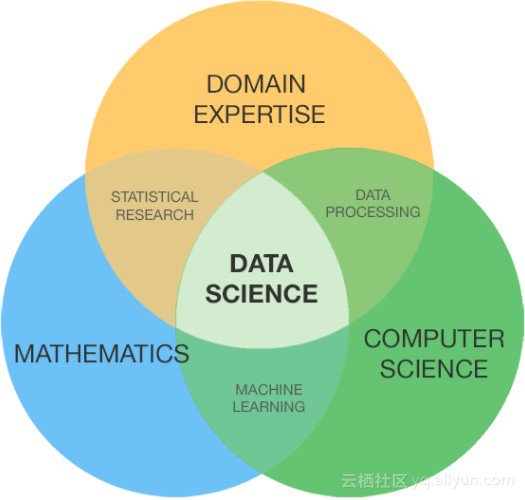
数据科学是一个相当庞大且具有多样化的领域,侧重于数学、计算机科学和领域专业知识。但是在本文中大部分内容将涉及到数学基础知识,当然也会介绍一些计算机科学的基本原理。
编程语言
在数据科学领域,最受欢迎的编程语言是Python和R语言。然而我也遇到过使用C/c++、Java和Scala的。而我个人推荐使用Python,因为它可使用所有现存数据库,并且拥有可以查询各种数据库和维护交互式Web UI的专用库。常用的Python库有matplotlib,numpy,pandas和scikit-learn。
数据库管理
大多数的数据科学家都属于数学家或数据库设计师两个阵营中的一个。如果你是第二个,那么本文对你不会有太大帮助,因为你已经足够厉害了。如果你和我一样属于第一个,并且觉得编写一个双重嵌套的SQL查询非常困难。那么对我们来说,了解查询优化(SQL和noSQL系统)非常重要了。
Map Reduce
考虑到Apache项目一直在不断的添加新工具,想要完全掌握大数据技术非常困难。对于大数据技术,我个人推荐学习Hadoop或Spark,二者都使用类似的Map Reduce算法,除了Hadoop使用磁盘,而Spark使用内存。常见的Spark包装器包括Scala、Python和Java。
数据收集和清理
