▲本文作者:Faerie,蚂蚁金服数据分析师
数据洞察之我见
在数据分析这个行业里,大家经常会谈论未来是大数据的时代,未来的竞争就是数据的竞争。
而麦肯锡的一项对700+家企业的调查显示,许多公司、尤其是传统公司还没有从大数据项目获得预期的结果,或者还没有获得相当高的投资回报率。大数据项目投入后收入平均仅增加了6%。我想一个很大的原因是传统企业大多是业务流程驱动,数据更多是作为一个报表使用。他们很少挖掘数据价值对企业流程的驱动,而是依靠个人经验进行决策。即使在使用数据分析的公司也多是停留在验证假设、监控效果的层面,通过数据分析获得洞察的很少,用分析直接指导行动的案例更是少之又少。Forrester的一项调研报告显示,有74%的公司希望通过数据驱动,但是只有29%把分析结论和运营动作建立了联系。
要从数据中得到价值,首先得弄清楚数据分析和洞察的区别。有很多作者讨论过这个话题,包括刚才上面贴的那篇forbes上面的文章,简言之,数据是没有经过过多的处理的原始信息,数据分析是从这些信息中发现的规律、趋势等,而数据洞察则是通过数据分析得出的价值,包括决策运营、预测机会等。

ConnectedInsight项目由来
作为客户服务及权益保障事业部智能运营中心的数据运营团队,我们的职责是支撑各服务线、智能调度中心及互联网渠道的数据分析。

