1. 背景
随着视频采集及传输技术的发展,视频素材的分辨率和帧率在不断提升。分辨率从2K到4K到8K;帧率从30到60到120;新的标准及技术,比如HDR,也不断出现。
素材质量的增长,图像码流量也随之增长。人们需要压缩率更好的压缩算法标准,才能够适应新的图像压缩需求:
- 同样的压缩率得到更好的画质
- 同样的画质得到更好的压缩率
在这个大背景H.265/HEVC出现了。相比于上一代标准H.264,H.265更适合大分辨率、高帧率的图像压缩;有着更好的压缩率和画质结果。
(测试结果引用自论文Comparative Assessment of H.265/MPEG-HEVC, VP9, and H.264/MPEG-AVC Encoders for Low-Delay Video Applications)

H.265/HEVC带来更好性能的同时,也意味着运算量的加大。如何高效、实时的实现H.265编解码成为研究的热点。
2. H.265/HEVC算法简介
H.265/HEVC包括帧内预测(intra prediction)、帧间预测(inter prediction)、转换(transform)、量化(quantization)、去区块滤波器(deblocking filter)、熵编码(entropy coding)等模块。
和H.264类似,帧内预测、帧间预测、滤波运算都需要大量的并行计算。
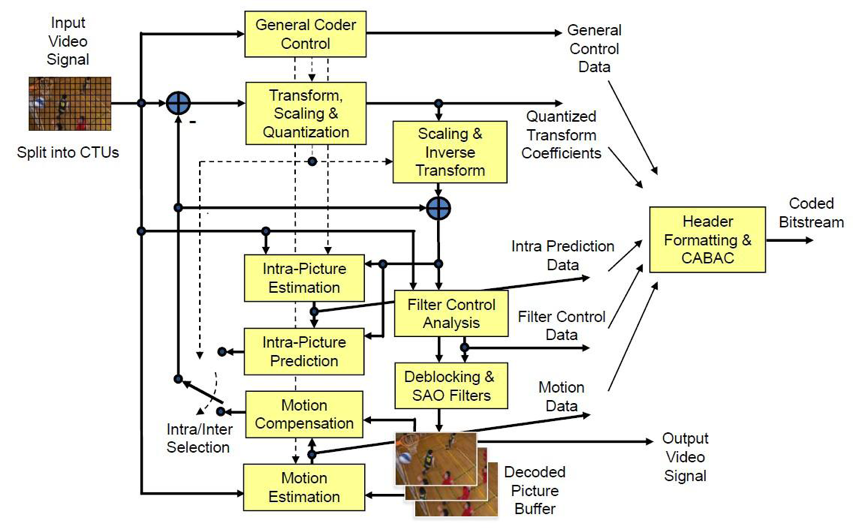
在H.265/HEVC编码架构中,整体被分为了三个基本单位,分别是编码单位(coding unit, CU)、预测单位(predict unit, PU)和转换单位(transform unit, TU)。更灵活的宏模块划分给压缩率、画质带来了很大的提升。同时也给运算增加了难度,对并行化运算、灵活化运算提出了更高的运算。