既然我们已经讲解了所需要的软件,那么现在要开始过渡到数学领域了。在这部分过程中通常需要有一些解析背景,可能是收集传感器数据,分析网站或者进行调查。收集完数据后还需要将其转换为可用的表单(例如JSON行文件中的键值存储),之后这些数据还必须要进行一些数据质量检查。下面将介绍一些常见的质量检查:
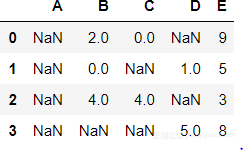
NaN的处理
NaN或者叫“Not A Number”是常用于表示丢失的数据。如果特定要素的NaNs数量很少,那么通常可以用(整个数据集或一个窗口的)平均值或(对于稀疏数据集)0来填充NaN。数据集中的NaN通常表示:
类不平衡
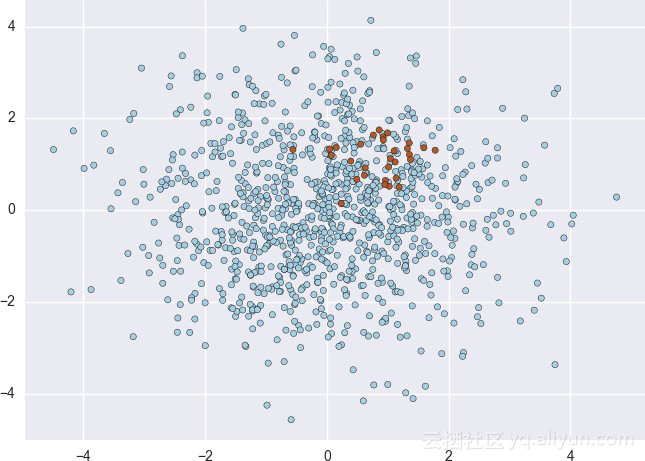
尤其是对有监督的学习模型来说,平衡类或目标是非常重要的。然而在欺诈的情况下,严重的阶级不平衡很常见(例如数据集中只有2%是真正的欺诈)。这些信息对于决定特征工程、建模和模型评估非常重要。
单变量分析
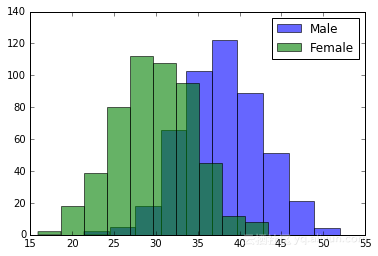
在寻找异常值和异常峰值时,对单个特征的单变量分析(忽略协变量eeects)非常重要。通常选择的单变量分析是直方图。
双变量分析
在双变量分析中,每个特征都会与数据集中的其他特征相比较。其中包括相关矩阵,协方差矩阵或者我个人最喜欢的散点矩阵。
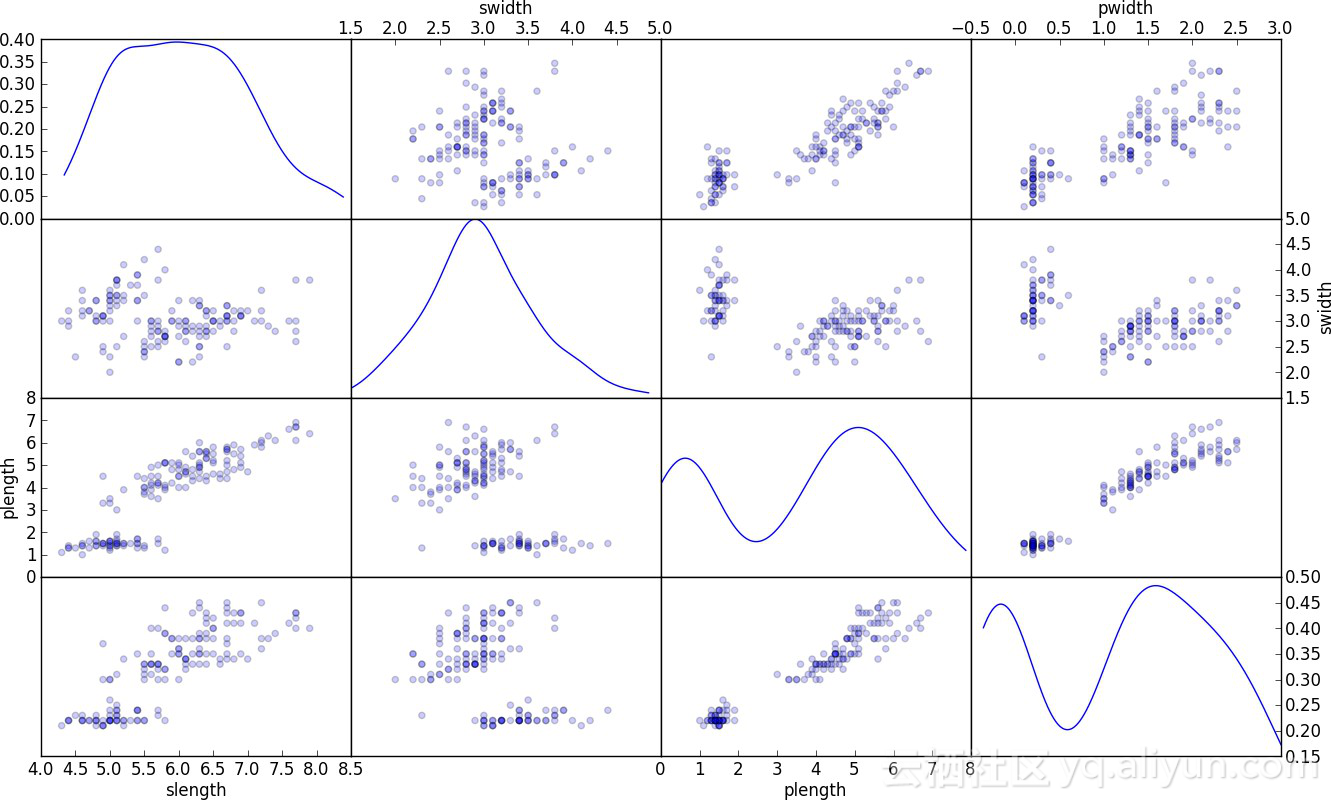
散点矩阵可以让我们发现隐藏的模式,例如:
-应该一起设计的模型。
-为避免多重性需要消除的特性。
多重共线性实际上是多个模型(线性回归等)的问题,因此需要相应的处理。
