在中国物流快速发展的今天,日均包裹量已经突破1亿,如何确保1亿包裹在合理的时间之内送达收件人,并且能够在收件人反馈之前,及时处理那些没有在合理时间内运输的包裹,从而提高物流整个链路的时效体验,已经成为亟待解决的关键问题。
要想解决问题,首先要发现问题!有效、及时地发现问题离不开对这1亿包裹运输过程中每个环节实时监控,而要实现这个场景,就需要一个能够支撑起如此量级的实时定时调度系统。这就是本文的主题:轻量级定时任务调度引擎的设计。

传统方案
针对上文提到的问题场景,一般的做法是将定时任务写入数据库,通过一个线程定时查询出将要到期的任务,再执行任务相关逻辑。该方案的优点是实现简单,尤其适合单机或者业务量比较小的场景来。但是缺点也很明显:在分布式且业务量较大的场景中会引入很多复杂性。首先,需要设计一套合理的分库分表逻辑,以及集群任务负载逻辑。其次,即使做到这些,也会由于某些场景定时任务时间集中在某个时间点,导致集群单节点压力过大。再次,需要合理的预估容量,否则后续线性存储扩容将会非常复杂。
我们发现,上述方案的主要问题其实是定时任务时间和任务存储的耦合。如果能够将时间和存储解耦,任务的存储就等于是无状态的,这样对存储的可选择性范围会大很多,对存储的约束也大大降低!
下文将会介绍如何通过时间轮思想将定时任务的时间和任务本身进行解耦,从而在设计和性能上得到很大的提升。
时间轮基本介绍
时间轮方案将现实生活中的时钟概念引入到软件设计中,主要思路是定义一个时钟周期(比如时钟的12小时)和步长(比如时钟的一秒走一次),当指针每走一步的时候,会获取当前时钟刻度上挂载的任务并执行,整体结构如图1。
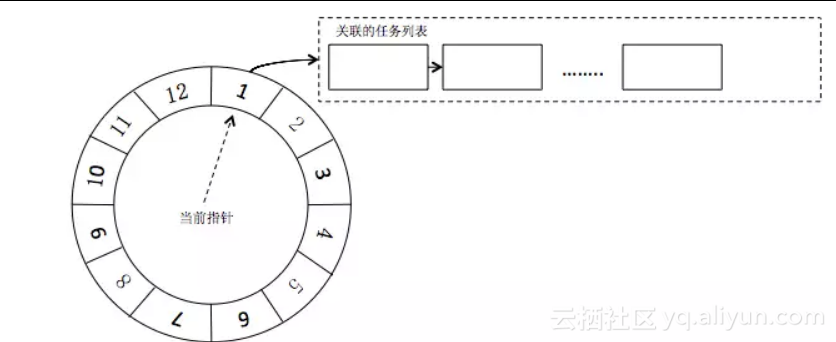
图1 时间轮算法
从上图可以看到,对于时间的计算是交给一个类似时钟的组件来做,而任务是通过一个指针或者引用去关联某个刻度上到期的定时任务,这样就能够将定时任务的存储和时间进行解耦,时钟组件难度不大,以何种方式存储这些任务数据,是时间轮方案的关键。
时间轮定时任务的存储