3. FPGA H.265/HEVC解码
列举两个H.265/HEVC FPGA IP作为例子。
NGCodec
高画质版本IP特点:
- 等效于x265 Medium或者Slow配置的画质
- 支持I/P/B帧,同等画质下有更低的压缩率
- 可配参数look-ahead – Adaptive Quantization,提高压缩率
- 支持Multi-stream encoding for ABR (Adaptive Bitrate Encoding),针对不同条件的播放终端,可以生成多种分辨率和码率的压缩结果
- 采用Temporal Motion Vector Prediction (TMVP) ,提高画质和压缩率
- 10bit 4:2:0 (HDR support)
- 最高支持1080p60,4k@30
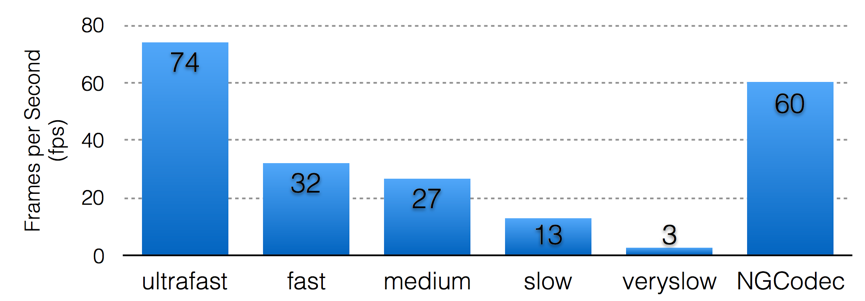
对应x265的“very slow”配置结果,NGCodec编码器能够达到1080p60(60帧/秒)的处理能力,远大于x265的3帧/秒。
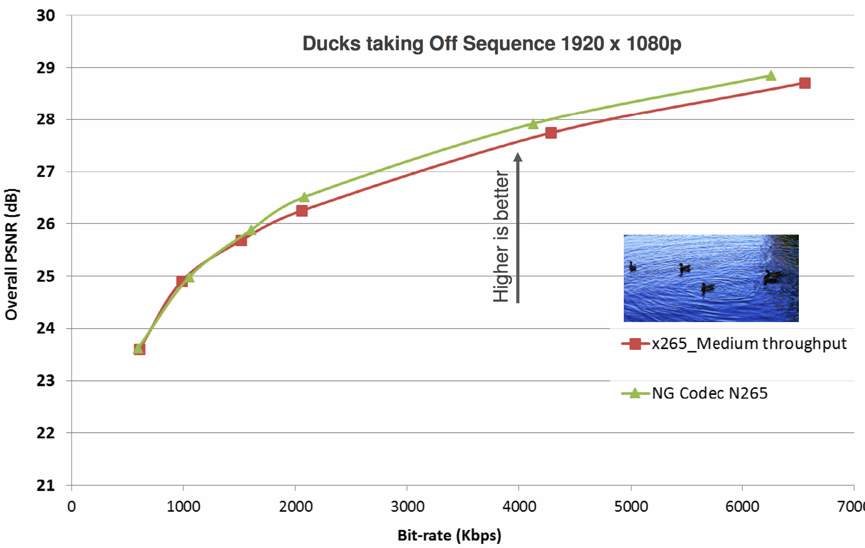
对于相同画质下的压缩率对比如下图,采用“Ducks taking Off”1920x1080素材。可以看到NGCode HEVC编码器在压缩率和画质上均优于x265 Medium 设置下的结果。
IP面积如下表。目前在VU9P上可以放下1套高画质版本的HEVC Encoder,占用资源50%。优化过后可以放下2套。
|
|
描述 |
1080p60 on VU9P |
| 高质量版本 |
画质相当于x265 Med/Slow |
1 Channels 2 Channels on Q3 |
| 高密度版本 |
画质相当于x265 Fast |
2 Channels 2-3 Channels on Q3 |
System-On-Chip (SOC) Technologies

