论文动机
首先是 motivation,近两年 DCF+CNN 的 tracker 在 tracking 的社区里面一直是标配,但我们注意到几乎所有的 tracker 都只用到了 RGB 信息,很少有用到视频帧和帧之间丰富的运动信息,这就导致了 tracker 在目标遇到运动模糊或者部分遮挡的时候,performance 只能依靠离线 train 的 feature 的质量,鲁棒性很难保证。
于是我们就想利用视频中的运动信息(Flow)来补偿这些情况下 RGB 信息的不足,来提升 tracker 的 performance。
具体来说,我们首先利用历史帧和当前帧得到 Flow,利用 Flow 信息把历史帧 warp 到当前帧,然后将 warp 过来的帧和本来的当前帧进行融合,这样就得到了当前帧不同 view 的特征表示,然后在 Siamese 和 DCF 框架下进行 tracking。
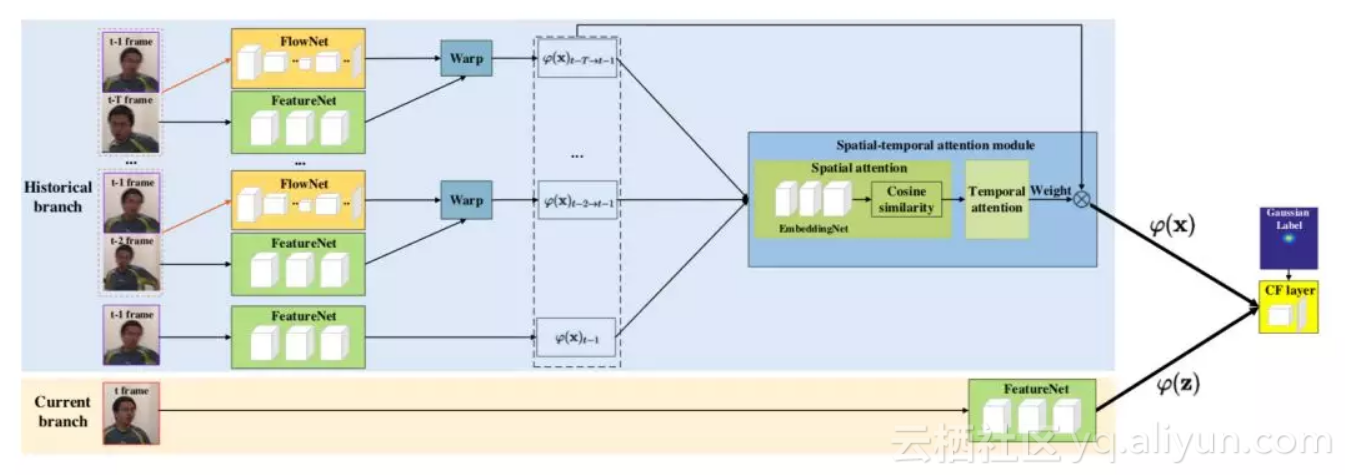
▲ FlowTrack整体框架
上面是我们算法的整体框架,采用 Siamese 结构,分为 Historical Branch 和Current Branch。
在 Historical Branch 里面,进行 Flow 的 提取 和 warp,在融合阶段,我们设计了一种 Spatial-temporal Attention 的机制(在后面叙述)。
在 Current Branch,只提取 feature。Siamese 结构两支出来的 feature 送进 DCF layer,得到 response map。
总结来说,我们把 Flow 提取、warp 操作、特征提取和融合和 CF tracking 都做成了网络的 layer,端到端地训练它们。
技术细节
下面是一些技术细节,采用问答方式书写。
问:warp 操作是什么意思,怎么实现的?
答:warp 具体的推导公式可以参见 paper,是一种点到点的映射关系;实现可以参见 DFF 和 FGFA 的 code,略作修改即可。
问:Flow 提取和训练是怎么实现的?