我们发现,阿里巴巴MQ(RocketMQ商业化版本,后文统称为阿里巴巴MQ)对其定时消息的改造[1]很有借鉴意义,老方案基于定时轮询的方式check消息是否到期,这种方案对于离散的时间比较受限,所以也就导致老版本只能支持几种延迟级别的定时消息。为了解决这个问题,阿里巴巴MQ团队将原方案改造为基于时间轮+链表的方案,从而既能支持离散的定时消息,也能够解决传统时间轮每个刻度需要管理各自任务列表的复杂性。
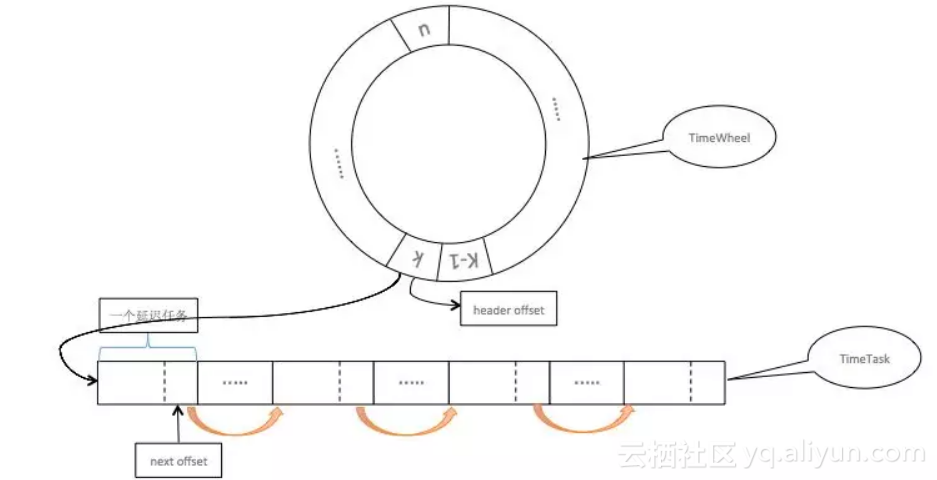
图2 阿里巴巴MQ定时消息方案
图2简明的描述了方案的关键点,其设计思路就是将任务列表写入到磁盘,并且在磁盘中采用链表的方式将任务列表串起来,要达到这种串起来的效果,需要每个任务中都有一个指向下一个任务的磁盘offset,只需要拿到链表的头便可以获取整个任务链表,于是在该方案中,时间轮的时间刻度不需要存储所有的任务列表,只需要存储链表的头即可,从而将内存的压力释放出来。
该方案对于中间件这样定位的系统来说是可以接受的,但对于一个定位在普通应用的系统来说,对部署的要求就显得过高了,因为你需要一块固定的硬盘。在当前容器化以及容量动态管理的趋势下,一个普通应用需要依赖一块固定的磁盘,对系统的运维和部署都会带来额外的复杂度。于是在此基础上形成本文重点介绍的轻量级定时任务调度引擎。
轻量级定时任务调度引擎
轻量级定时任务调度引擎借鉴了时间轮方案的核心思想,同时去除了系统对磁盘的依赖。既然不能将数据直接存储在磁盘,那只能依托专门的存储服务(比如Hbase,Redis等)来进行存储。于是就将下层的存储替换成了一种存储服务能够满足的结构:
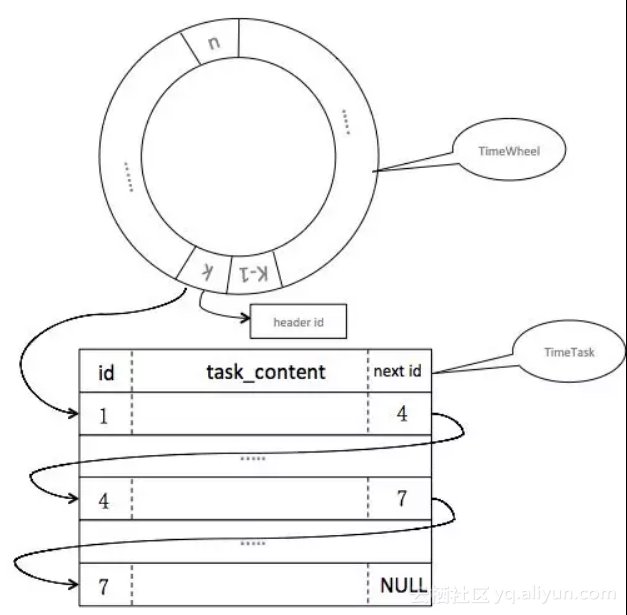
图3 调整后的时间轮+链表方案
将任务设计成一种结构化的表,并且将上面的offset替换成了一个任务ID(图2是文件的offset),并且通过ID将整个任务链表串起来,时间轮上只关联链表头的ID。这里对MQ方案改造的点只是将磁盘的offset替换成一个ID,从而解耦对磁盘的依赖。
方案到现在感觉可以行得通,但是又引出了另外两个问题:
问题1:单一链表无法并行提取,从而影响提取效率,对于某个时刻有大量定时任务的时候,定时任务处理的延迟会比较严重;
问题2:既然任务不是存储在本机磁盘了,表明整个集群的定时任务是集中存储,而集群中各个节点都拥有自己的时间轮,那么集群里面每个节点重启之后如何恢复?集群扩容&缩容如何自动管理?