特征工程
一旦完成了数据的收集、清理和分析工作,就该开始创建模型中使用的特性了。在这一节中,我们将介绍一些常见的特征工程策略。
转换
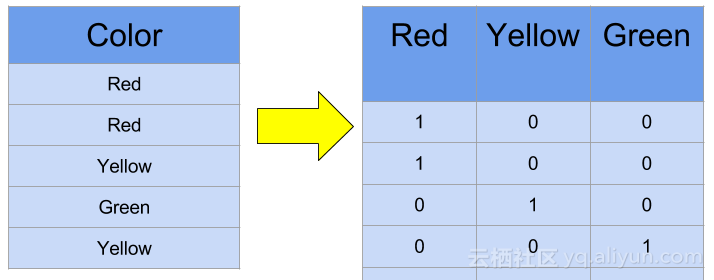
有时候特性本身并不能提供有用的信息。例如,想象一下使用互联网数据。你会得知YouTube Messenger用户使用几百兆字节,而YouTube用户使用千兆字节。对此最简单的解决方法是获取值得对数。另一个问题是使用分类值。虽然分类值在数学世界很常见,但计算机只能识别数字,为了使其在计算机中具有数学意义,需要先转换为数值。分类值执行独热编码(One Hot Encoding)非常常见,如果在给定的记录中存在独热编码,则为每个分类值创建一个新特性。下面给出独热编码的例子:
降维
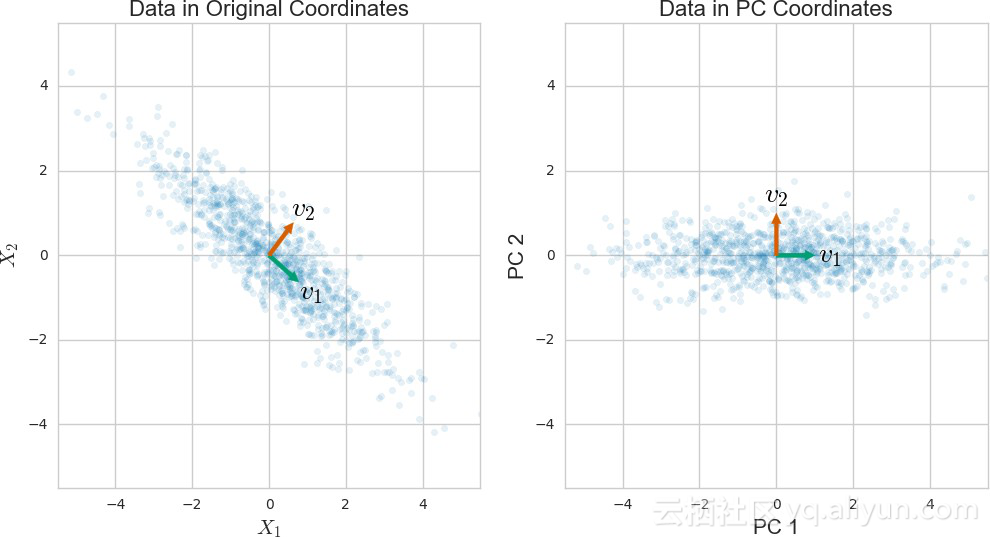
有时过多的稀疏维会妨碍模型的性能。对于这种情况需要使用降维算法。一种常用的降维算法是主分量分析(PCA)。
特征选择
你已经设计了特征列表,现在是时候选择特征来帮助你构建用例最佳模型了。这一节解释了常见的类别及其子类别:
过滤方法

筛选方法通常用来作为预处理步骤。特征的选择与任何机器学习算法无关,而是根据它们在各种统计测试中的分数和结果变量的相关性来选择的。相关性是一个很主观的术语,这类的常用方法是皮尔逊相关系数、线性判别分析、方差分析和卡方检验。
包装方法
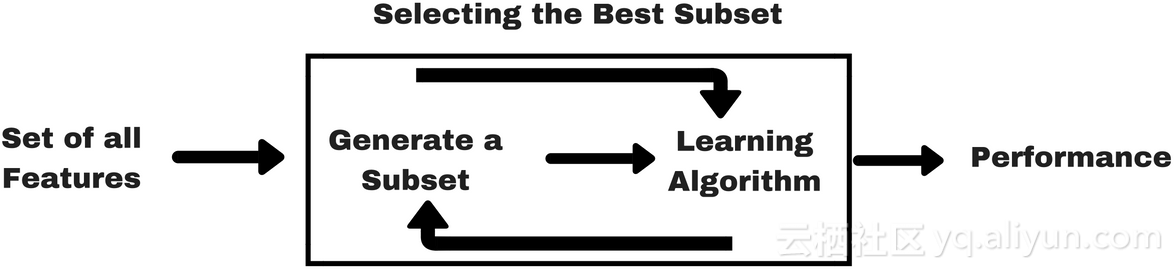