虽然每条线都有几名数据分析同学做支持,但是由于数据分析需求往往都是由一个或小部分场景出发而提出,并未全局考虑数据和分析结果在整个业务线运营链路中的作用以及能为运营决策带来的影响,导致需求往往零散、冗杂且重复。同学们在不成体系的需求下熬夜跑代码、做报表、写分析报告也很艰难。
车品觉的《决战大数据》一书中写到:“大数据的力量来自触类旁通的关联。我们以前总是用数据来证明或企图说服工作上的盲点,而如今的数据不再是一加一的依据,而是具备了预测和开创新机的能力”。
书中还提到,“把分析的理念和框架变成数据产品,本质上是一个数据泛化的过程。这个过程非常重要,因为数据报告的需求会越来越多,如果没有泛化数据给使用数据的人,分析团队将永远被冗杂和重复的工作所困”。
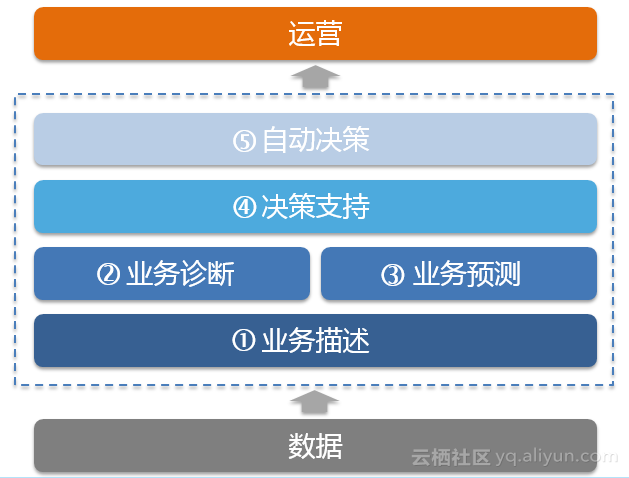
由此智能运营中心的数据运营团队和平台系统团队一起提出了ConnectedInsight项目,目的是为了从业务描述,业务诊断,业务预测,决策支持等方面,一步步完成从散点数据走到数据洞察。
基于此,我们和CTO 线人工智能部的AI运营团队以及CTO 线数据平台部DeepInsight产品团队做了共建,我们提供业务指标框架和分析思路,产品由AI运营团队主导开发,由DeepInsight提供后台能力,最终呈现在新客服数智产品上。
任重而道远,为了避免闭门造车,写下这篇分享,想吸引更多有相同想法的同学或者团队一起来探讨更好的解决方案。
ConnectedInsight项目“洞察”了什么
下面分别讲讲ConnectedInsight这个数据分析产品的四部分分别实现了或者将要实现的价值:
业务描述:描述业务上发生了什么。
服务线要了解自己的服务做得好不好,首先是需要看描述性的数据,过去我们是靠一张张报表实现这种描述功能的。但是单个的KPI报表是散的,比如我们分别看了一条服务线服务流程各个点上的数据报表,并不能直观的拼成一条链路图来了解整个业务流程的运营情况。基于此,我们开发了可定制化的业务数据流程图和异常高亮及预警功能,让用户能对业务现状一目了然,实现了从“点”延伸到“线面体”。
业务诊断:诊断为什么发生。
服务线看到数据流程图描述出来的某些环节做得不太好,就需要了解原因或者能改善的点。在此需求背景下,我们的产品开发了单指标多维度拆解和多指标相关贡献度拆解,实现了诊断指标异常定位原因,让运营同学能更高效的找到运营点。
业务预测:预测将要发生什么。
服务线要部署人工服务方案,必须提前知道服务量,我们通过预测产品化的方式让运营同学能高效的使用预测功能,合理的分配服务人力资源,同时也大大提升了分析同学预测产出时效。
决策支持:决策要做什么。
目前服务线运营同学在决定下个周期的派单部署方案时仍需靠人工重复、机械的统计历史数据和预测数据进行局部优化的方案选择,而我们的产品将实现用相关因子自动计算出全局最优的派单部署方案,大幅提高运营效率和准确率。
1、业务描述
#业务背景
业务描述就像汽车仪表盘,实时告诉你发生了什么,并适时警报提示等。分析师要做的事情就是搭建指标体系,进行各种维度的统计分析。我们过往的大量工作就是做这个,目前市面上很多BI产品也都能够满足这个层次的数据运营需求。