IP特点:
- Profile: Main 4:2:2 12
- 最高支持1080@60,4k@30
- 支持I/P帧
- HD信号25ms延时,4k信号50ms延时
- 固定码流/可变码流输出
资源消耗如下表。Xilinx VU9P有1182240个LUT,初步估算可以放下6套标准版本HEVC Encoder。
|
|
Xilinx FPGA |
Altera FPGA |
| Standard Version |
150,000 ALMs, 11,000kbits block RAM, 400 DSPs |
100,000 ALMs, 10,000kbits block RAM, 320 DSPs |
| I-Frame Version |
60,000 ALMs, 4,500kbits block RAM, 160 DSPs |
30,000 ALMs, 4,000kbits block RAM, 130 DSPs |
| Slim Version |
70,000 ALMs, 7,000kbits block RAM, 200 DSPs |
50,000 ALMs, 5,000kbits block RAM, 160 DSPs |
4. GPU H.265/HEVC 编码
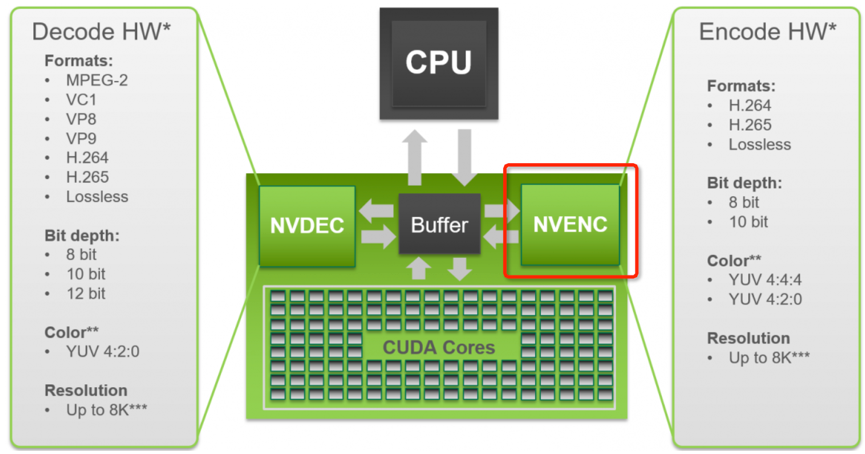
GPU 某些型号内部有硬核来支持视频编解码单元。以Nvidia Tesla P4为例,它包括NVENC和NVDEC两个硬加速单元分别给视频压缩的编码、解码提供加速服务。
NVENC硬编码器特性如下:
- 支持4:4:4,4:2:0;4:2:2不支持
- 不支持B帧,压缩率会有负面影响
- 分辨率最大支持到8K
- 支持1-pass, 2-pass模式
- NVENC不支持VP8、VP9,VC1等其他标准,不具备扩展和升级的可能
对于10bit视频,每个NVENC可以编码1路4K@30fps 4:2:0,或者5路1080p30 4:2:0。
Nvidia Tesla P4 有2个NVENC和1个NVDEC,可以编码2路4K@30fps,10路1080p30,换算成1080p60,是5路左右。

相同的画质情况下,Nvidia NVENC压缩完的bitrate是x265的2.5倍

5. Intel QSV H.265/HEVC编码
QSV (Quick Sync Video)是Intel的硬件编解码技术,可以有效降低CPU的负载。ffmpeg提供对QuickSync的完整支持。
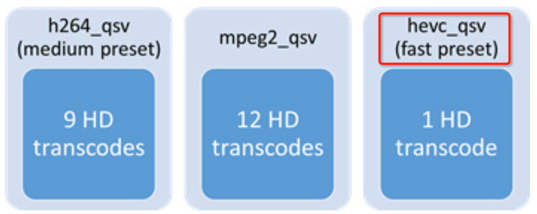
下图显示了在单片Intel® Xeon® processor E3-1285L v4 上使用x_qsv能够支持的视频编码的通道数量,输入格式为1080p30。
对于HEVC的编码,采用fast preset,只能支持一个通道1080p30。
对于各个画质preset设置下,帧率和bitrate结果如下图所示:
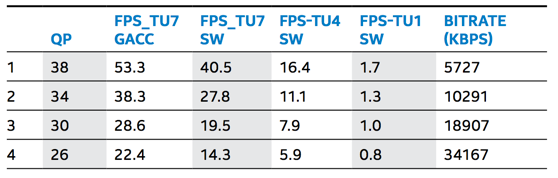
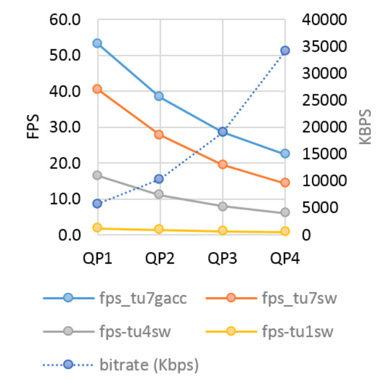
QSV和x265有相似的平均bitrate,如下图所示。