答:我们采用的是 FlowNet1.0 初始化,然后在 VID 上面训练,训练出来的 Flow 质量更高,对齐地更好;未来我们会换用 FlowNet2.0 或者速度更快的 Flow 网络,争取在速度和精度上有所提升。
问:融合是怎么实现的?
答:在融合阶段,我们我们设计了一种 Spatial-temporal Attention 的机制。在 Spatial Attention 中,是对空间位置上每一个待融合的点分配权重,具体采用余弦距离衡量(公式可以参见 paper),结果就是和当前帧越相似分配的权重越大,反之越小。
这么做的问题是当前帧的权重永远最大,所以我们借鉴 SENet 的思想进而设计了 temporal attention,即把每一帧看做一个 channel,设计一个质量判断网络:
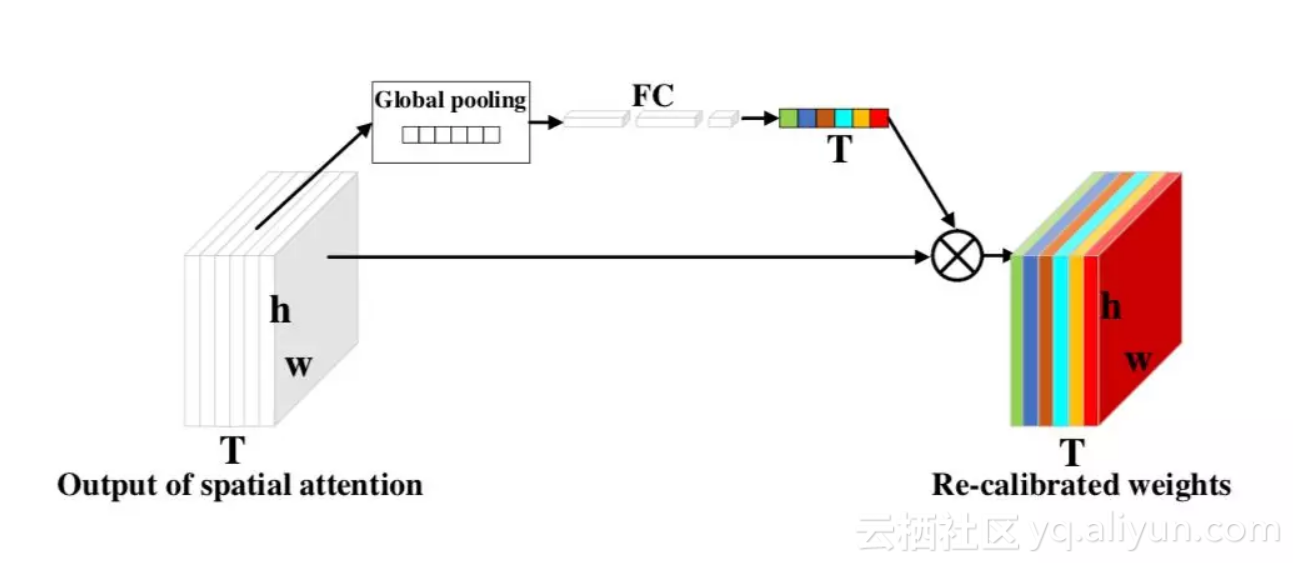
▲ Temporal Attention的图示
网络输出的结果是每一帧的质量打分,质量高的帧分数高,质量低(比如部分遮挡)的帧分数低:

▲ Temporal Attention的结果
Temporal Attention 和前面的 Spatial Attention 结合起来,就可以对 warp 之后的 feature map 和当前帧本身的 feature map 进行融合。
问:DCF 操作怎么做成 layer?
答:这个在 CFNet 和 DCFNet 里面具有阐述,paper 里面也做了简单的总结。
问:paper 里面 warp 的帧数是怎么选定的?
答:通过实验确定,实验结果如下:

▲ warp帧数的选择
问:最后在 OTB 和 VOT 的实验结果怎么样?