拿客户服务及权益保障事业部的国际线来举例,以往业务线运营同学看到的是拿老版Alisis搭建的各KPI的图表,如下图(图表数据非真实数据,仅用于展示),给出的是业务监控体系里散的“点”,并没有从业务全链路的角度给出用户能一眼看出业务整体有什么异常的大图。
#痛点
这么搭建业务监控的结果是什么呢?有没有发现业务看完数据后,经常会基于此提出额外的数据需求?
一般来讲,想看数据的人潜意识里是要成“体”的数据的,只是沟通过程中变成了“点”的需求,因为“点”简单容易讲明白,但是,这次给不了“体”的数据,下次还会围绕“体”的数据提各种“点”的需求,这个时候我们需要延伸一下,提前想需求方之所想,就不用来回往复了。
#解决方案
AI运营团队开发了流程图、树图、星环图等个性化分析组件,分析师使用这些组件完成产品内容搭建,并在我们的产品平台上配置各服务线的分析页面。
拿国际服务线举例,服务流程上用户可以拨打95188或者淘海外电话等进入热线人工服务,需要升级的提交工单,用户也可以进入支付宝钱包,英文钱包或PC端自助服务,未解决问题可以接入在线人工服务,需要升级的提交工单。
以往运营同学看的是各个环节的数据点报表,在我们构建的分析产品中,业务同学看到的是随业务流程变化的全链路图,整个链路图可定制、指标节点可设置预警高亮,从用户使用自助服务,到拨打热线电话,进入智能派单环节,再到人工客服接起,转入转出,升级提交工单,整个链路上哪一个节点出现异常一目了然。
