南洋理工大学的DSAIR中心支持,ID为MOE2015-T2-2-069;本文作者之一的尹扬得到了QNRF基金支持,ID为NPRP10-0708-170408。
参考文献
[1] William Aiello, Fan Chung, and Linyuan Lu. 2000. A random graph model for massive graphs. In Proceedings of the thirty-second annual ACM symposium on Theory of computing. Acm, 171–180.
[2] Raef Bassily and Adam D. Smith. 2015. Local, Private, Efcient Protocols for Succinct Histograms. In STOC. 127–135.
[3] Thierry Bertin-Mahieux, Daniel P.W. Ellis, Brian Whitman, and Paul Lamere. 2011. The Million Song Dataset. In Proceedings of the 12th International Conference on Music Information Retrieval (ISMIR 2011).
[4] Jeremiah Blocki, Avrim Blum, Anupam Datta, and Or Sheffet. 2012. The johnsonlindenstrauss transform itself preserves differential privacy. In Foundations of Computer Science (FOCS), 2012 IEEE 53rd Annual Symposium on. IEEE, 410–419.
[5] Vincent D Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. 2008. Fast unfolding of communities in large networks. Journal of statistical mechanics: theory and experiment 2008, 10 (2008), P10008.
[6] Christian Braune, Christian Borgelt, and Rudolf Kruse. 2013. Behavioral clustering for point processes. In International Symposium on Intelligent Data Analysis. Springer, 127–137.
[7] L da F Costa, Francisco A Rodrigues, Gonzalo Travieso, and Paulino Ribeiro Villas Boas. 2007. Characterization of complex networks: A survey of measurements. Advances in physics 56, 1 (2007), 167–242.
[8] Wei-Yen Day, Ninghui Li, and Min Lyu. 2016. Publishing graph degree distribution with node differential privacy. In Proceedings of the 2016 International Conference on Management of Data. ACM, 123–138.
[9] John C Duchi, Michael I Jordan, and Martin J Wainwright. 2013. Local privacy and statistical minimax rates. In FOCS. 429–438.
[10] Cynthia Dwork. 2006. Differential privacy. In Automata, languages and programming. 1–12.
[11] Cynthia Dwork and Jing Lei. 2009. Differential privacy and robust statistics. In Proceedings of the forty-frst annual ACM symposium on Theory of computing. ACM, 371–380.
[12] Cynthia Dwork, Moni Naor, Toniann Pitassi, Guy N Rothblum, and Sergey Yekhanin. 2010. Pan-Private Streaming Algorithms.. In ICS. 66–80.
[13] Cynthia Dwork, Aaron Roth, et al. 2014. The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science 9, 3–4 (2014), 211–407.
[14] Paul Erdös and Alfréd Rényi. 1959. On random graphs, I. Publicationes Mathematicae (Debrecen) 6 (1959), 290–297.
[15] Úlfar Erlingsson et al. 2014. Rappor: Randomized aggregatable privacy-preserving ordinal response. In CCS. 1054–1067.
[16] Úlfar Erlingsson, Vasyl Pihur, and Aleksandra Korolova. 2014. Rappor: Randomized aggregatable privacy-preserving ordinal response. In Proceedings of the 2014 ACM SIGSAC conference on computer and communications security. ACM, 1054–1067.
[17] Giulia Fanti et al. 2016. Building a RAPPOR with the Unknown: PrivacyPreserving Learning of Associations and Data Dictionaries. PoPETS issue 3, 2016 (2016).
[18] Neil Zhenqiang Gong, Wenchang Xu, Ling Huang, Prateek Mittal, Emil Stefanov, Vyas Sekar, and Dawn Song. 2012. Evolution of social-attribute networks: measurements, modeling, and implications using google+. In Proceedings of the 2012 ACM conference on Internet measurement conference. ACM, 131–144.
[19] Roger Guimera, Marta Sales-Pardo, and Luís A Nunes Amaral. 2004. Modularity from fluctuations in random graphs and complex networks. Physical Review E 70, 2 (2004), 025101.
[20] Justin Hsu, Sanjeev Khanna, and Aaron Roth. 2012. Distributed private heavy
版权声明:允许将个人或课堂使用的全部或部分作品的数字化或硬拷贝免费授予,前提是复制品不是为了获利或商业利益而制作或发布的,并且副本在第一页上包含本通知和全部引用。由ACM以外的其他人拥有的组件的版权必须受到尊重。允许用信用抽象。要复制或重新发布,在服务器上发布或重新分发到列表,需要事先获得特定许可和/或收费。请求permissions@acm.org的权限。 CCS '17,2017年10月30日至11月3日,美国德克萨斯州达拉斯©2017计算机械协会。 ACM ISBN 978-1-4503-4946-8 / 17/10 ... $ 15.00 https://doi.org/10.1145/3133956.3134086各种指标,包括(i)重要的图表结构性措施; (ii)社区发现的质量;和(iii)适用于社会推荐。我们的实验表明,所提出的技术可以生成高质量的合成图,它们很好地代表了原始的分散式社交图,并且明显优于基线方法。