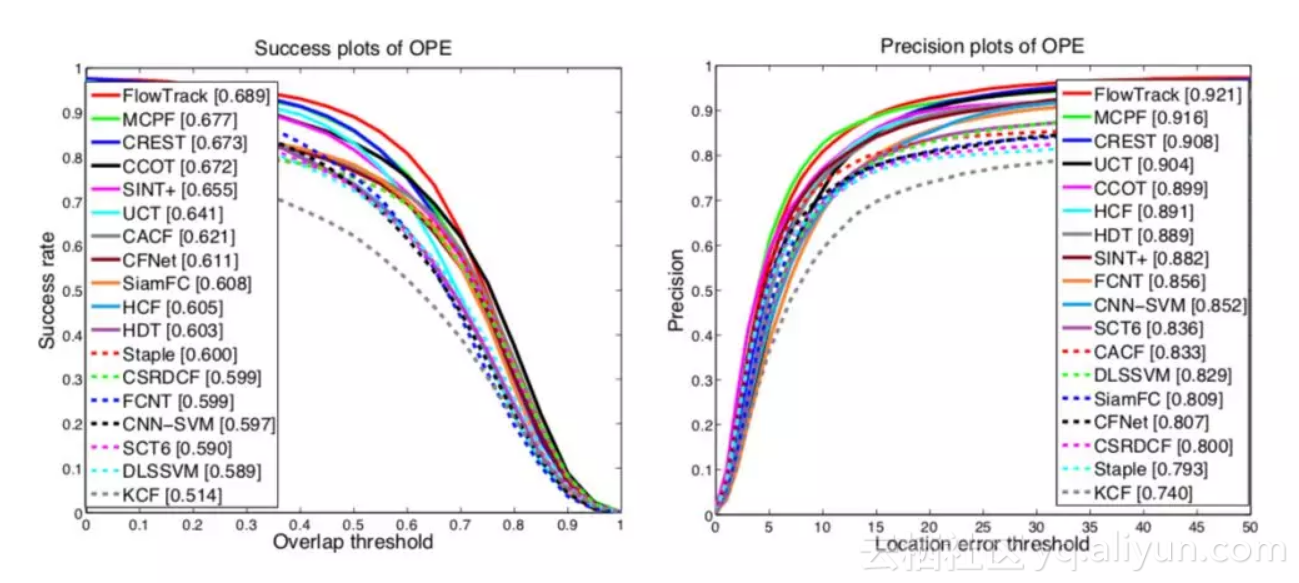
答:OTB2015 AUC 分数 0.655;VOT2016 EAO 分数 0.334(超过 CCOT),速度 12FPS(是 CCOT 的 40 倍),当然,和 ECO 还是有精度上的差距。结果图可以参见下面:
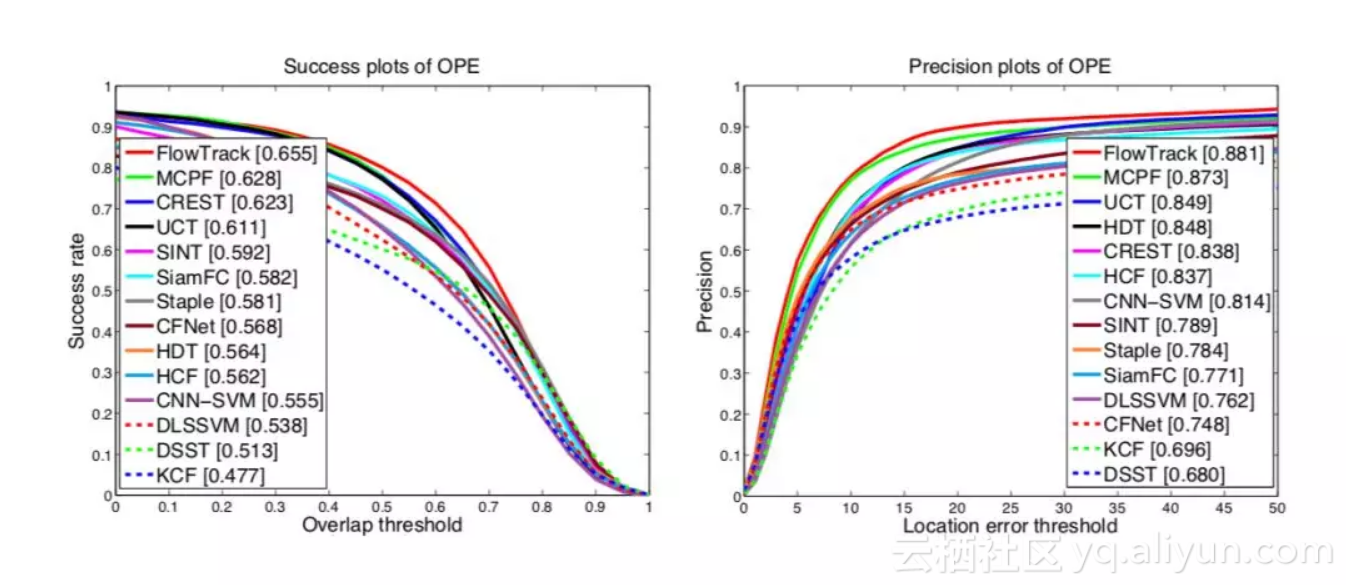
▲ OTB2015的实验结果
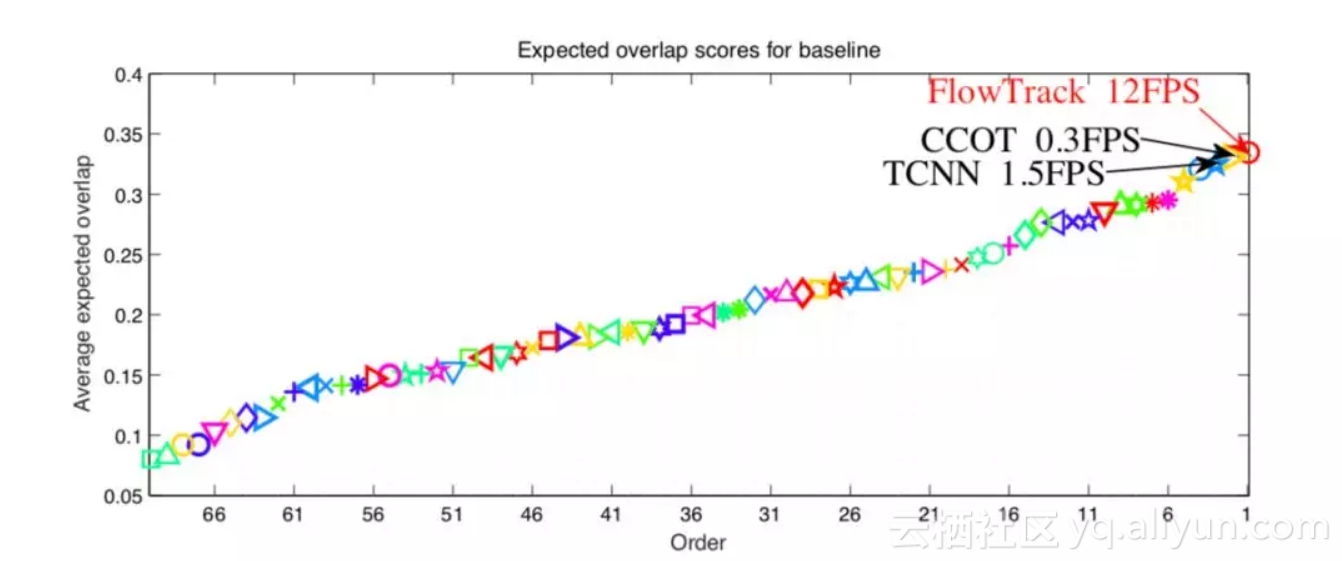
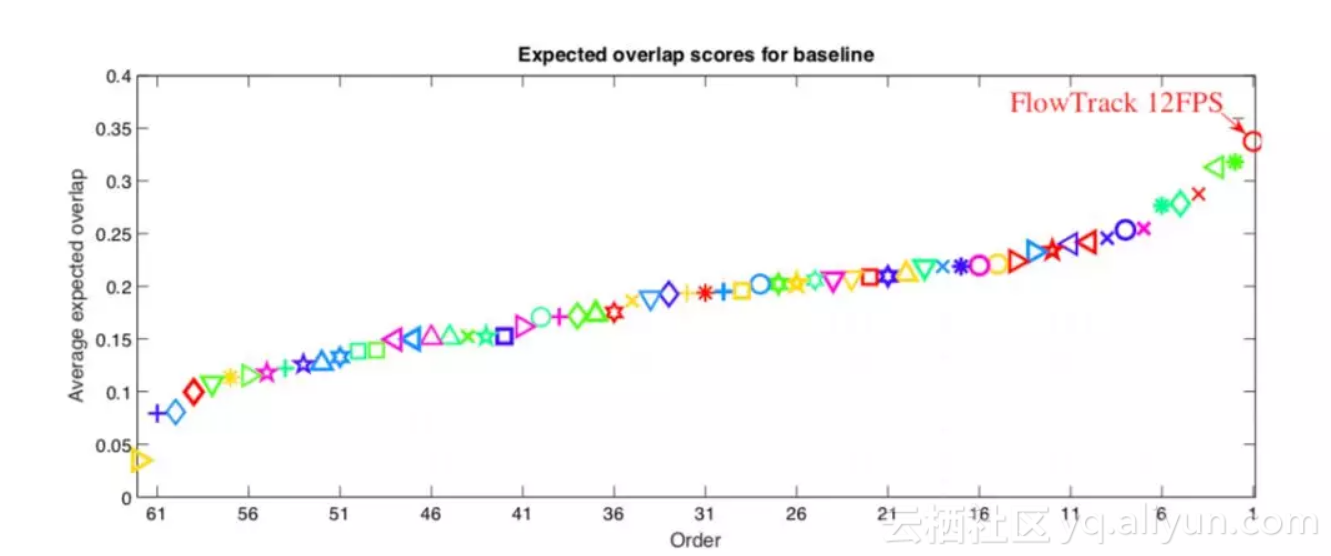
▲ VOT2016的EAO Ranking
