强化学习(Reinforcement Learning)是当前最热门的研究课题之一,它在AlphaGo中大放光彩,同时也变得越来越受科研人员的喜爱。本文主要介绍关于强化学习5件有用的事儿。
1.强化学习是什么?与其它机器学习方法有什么关系?
强化学习是一种机器学习方法,它使Agent能够在交互式环境中年通过试验并根据自己的行动和经验反馈的错误来进行学习。虽然监督学习和强化学习都使用输入和输出之间的映射关系,但强化学习与监督学习不同,监督学习提供给Agent的反馈是执行任务的正确行为,而强化学习使用奖励和惩罚作为积极和消极行为的信号。
与无监督学习相比而言,强化学习在目标方面有所不同。虽然无监督学习的目标是找出数据点之间的相似性和不同性,但是在强化学习中,其目标是找到一个合适的动作模型,能够最大化Agent的累积奖励总额。下图表示了强化学习模型中涉及的基本思想和要素。
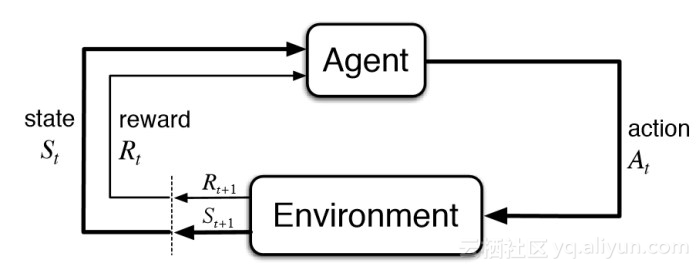
图1 强化学习模型框图
2.如何创建一个基本的强化学习问题?
在介绍本节内容之前,先介绍下强化学习问题中的一些关键术语:
环境(Environment):Agent操作的现实世界
状态(State):Agent的现状
奖励(Reward):来自环境的反馈
策略(Policy):将Agent的状态映射到动作的方法
价值(Value):Agent在特定状态下采取行动所得到的报酬
可以通过游戏很好地解释强化学习问题,以PacMan游戏为例,Agent的目标是在网络中吃掉食物,同时也要躲避幽灵。网格世界就是Agent的交互环境,如果PacMan吃掉食物,则获得奖励;但如果被幽灵杀死(输掉游戏),则受到惩罚。PacMan在网格中的位置就是其所处的状态,达到累积奖励总额则PacMan赢得比赛。
为了建立一个最优策略,Agent需要不断探索新的状态,同时最大化其所获奖励累积额度,这也被称作试探和权衡。
马尔可夫决策过程(MDPs)是用来描述强化学习环境的数学框架,几乎所有的强化学习问题都可以转化为MDps。MDP由一组有限环境状态S、每个状态中存在的一组可能行为A(s)、一个实值奖励函数R(s)以及一个转移模型P(s',s|a)组成。然而,现实世界环境可能更缺乏对动态环境的任何先验知识。在这种情况下,Model-free很有效。Model-free一直在每一步中去尝试学习最优的策略,在多次迭代后就得到了整个环境最优的策略(Q-learning)。
Q-learning是一种常用的模型,能够用于构建自己玩PacMan的Agent,它始终围绕着更新Q值,Q值表示在状态s时执行动作a的值,价值更新规则是Q-learning算法的核心。

图2 强化学习更新规则

图3 PacMan游戏
3.最常用的强化学习算法有哪些?
Q-learning和SARSA(State-Action-Reward-State-Action)是两种常用的model-free强化学习算法。虽然它们的探索策略不同,但是它们的开发策略却相似。虽然Q-learning是一种离线(off-policy)学习方法,其中Agent根据从另一个策略得到的行动a*学习价值,但SARSA是一个在线(on-policy)学习方法,它从目前的策略中获得当前行动的价值。这两种方法实施起来很简单,但缺乏一般性,因为无法估计出不可见状态的价值。
但以上问题可以通过更先进的算法来克服,比如使用神经网络估计Q值的Deep Q-Networks(DQN)。但是DQN只能处理离散、低维动作空间,因此对于高维、连续动作空间,科研人员发明了一种名为Deep Deterministic Policy Gradient(DDPG)的算法,该算法是一个model-free、离线演员评判家算法(Actor-critic algorithm)。
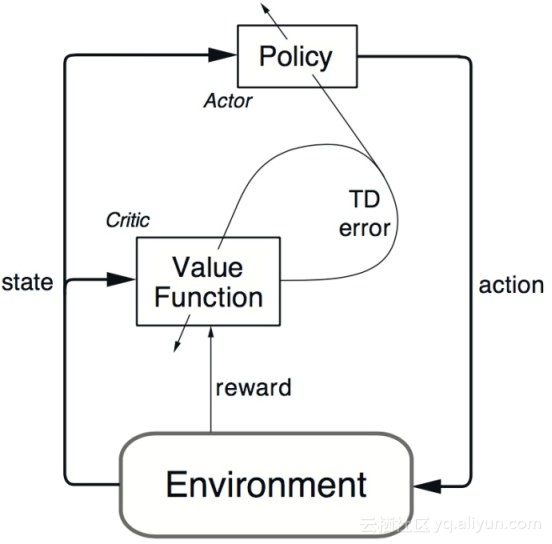
图4 Actor-critic algorithm
4.强化学习有哪些实际应用?
由于强化学习需要大量的数据,因此它最适用于模拟数据领域,比如游戏、机器人等。
在电脑游戏中,强化学习被广泛地应用于人工智能的构建中。AlphaGo Zero是围棋界第一个击败世界冠军的计算机程序,类似的还有ATARI游戏、西洋双陆棋等。
在机器人和工业自动化领域,强化学习被用于使机器人为其自身创建一个高效的自适应控制系统,从而能够从自己的经验和行为中学习。DeepMind在深度强化学习上的成果也是一个很好的例子。
强化学习的其它应用包括文本摘要引擎、对话代理(文本、语言),它们可以从用户交互中学习,并随着时间的推移而不断改进。此外,对于医疗保健和在线股票交易而言,基于强化学习的性能也是最佳的。
5.如何开始学习强化学习?
以下有一些相关的学习资源:
1.强化学习第二版(Reinforcement Learning-An Introduction),强化学习之父RicharSutton和其导师Andrew barto所写的书籍,一本不错的权威资料,在线阅读链接:http://incompleteideas.net/book/the-book-2nd.html
2.教材,David Sliver老师的视频讲座,是一份很好的强化学习入门课程。
3.其它关于强化学习的技术教程,由Pieter Abbeel和John Schulman所写(Open AI/Berkeley人工智能实验室)
4.从构建和测试强化学习agent开始学习之旅
5.该链接的博客能够帮助你使用仅仅130行Python代码启动并运行自己的第一个深度强化学习模型
6.DeepMind Lab是公开的一款开源立体游戏平台,专门为研究通用人工智能和机器学习系统而设计。
7.Project Malmo是微软公司开源的人工智能项目,也是支持人工智能领域的基础研究。
8.OpenAI Gym是开发和比较强化学习算法的工具包。
作者信息
Shweta Bhatt,人工智能研究员,数据科学家
个人主页:https://www.linkedin.com/in/shweta-bhatt-1a930b12/
本文由阿里云云栖社区组织翻译,文章原标题《5 Things You Need to Know about Reinforcement Learning》,作者:Shweta Bhatt,译者:海棠,审阅:袁虎。
文章为简译,更为详细的内容,请查看原文







