NVIDIA宣布完成了推理优化工具TensorRT与TensorFlow将集成在一起工作。TensorRT集成将可用于TensorFlow1.7版本。TensorFlow仍然是当今最受欢迎的深度学习框架,而NVIDIA TensorRT通过对GPU平台的优化和提高性能,加速了深度学习推理。我们希望使用TensorRT能为TensorFlow用户提供尽可能高的推理性能以及接近透明的工作流。新的集成提供了一个简单的API,它能够使用TensorFlow中的TensorRT实现FP16和INT8的优化。对于ResNet-50基准测试的低延迟运行,TensorRT将TensorFlow推理速度提高了8倍。
下面让我们看一下工作流的概述,以及一些例子以便帮助入门。
TensorFlow内的子图优化
使用与TensorRT集成的TensorFlow优化并执行兼容的子图,让TensorFlow执行剩余的图。你仍然可以使用TensorFlow广泛且灵活的功能集,但是TensorRT能尽可能的解析模型,并对图的部分应用进行优化。而且TensorFlow程序只需要几行新代码就可以促进集成。将TensorRT优化应用于TensorFlow模型时需要导出图表,在某些情况下还需要手动导入某些不受支持的TensorFlow层,这可能会非常耗时。
现在让我们逐步了解工作流。在冻结TensorFlow图进行推理后,使用TensorRT对TensorFlow子图进行优化。然后TensorRT用TensorRT优化节点替换每个支持的子图,生成一个在TensorFlow中运行的冻结图来进行推断。图1说明了工作流。
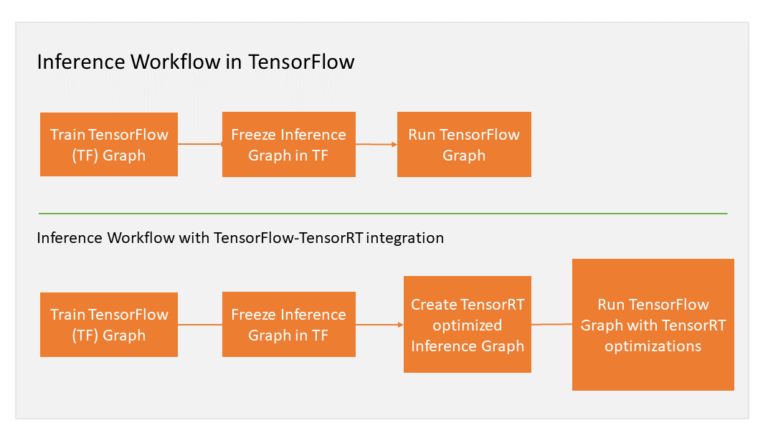
图一所示:在推理过程中使用TensorRT时的工作流图
TensorFlow在所有可支持领域内执行图形,并调用TensorRT执行TensorRT优化节点。例如,假设图形有三个段,A、B和C,片段B经过了TensorRT优化并被一个节点替换。那么在推理过程中,TensorFlow执行A,然后调用TensorRT执行B,之后继续TensorFlow执行C。从用户角度来看,该过程和之前使用TensorFlow执行图形一样。现在让我们看看应用这个工作流的一个示例。
新的TensorFlow API
让我们看看如何使用新的TensorFlow api将TensorRT优化应用到TensorFlow图中。首先在现有的TensorFlow GPU代码中添加几行代码:
1ã 在GPU内存中指定TensorFlow可用的部分,TensorRT可以使用剩余的内存。
2ã 让TensorRT分析TensorFlow图,应用优化,并用TensorRT节点替换子图。
使用GPUOptions函数中的新参数per_process_gpu_memory_fraction指定TensorRT可以使用的GPU部分。该参数需要在第一次启动TensorFlow-TensorRT时进行设置。例如,0.67意味着将为TensorFlow分配67%的GPU内存,而剩下的33%用于TensorRT引擎。

使用新函数create_inference_graph将TensorRT优化应用于冻结图。然后,TensorRT将一个冻结的TensorFlow图作为输入,并返回一个带有TensorRT节点的优化图。参见下面的示例代码片段:

让我们看一下函数的参数:
frozen_graph_def: 冻结的TensorFlow图表
put_node_name: 带有输出节点名称的字符串列表,例如
max_batch_size: 整数,输入批次的大小,如16。
max_workspace_size_bytes:整数,可用于TensorRT的最大GPU内存。
precision_mode: 字符串,允许的值为“FP32”,“FP16”或“INT8”。
可以通过设置per_process_gpu_memory_fraction和max_workspace_size_bytes参数来获得最佳性能。例如,将per_process_gpu_memory_fraction参数设置为(12 - 4)/ 12 = 0.67,将max_workspace_size_bytes参数设置为4000000000,用于12GB的GPU,以便为TensorRT引擎分配4GB。
在TensorBoard中将优化后的图形可视化
首先在TensorBoard中应用TensorRT优化,然后将对ResNet-50节点图的更改进行可视化。如图2所示,TensorRT几乎优化了整个图形,并用“my_trt_po0”节点进行替换(用红色突出显示)。根据模型中的图层和操作,TensorRT节点会因优化而替换部分模型。
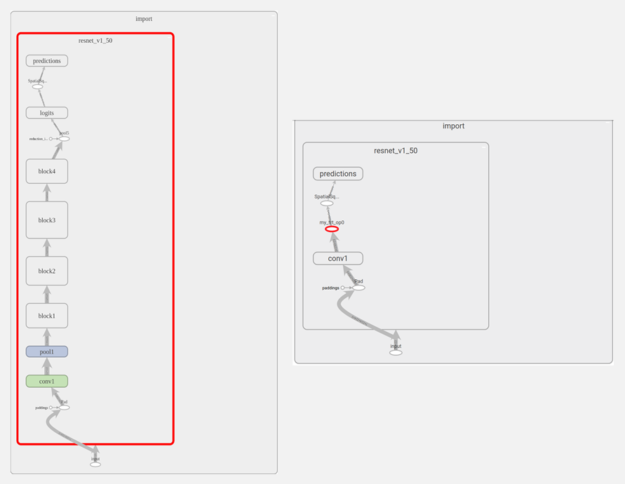
图2.左:TensorBoard中的ResNet-50图。右:经过TensorRT优化并且子图被TensorRT节点替换之后。
要注意TensorRT节点下的名为“conv1”的节点。它实际上不是一个卷积层,而是一种显示为conv1的从NHWC到NCHW的转置操作。这是因为TensorBoard仅显示层次结构中顶部节点的名称,而不是默认情况下的单个操作。
自动使用TensorBoard Cores
与FP32和FP64相比,使用半精度(即FP16)算法能够减少神经网络的内存使用,而且还能够花费更少的时间部署更大的网络。每个Tensor Core包含一个4x4x4的矩阵处理阵列来完成D=AxB+C的运算,其中A、B、C、D是4x4的矩阵,如图3所示。矩阵相乘的输入A和B是FP16矩阵,相加矩阵C和D可能是FP16矩阵或FP32矩阵。
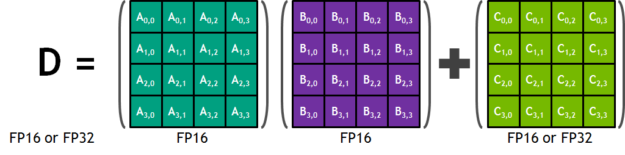
图3.Tensor Cores上的矩阵处理运算
在使用半精度算法时,TensorRT会自动在Volta GPU中使用Tensor Cores进行推理。NVIDIA Tesla V100上的Tensor Cores峰值性能比双精度(FP64)快大约10倍,比单精度(FP32)快4倍。只需使用“FP16”作为create_inference_graph函数中的precision_mode参数的值即可启用半精度,如下所示。