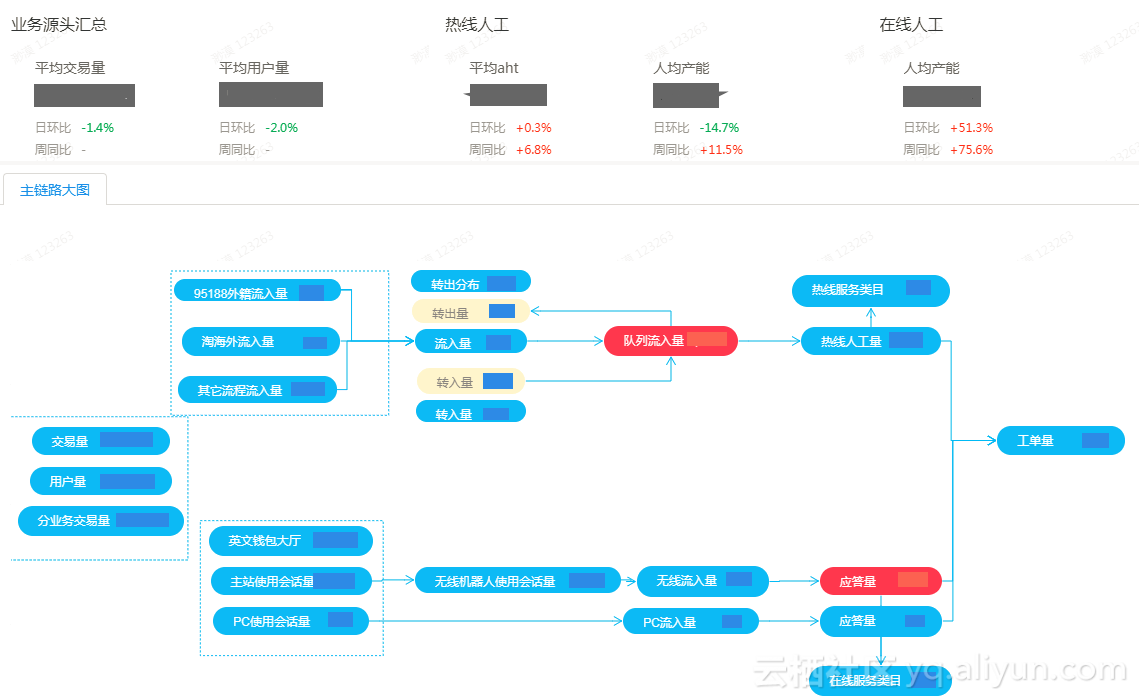
一个节点可以配置多个指标,主指标和相关指标。鼠标悬浮于节点可展示主指标及相关指标的趋势图,如果想进一步分析,可点击详情分析进入指标的下钻分析页面。
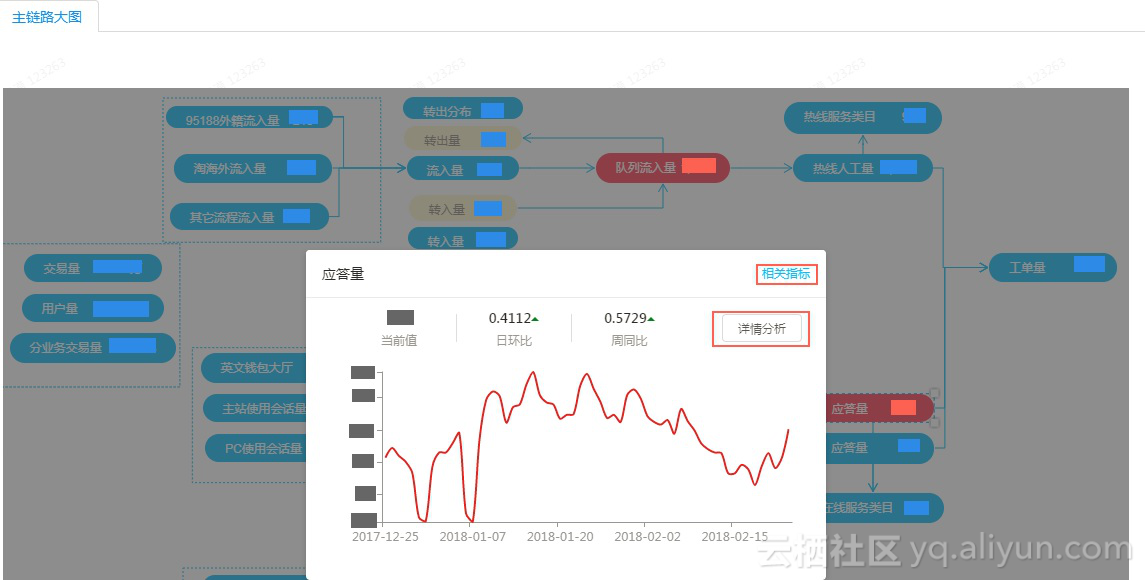
节点也可以配置堆积柱状图,这种配置在想展示业务占比等场景的时候非常好用。
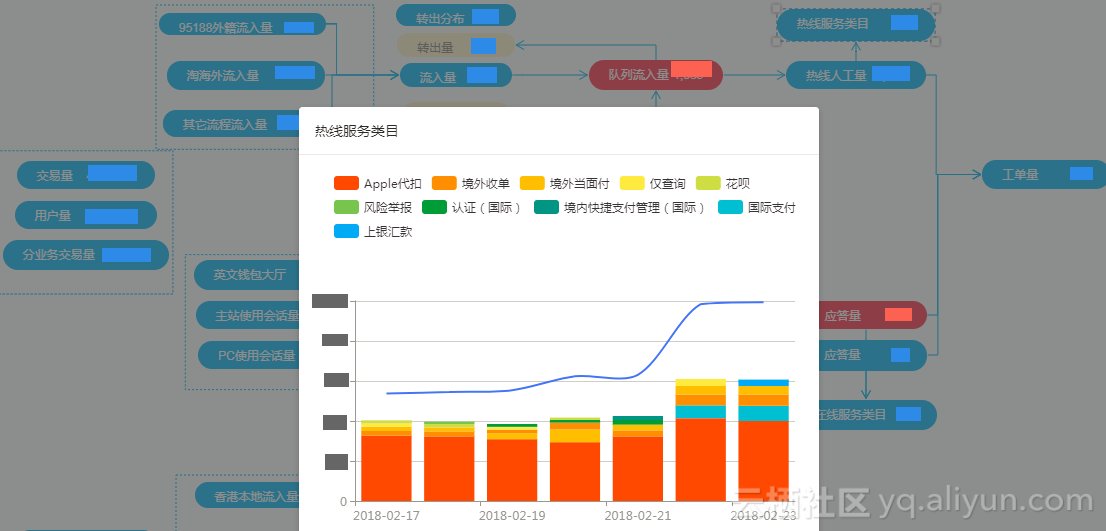
2、业务诊断
数据之间是存在因果联系的,这些联系有些容易通过业务来解释,而有些恰恰是业务无法直接看到,需要通过数据发现联系。在这个层面,需要数据分析师从整个业务链路和数据之间的联系出发,通过关联分析,波动分析,平衡计分卡等方法,找到数据变动的原因。
#痛点
过去我们提供给业务同学报表,用于日常指标的监控和原因分析。但通过报表找原因会存在两方面的问题:
沟通成本高、原因获取效率低:业务同学使用报表在众多指标中寻找原因,过程不熟练,分析师需要花时间和业务同学一起解读数据和寻找原因。
数据的落地性差:业务同学在面对需要立即解决问题的压力与大部分数据具有滞后性矛盾的背景下,往往是选择在没有数据分析结果时,先根据过往的运营经验采取措施,导致数据对实际指导的价值不高。
#解决方案