在包装方法中,我们尝试使用特性的子集来训练模型。基于在之前的模型中得出的推论,我们决定添加或删除子集中的特性。这个问题本质上是一个搜索问题。然而这些方法通常计算成本昂贵。常用方法是正向选择、反向消除和递归特性消除。
嵌入式方法
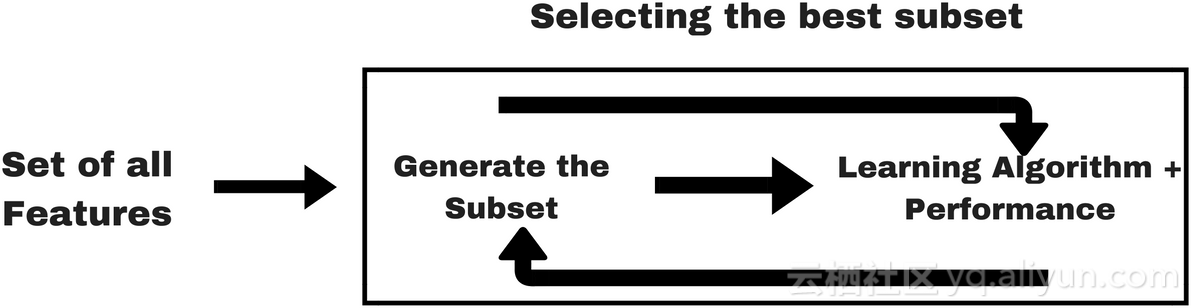
嵌入式方法结合了过滤器方法和包装方法的特性。该方法是由具有内置特性选择方法的算法实现的。常见的嵌入式方法包括LASSO和RIDGE。下面给出了方程中的正则化表达式:
LASSO:
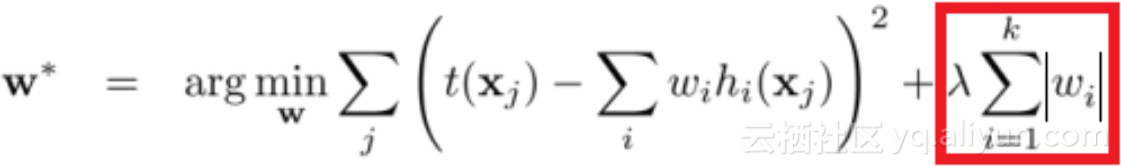
RIDGE:
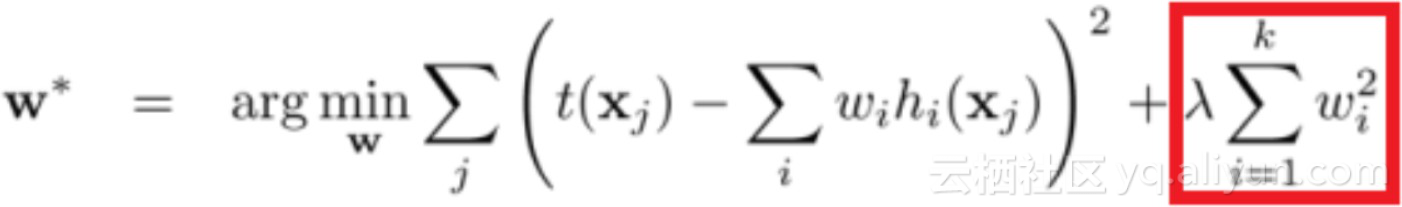
这就是说,为了访谈了解LASSO和RIDGE背后的机制非常重要。
机器学习模型
机器学习模型分为两大类:监督和无监督。当标签可用时为监督学习,不可用时为无监督学习。注意,监督标签!不要混淆监督和非监督学习的区别。另外,在运行模型之前,人们常犯的一个错误是没有对特性进行规范。虽然有些模型能自动纠正该错误,但是很多模型(如线性回归)对缩放非常敏感。因此使用前一定要使特性正常。
线性和逻辑回归
线性和逻辑回归是最基本也是最常用的机器学习算法。在做任何分析之前,确保首先将线性/逻辑回归作为了基准!一个普通的访谈者通常使用更复杂的模型(如神经网络)来开始他们的分析。毫无疑问,神经网络是非常精确的。然而,基准是也很重要。