图4显示了使用NVIDIA Volta Tensor Cores与仅运行TensorFlow的TensorFlow-TensorRT集成的差距,ResNet-50在7 ms延迟下执行速度提高了8倍。
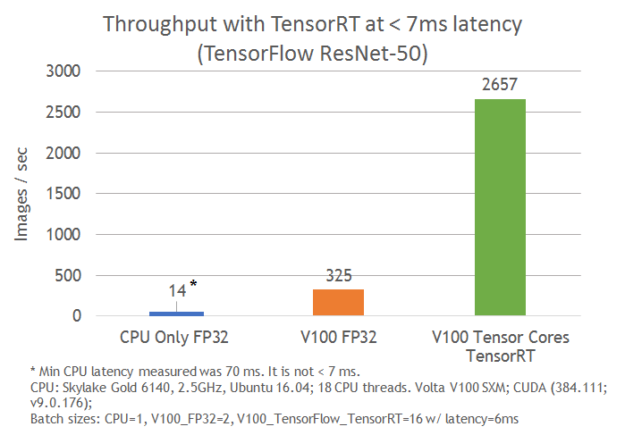
图4.ResNet-50推理吞吐量性能
优化INT8推理性能
使用INT8精度进行推理能够进一步提高计算速度并降低宽带要求。动态范围的减少使得神经网络的表示权重和激活变得更加有挑战性。表1说明了动态范围的影响。

表1:FP32 vs FP16 vs INT8动态范围
TensorRT提供了在单精度(FP32)和半精度(FP16)中接受训练的模型,并将它们转换为用于INT8量化的部署,同时能够将精度损失降至最低。要想模型能够使用INT8进行部署,需要在应用TensorRT优化之前校准经过训练的FP32模型。剩下的工作流保持不变。图5显示了更新后的工作流。
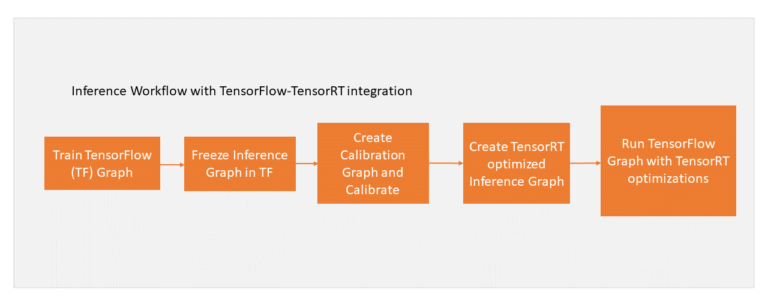
图5.更新后的TensorFlow工作流,包括TensorRT优化之前的INT8校准
首先使用create_inference_graph函数,并将precision_mode参数设置为“INT8”来校准模型。这个函数的输出是一个冻结的TensorFlow图,可以用来校准。

接下来用校准数据来执行校准图。TensorRT根据节点数据的分布来量化节点的权重。校准数据非常重要,因为它可以密切反应生产中问题数据集的分布。我们建议在首次使用INT8校准模板是检查推理期间的错误积累。
在校准数据上执行图形后,使用calib_graph_to_infer_graph函数对校准图形应用TensorRT优化。还可以用为INT8优化的TensorRT节点替换TensorFlow子图。函数的输出是一个冻结的TensorFlow图表,可以像往常一样用于推理。

这两个命令可以启用TensorFlow模型的INT8精度推断。所有运行的这些示例代码请点击这里。
TensorRT集成可用性
我们将继续与TensorFlow团队紧密合作,以加强TensorRT集成的可用性。我们期望新的解决方案在能够保持TensorFlow易用性和灵活性的同时,可以确保NVIDIA GPU性能达到最高。而且由于TensorRT支持多种网络,所以开发人员不需要对现有代码进行任何更改,仅从自动更新中就能获益。
使用标准的pip安装过程来获得新的集成解决方案,一旦TensorFlor1.7可用:

详细的安装声明请点击。也可以在TensorFlow的NVIDIA GPU Cloud (NGC) 中获取集成。要想获得更多TensorRT信息请查看TensorRT页面。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《TensorRT Integration Speeds Up TensorFlow Inference | NVIDIA Developer Blog》
作者:Sami Kama,Julie Bernauer,Siddharth Sharma
译者:奥特曼,审校:袁虎。
文章为简译,更为详细的内容,请查看原文