在ConnectedInsight的业务诊断里,我们进行了分析思路产品化。把分析师常用的分析思路和过程沉淀下来,用产品化的形式呈现,避免重复劳动,改善原因定位的时效性;业务同学不需要了解背后复杂的计算逻辑,直接看到分析结果,并且可以指派给专人负责。
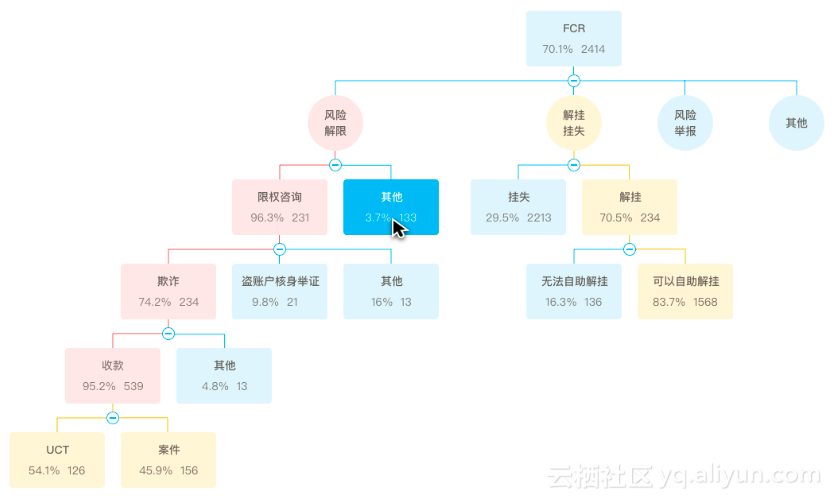
在初版产品中包含两种类型的业务诊断分析:单指标多维度型和多指标相关型。
单指标多维度型的业务诊断,我们要找出的是在一个指标能拆分成的多层树状结构中,具体是哪一层的哪一个节点的波动对这个指标的波动贡献度最大。
以服务线FCR(First Call Resolution,首次呼叫解决率,衡量客户服务及权益保障事业部解决客户问题能力的重要指标,一般为24小时内未重复来访的服务量占比)这个指标为例,通过下图所示的树状结构梳理安全服务线的服务量和FCR,拆解成一级业务,二级业务,三级业务的服务量和FCR的波动对整体FCR波动的贡献度,找出导致FCR波动的最主要的业务。如本例中限权咨询业务对当日FCR下降的贡献度为96.3%,运营同学应该着重关注该业务。
(*以下截图为demo,数据也非真实,最终版正在开发。)
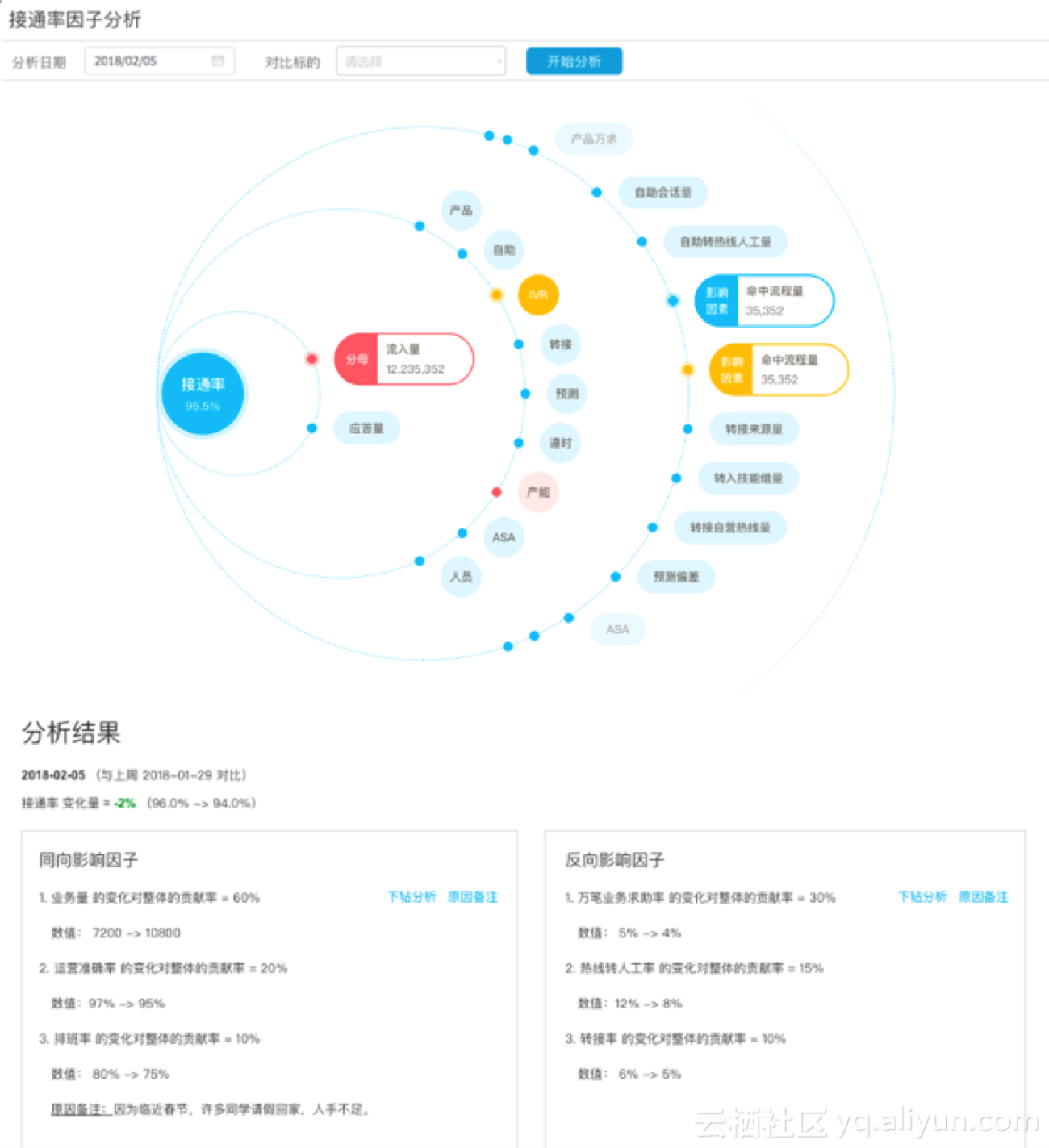
多指标相关型的业务诊断,我们要找出的是在一个指标有多个影响它的指标时,具体是哪一个指标的波动对这个指标的波动贡献度最大。这里多指标之间的不是简单的加减关系,而是转换为复杂的影响因子,通过影响因子量化指标之间的贡献度。