如果简单的回归模型已经有98%的精度并且非常接近过度拟合,那么就不需要得到一个更复杂的模型了。也就是说,线性回归用于连续目标,而逻辑回归则用于二进制目(主要是因为sigmoid曲线将特征输入输出为0或1)。

决策树和随机森林
决策树是一个比线性回归模型稍微复杂的模型。决策树算法根据信息增益在不同的特征上进行分割,直到它遇到一个纯粹的叶子(即一组只有1个标签的记录)。决策树可以在一定数量的分裂后停止以阻止获得纯叶子(解决过度拟合问题的常用策略)。
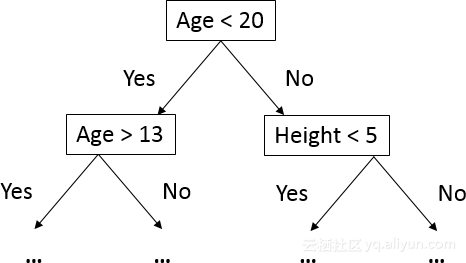
计算出来的信息增益非常重要,是常见的面试问题,所以要确保你知道如何计算。常用的信息增益计算函数是基尼系数和熵。
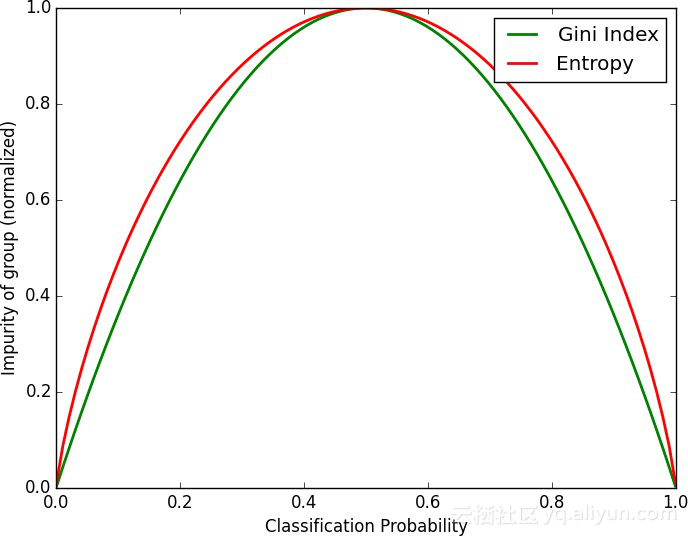
从上图可知,与基尼系数相比,熵为信息增益提供了更高的价值但也造成了更多的分裂
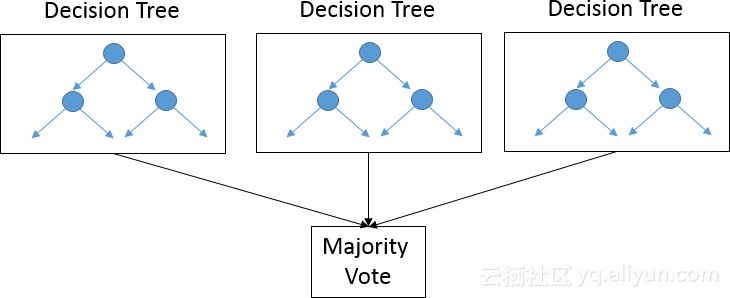
当决策树不够复杂时,通常会使用随机森林:只不过是在数据的子集上增加了多个决策树,并完成了最后的多数投票。但是如果无法正确确定树的数量,随机森林算法就会过度拟合。
K-Means
K-Means是一种将数据点分类成簇的无监督学习模型。该模型根据提供的簇数量迭代的找到最优的集群中心,并将矩心移动到中心。
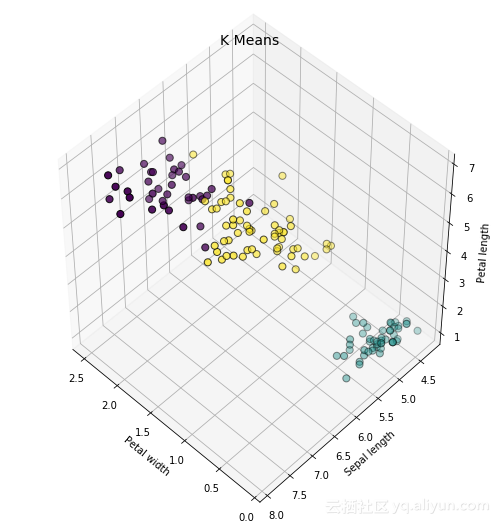