任务链表分区——加速单一链表提取
链表的好处是在内存中不用存储整个任务列表,而只需要存储一个简单的ID,这样减少了内存的消耗,但是却带来了另一个问题。众所周知,链表的特性是对写友好,但读的效率却并不高,如果某个时刻需要挂载很长的任务链表,那链表的方式是完全不能利用并发来提高读的效率。
如何能够提高某个时间的任务队列提取的效率呢?这里利用分区的原理,将某个时刻的单一链表通过分区的方式拆分成多个链表,当将某个时间点的任务提取的时候,可以根据链表集合大小来并行处理,从而可以加速整个任务提取的速度。所以方案调整成图4:
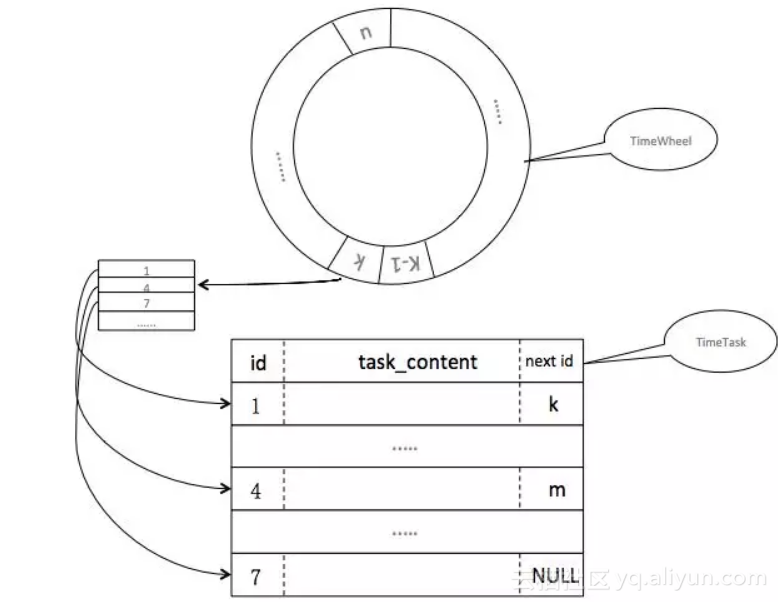
图4 分区后的设计方案
集群管理——集群节点的自我识别
解决了定时任务的存储问题和单一链表提取任务的效率问题,好像整个方案都已经ready了,但是还有另一个重要的问题前面没有考虑进去,就是集群部署后节点重启后如何进行恢复?比如需要知道重启之前的时间轮刻度,需要知道重启之间时间轮刻度上的定时任务链表数据等,后面我统一将这种数据称之为时间轮元数据。如果任务写入磁盘,某个机器的重启,可以从本地磁盘加载当前节点的时间轮元数据来进行恢复;而如果不是通过磁盘来实现,那就带来问题2-1:一台机器在重启之后怎么获取它重启之前的时间轮元数据呢?
通过上面的解决定时任务存储问题,对于元数据的存储也可以借助专门的存储服务,但是由于集群的各个节点是无状态的,所以各个节点启动的时候,并不知道如何从存储服务中读取属于自己的元数据(也就是查询的条件),这便引出了问题2-2:集群节点怎么获取属于它的元数据呢?
可能第一想到的就是将元数据和节点ip或者mac地址关联上,但是在现在动态容量调度的情况下,一个机器拥有一个固定的ip也是很奢侈的,因为你不能保证你的应用会运行在哪台机器上。既然物理环境不能依赖,就只能依赖逻辑环境来对每个节点的时间轮进行区分了,于是就通过对集群每个节点分配一个在集群中唯一的逻辑ID,每台机器通过自己拿到的ID去获取时间轮数据。于是又引出了问题2-3:这个ID由谁来分配? 这就是Master节点。