比如对热线接通率进行业务诊断,接通率分母是热线流入量,流入量是客户需求通过自助、转人工等,直到流转到热线处理环节的咨询量,因此流入量相关的影响因素有:产品、自助、智能派单、转接等;接通率的分子为热线应答量,应答量和通话时长、排班人数(人员)、现场运营效率(产能)等有关。通过下图把指标之间的关系环状表达出来,当选中某一指标后,该指标相关的影响指标也会高亮。而后台计算出的分析结果会给出指标波动的影响因子和各因子的贡献度。
(*以下截图为demo展示。)
3、业务预测
#业务背景
服务线的小二对接了蚂蚁所有业务线的服务量,随着业务不断拓展和复杂度的叠加,需要的咨询和审核小二人数不断增加,此时服务量如果可预测,就能基于现有资源做好排兵布阵,为业务线人员排班、人员招聘、和预算提供决策参考,在保证接通率、工单处理时效、进而提升用户体验的前提下,最大化人力资源利用,降低人力成本。
服务量包括:
咨询服务量,比如话务量,支付宝使用中电话咨询客服小二。
审核服务量,比如工单审核量,账户被冻结要上传身份证、人工审核。
#痛点
我们业务线分析师在过去对服务量的人工预测流程如下,需要3个分析师每周20+小时的工作,才能按时的完成预测工作。
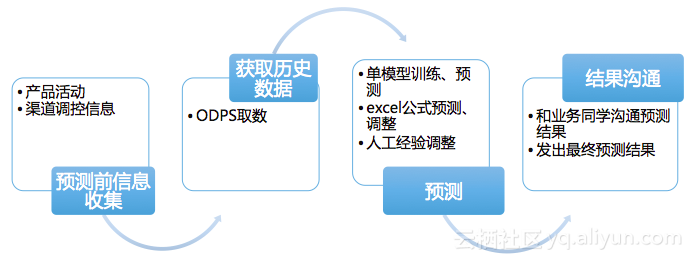
以上流程存在一些问题:
效率低:每条业务线的预测都要重复以上流程,这些因素涉及到多团队多部门协同,效率低下。随着公司业务的拓展及业务复杂性的增加,预测的工作量越来越大,铺人的方式解决不了根本问题。