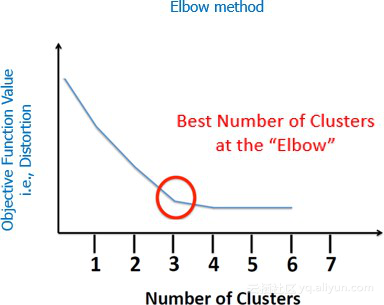
簇的数目可能会很容易找到,尤其是如果曲线上没有kink。另外,要认识到K-Means算法是在本地优化的而不是全局优化。所以簇的数量取决于初始化值,而最常用的初始化值是在K-Means++中计算出来的,它可以使初始值尽可能不同。
神经网络
神经网络是目前每个人都在关注的热门算法之一。
本文重要的是让你了解基本的机制以及反向传播和消失梯度的概念。同时还要认识到神经网络本质上是一个黑盒子。如果案例研究要求创建解释模型,那么只能选择不同的模型或准备解释如何找到权重对最终结果的贡献(例如,图像识别过程中隐藏层的可视化)。
集成模型
最后,单个模型可能不能准确地确定目标,某些特性需要特殊的模型。在这种情况下,需要使用多个模型的集成。请看下面的举例:
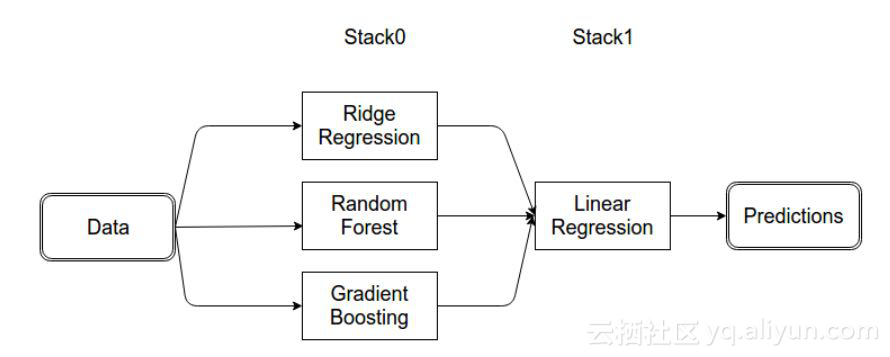
由上图可得,模型是分层或在堆栈中,每一层的输出是下一层的输入。
模型评估
分类得分
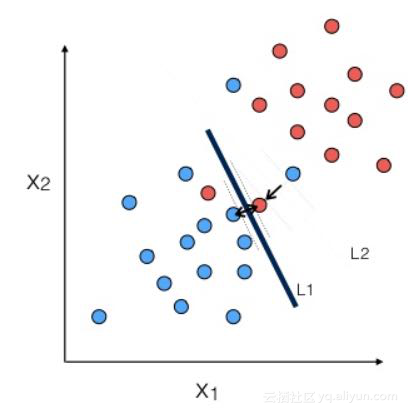
评估模型性能最常见的方法之一是:计算正确预测的记录的百分比。
学习曲线
学习曲线也是评价模型的常用方法,通过该方法可以评估我们的模型是否太复杂或太简单。
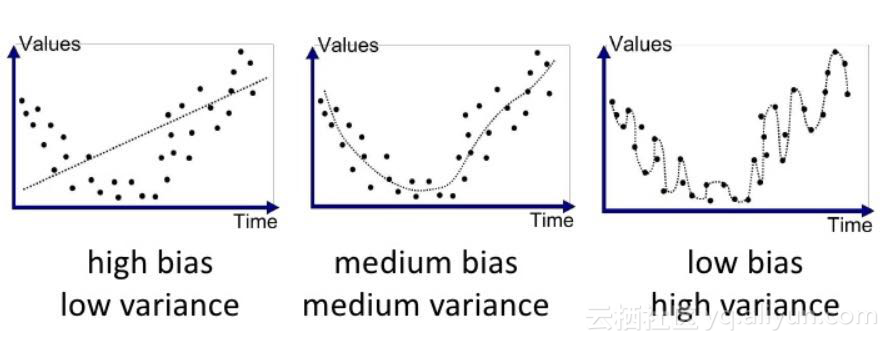
如果模型不够复杂,最终会得到高偏差和低方差。而当模型过于复杂,则会得到低偏差和高方差。但是在现在模型非常稳定的前提下,随着训练数据的随机化,结果也会有很大变化,所以不要混淆方差和偏差的区别!为了确定模型的复杂性,我们使用以下学习曲线来查看:
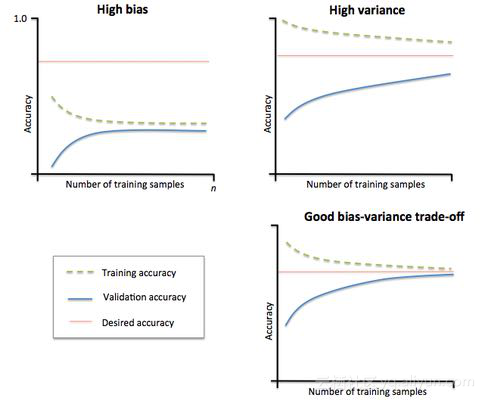
在学习曲线上,我们改变了X轴上的训练测试分割点,并计算了训练和验证数据集上模型的准确性。如果两者之间的差距太大,说明模型太过复杂即过度拟合了。如果两条曲线都没有达到预期的精度,而且曲线之间的距离很小,那么就说明数据集有很大的偏差。
受试者工作特征(ROC)
在处理带有严重类别失衡的欺诈数据集时,分类分数就没有多大意义了。相反,接收器的工作特性或ROC曲线是个更好的选择。
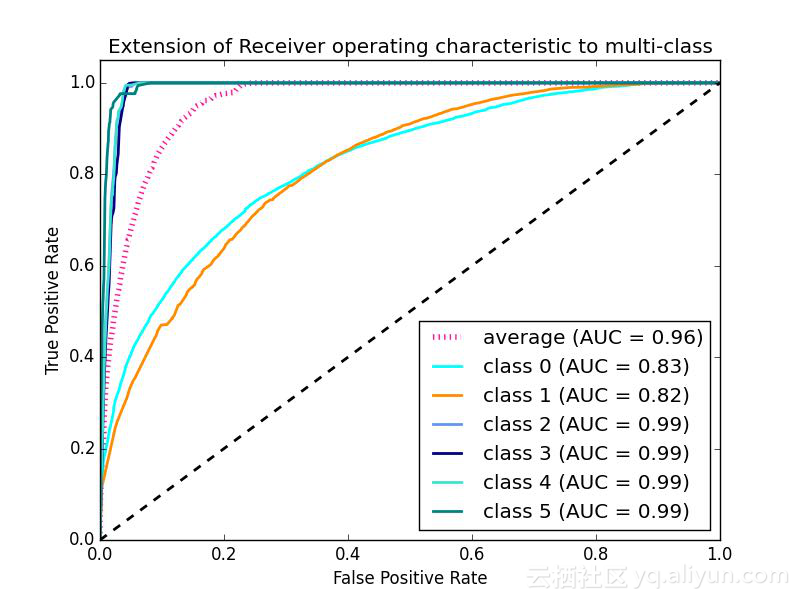
45度线是随机线,曲线下的面积或AUC为0.5。曲线离45度线越远,AUC越高,模型就越好。模型所能得到的最高值是AUC值等于1,即曲线与轴形成直角三角形。ROC曲线还可以帮助调试模型。例如,如果曲线的左下角更接近于随机线,则意味着模型在Y=0处分类错误。而如果它在右上角是随机的,则意味着错误发生在Y=1处。同样,如果曲线上有波峰,则说明模型不稳定。因此,在处理欺诈模型时,ROC是你最好的朋友。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Data Science Interview Guide》
作者:Syed Sadat Nazrul
译者:奥特曼,审校:袁虎。
文章为简译,更为详细的内容,请查看原文