在整个集群中需要选举出一个节点为Master,所有的其他节点会将自己注册到Master节点中,然后再由Master节点分配一个ID给各个节点,从而通过这个ID到存储服务中获取之前时间轮的元数据信息,最后初始化时间轮。图5和图6是该过程的描述图:
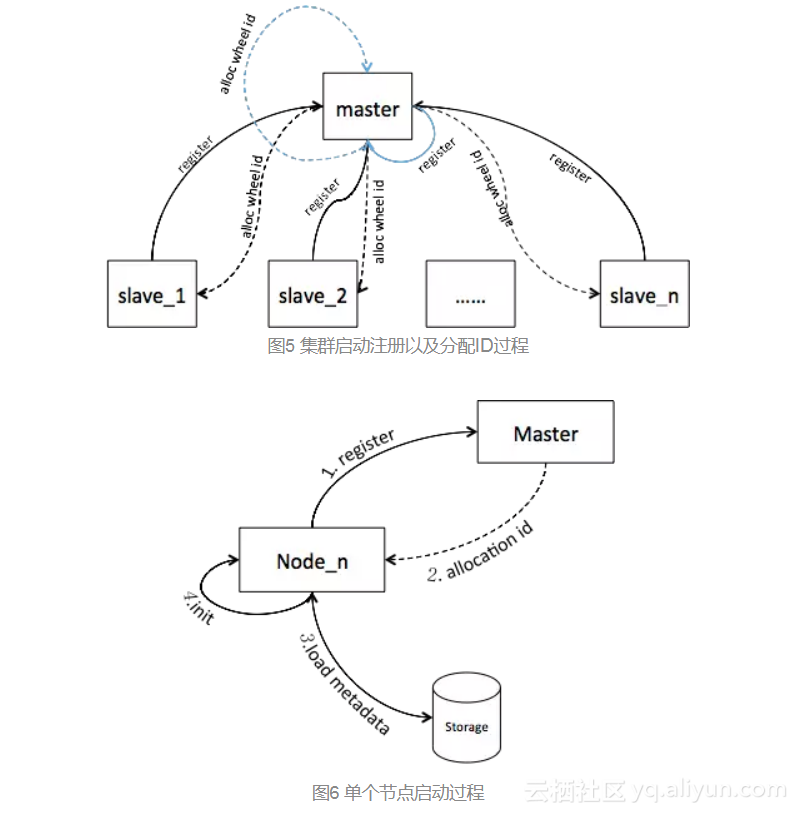
图5展示了节点注册和获取ID的过程,注意, Master节点自身也注册并且分配了ID,这是因为对一个普通应用来说,并没有Master和非Master之分,Master也是会参与整个业务的计算的,只不过它除了参与业务计算之外,额外还要进行集群的管理。
集群自动化管理——自动感知扩容&缩容
上文引出了Master节点,并且所有节点都会将自己注册给Master(包括Master自己),于是基于Master就可以构建出一套集群管理的机制。对于普通应用来说,集群的扩容缩容是很正常的操作,在动态调度的场景下,扩缩容操作甚至连应用owner都不感知,那么集群能够感知自己被扩容了和缩容了么?答案是肯定的,因为存在一个Master节点,而Master可以感知到集群的其他节点的存活状态,Master发现集群的容量变化,从而做出集群的负载调整。
定时任务提取集群化——集群压力软负载
上文通过将时间轮上的某个时间关联单一链表拆分成多个链表来提高提取任务的并发度,同时也已构建出了一套集群管理方案。如果这个并发度只是在单节点,只让该节点自己提取,将会因为某个时刻的当前节点到期的任务数量很大,从而导致集群中某些节点的压力会很大。为了能够更加合理的利用集群计算能力,那么可以基于上面的集群管理能力,对方案再进一步优化:将提取的到期任务链表集合通过软负载的方式分发给集群其他节点,同时由于任务的数据是集中存储的,只要其他节点能够拿到任务链表头的ID,便可以提取得到该链表的所有任务,从而集群的压力也将被平摊,图7是该过程的交互过程:
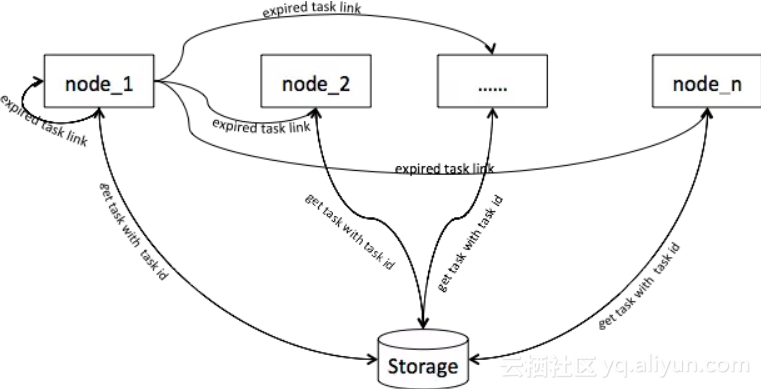
图7 集群并行提取任务
总结
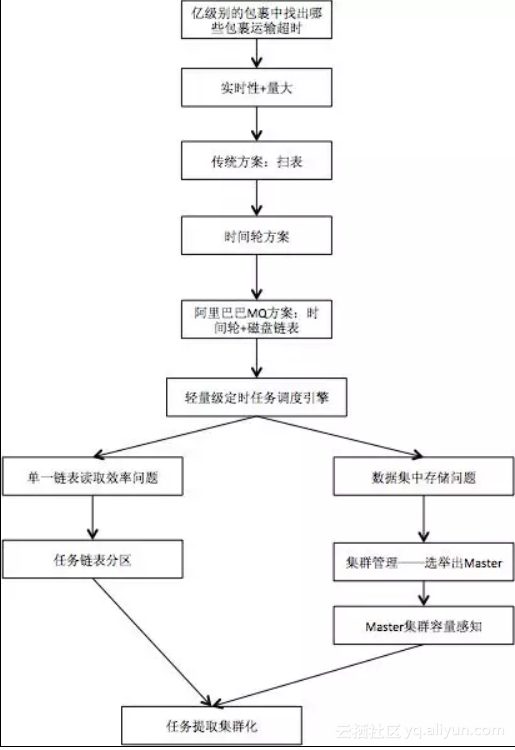
上面对整个方案的演进,以及各个阶段遇到的问题进行了详细的介绍,可能还有一些点没有太深入,大家可以回复留言中详细讨论。下面结合上面的内容,做了一个简单的流程梳理,以方便大家对全文的理解。