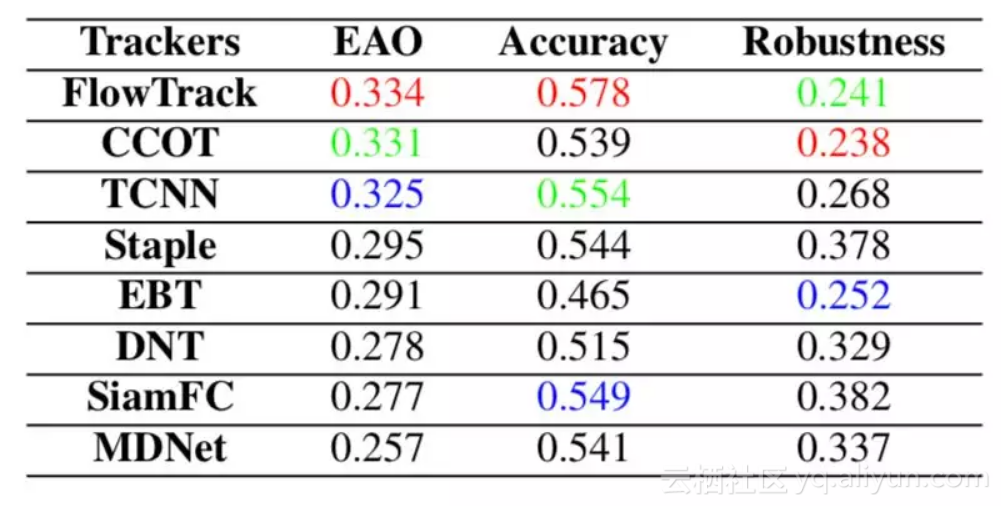
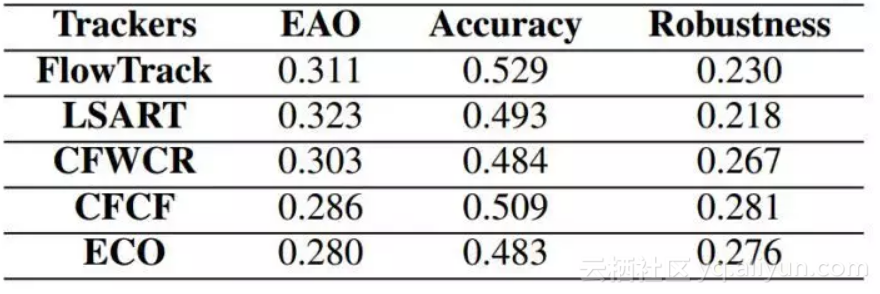
▲ VOT2016上面具体的accuracy和robustness
为了完整起见,补充一下 OTB2013 和 VOT2015 的结果:
▲ VOTB2013实验结果
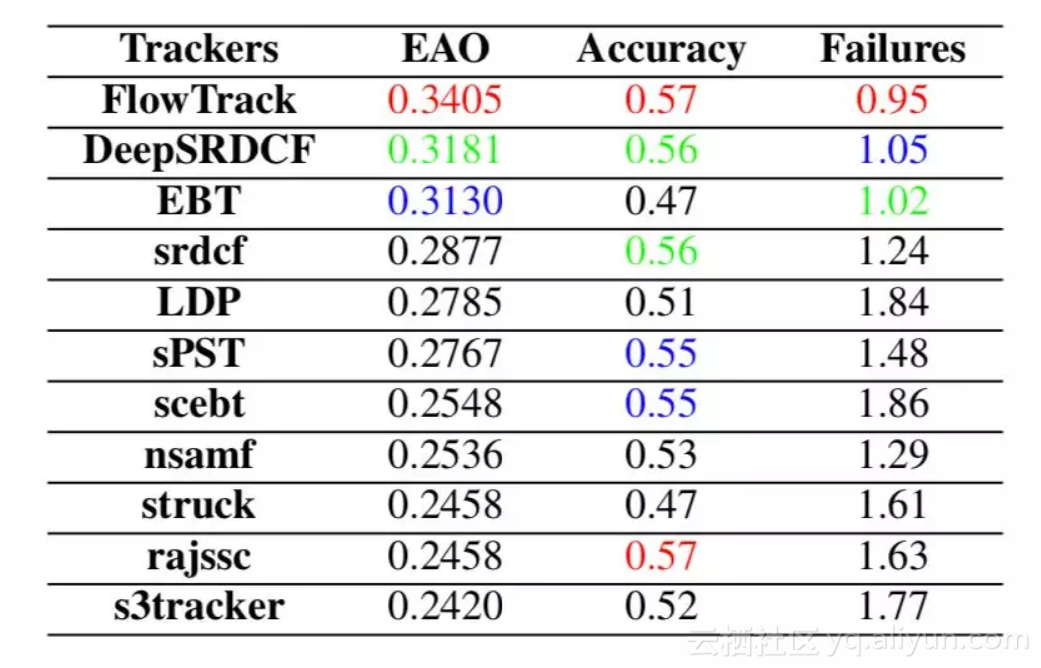
▲ VOT2015上面具体的accuracy和robustness
▲ VOT2015 EAO Ranking
问:网络中元素比较多,究竟哪一块在 work?