6. FPGA & GPU & QSV对比
H.265/HEVC在各个场景下推荐的配置如下:
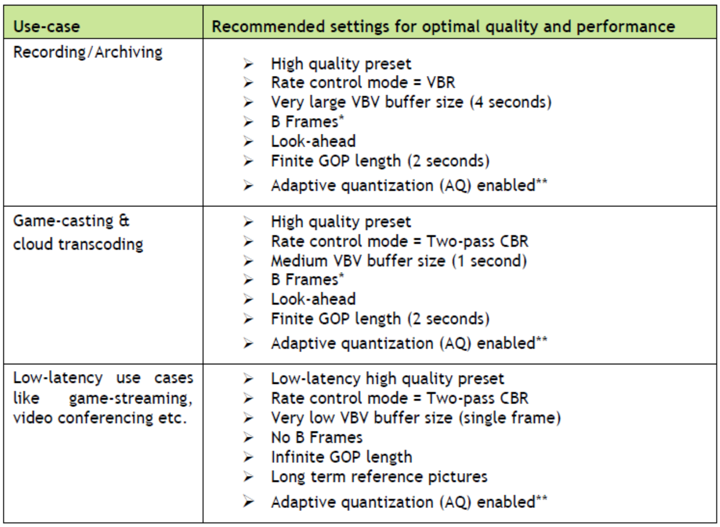
结合上述配置推荐,列出一部分配置比较如下。FPGA 版本可配置参数和功能明显多于GPU版本。
|
|
NGCocec (Xilinx VU9P) |
SoC Tech (Xilinx VU9p) |
Nvidia Tesla P4 |
QSV Xeon E3-1285L v4 |
| I/P Frame |
Yes |
Yes |
Yes |
Yes |
| B Frame |
Yes |
No |
No |
- |
| Adaptive Quantization |
Spatial/Temporal |
- |
Spatial only |
- |
| Scene change detection |
Yes |
- |
No |
- |
| CTU sizes |
16x16,32,x32,64x64 |
- |
16x16,32,x32 |
- |
| 其他编码方式(VP9) |
FPGA 可以通过更换IP方便地变换和升级编码方式 |
NVENC不支持,无法升级 |
- |
|
|
|
|
|
|
|
在相同画质下,压缩率越大越好,即bitrate越小越好。根据之前章节提到的数据,归总为如下图表。
可以看到FPGA NGCodec处理有最小的bitrate,仅为GPU处理的1/3,意味着存储成本可以下降2/3。

处理能力, 通道数比较。
|
|
NGCocec (Xilinx VU9P) |
SoC Tech (Xilinx VU9P) |
Nvidia Tesla P4 |
QSV Xeon E3-1285L v4 |
| 1080p30 |
2-4 |
12 |
10 |
1 |
| 1080p60 |
1-2 |
6 |
5 |
- |
| 4K@30 |
1 |
6 |
2 |
- |
7. 总结
对于H.265/HEVC编码处理,FPGA方案有着最完善的功能和preset配置,支持最多的有利于提高画质和降低bitrate的功能,适合各个场景下H265/HEVC的编解码配置。
同时具有灵活部署,易于升级的特点,非常容易就可以在某一个平台上升级IP特性,甚至根据需求,随时更换成其他协议的编解码功能。
FPGA的可扩展性也是GPU不可比拟的,能非常容易的在同一块FPGA上pipeline部署编解码相关的上下游应用;同时,因为FPGA之间的高速互联特性,也可以方便地在不同FPGA、不同FPGA板卡间部署完整的相关应用方案。(参考《Ali Cloud FPGA集群拓扑结构》https://www.atatech.org/articles/104152)
成本方面,高画质IP虽然通道数量上并不占优势,但是带来的bitrate的大幅降低,可以显著降低带宽成本、存储成本,综合成本是降低的;同时,有一些FPGA编解码IP也可以实现不输甚至优于GPU的通道处理能力。
在视频编解码领域,FPGA有着非常大的潜力和广阔的前景。