答:我们做了 ablation 分析,结果如下,值得注意的是加入固定的光流信息之后,某些数据集上的 performance 反而下降了;我们估计是由于光流信息的(不高的)质量和(不太)对齐造成的。
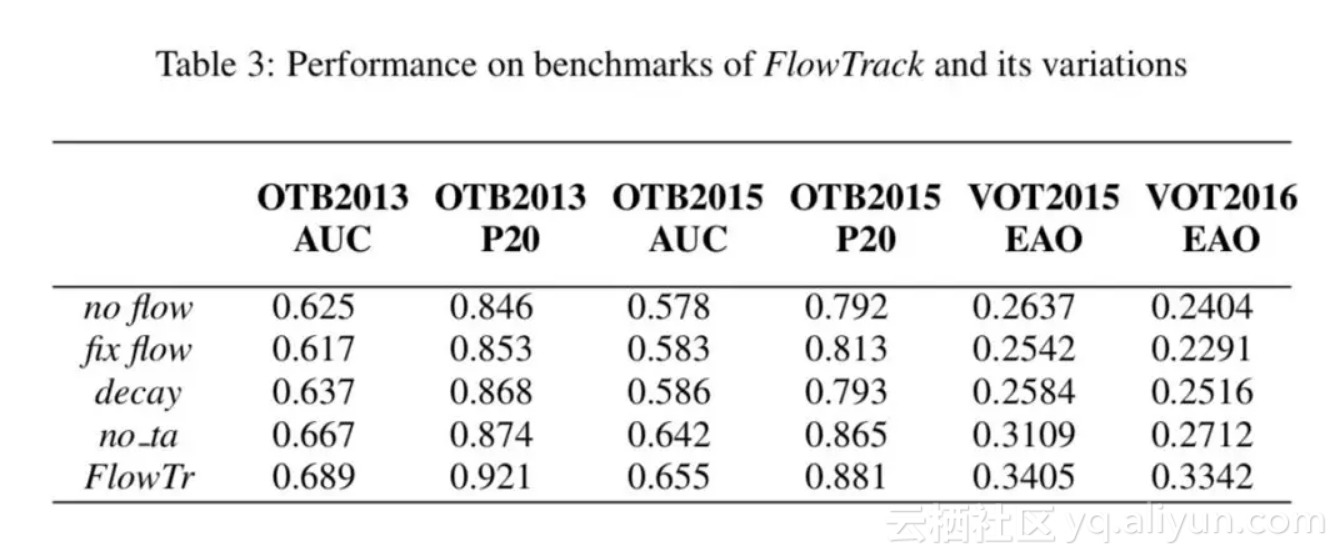
▲ ablation分析,FlowTr是完整的FlowTrack,其余从上到下分别是:不用Flow信息的,用Flow信息但不进行端到端训练的,用time-decay方式进行融合的,不用temporal attention的
问:为什么选择 warp 的帧间隔是 1 而不是 2,4,8 这种,这样的话不是更能包含更多的 temporal information 吗?比如更长时间的遮挡的时候似乎更 work?
答:我们试了帧间隔为 1,2,4 的方案,当帧间隔为 2 和 4 的时候(即 warp t-2,t-4... 或者 t-4,t-8...),虽然在某些情况(比如遮挡)能取得更好的结果,但整体性能是下降的。
我们猜测是由于帧间隔大了之后,Flow 信息的质量可能会变差(毕竟 FlowNet 是针对小位移的)。
问:fixed Flow 和训练之后的 Flow 有什么区别?
答:训练之后的 Flow 相比较固定的 FlowNet 提取出来的 Flow,质量更高,对齐地更准,一个例子如下图:

▲ 左列:待输入 Flow 网络的两张图;中列:固定的 FlowNet 和训练之后的 Flow 网络提取的 Flow;右列:Flow mask 到原图(注意:都是 mask 到左下角的图上)。
问:和 ICPR 那一篇 Deep Motion Feature for Visual Tracking 那一篇结果对比怎么样?
答:OP 指标可以超过,速度比他快很多(他的速度不包含提取 Flow 的时间),见下表:

▲ 和ICPR文章的对比
问:在 VOT2017 上面的结果怎么样?
答:还不错,EAO 目前可以排名第二,见下图:
▲ VOT2017结果
原文发布时间为:2018-04-23
本文作者:朱政
本文来自云栖社区合作伙伴“PaperWeekly”,了解相关信息可以关注“PaperWeekly”。