预测标准不统一:预测分析师人肉做出预测,诸多零散个人经验贯穿其中,不同分析师预测结果会有偏差,不利于形成统一的方法和标准。
人工干预信息无法统一沉淀、不利于总结经验:各环节的线下沟通信息无统一沉淀,不利于事后评估产品事件影响、渠道调控,无法为后续预测调优提供指导。
#解决方案
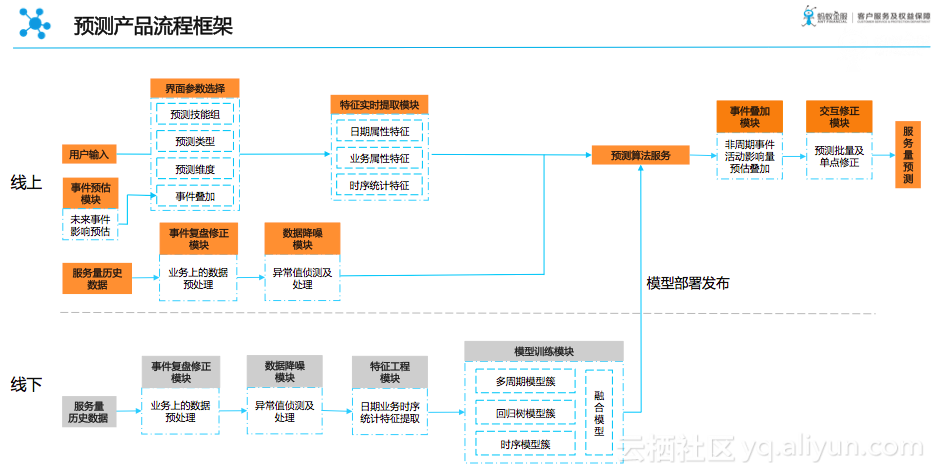
我们的ConnectedInsight中的预测功能,把预测融合模型(简单理解,既多个预测模型自动寻优)产品化,通过傻瓜式的点击按钮,让运营的同学可以自己做预测,把分析师的时间解放出来进一步优化模型。这个产品不仅大大的提升了预测产出时效(从1周到5分钟),更提高了预测的稳定性和准确率。
预测模型特征分解和产品框架如下图:

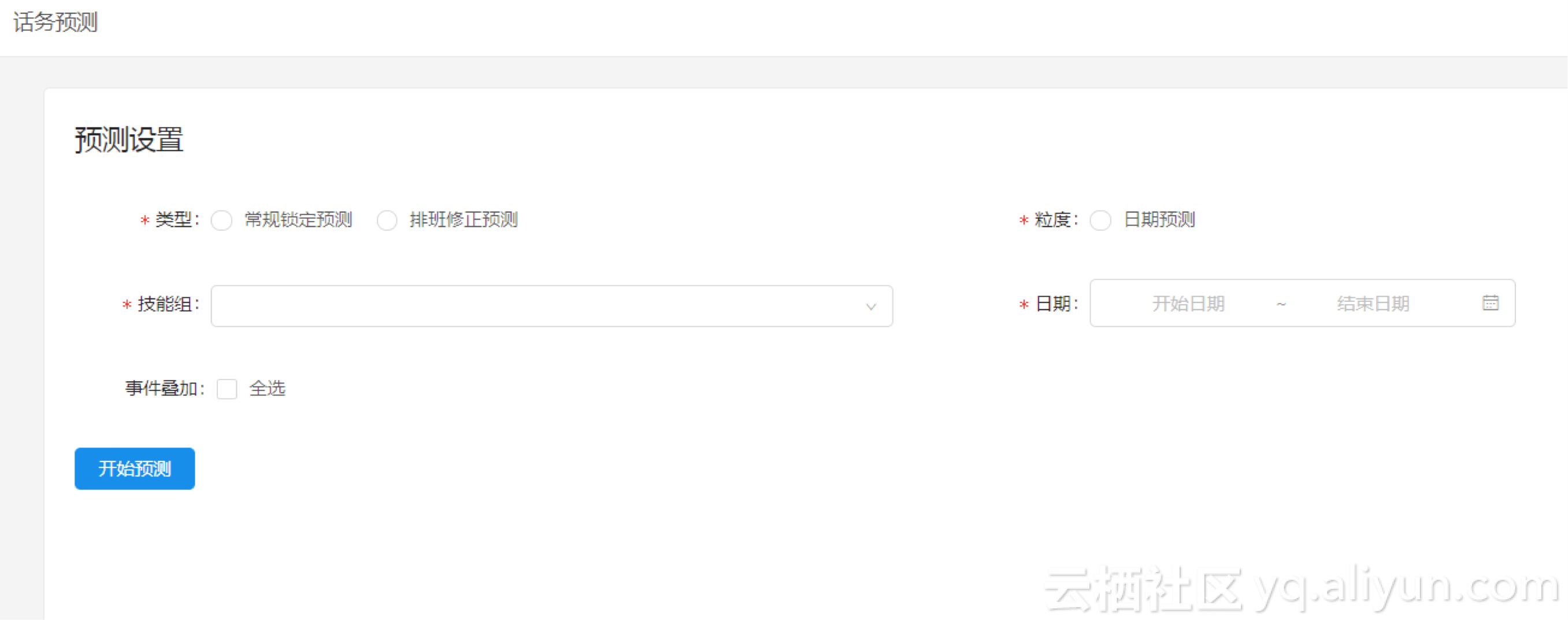
最终的预测产品如下,运营可以选择自己所在的小组(技能组)、和预测时间窗口(常规锁定预测、排班修正预测)。
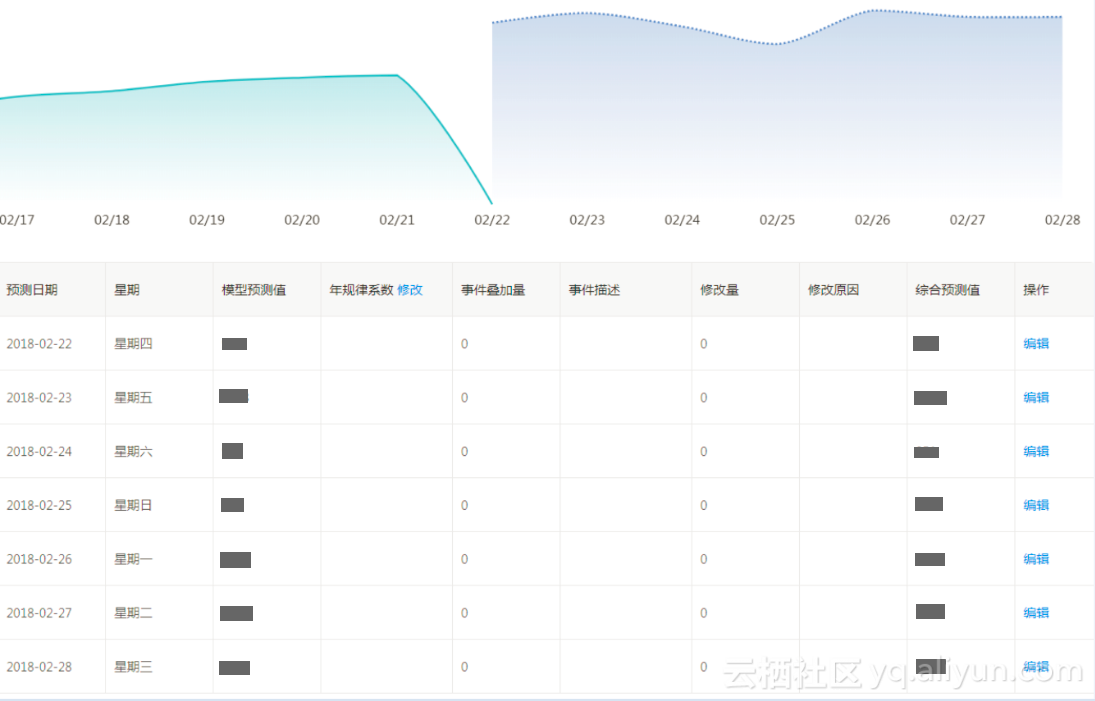
即可出现如下所示的话务量趋势图,并且可以根据自己掌握的信息对模型结果进行修正,修正后备注原因,便于模型的学习和调优,让后续预测结果更加精准。
4、决策支持
无论是上面讲的业务诊断还是业务预测,都是通过数据,对业务运营做决策支持。在这个环节,我们关注的从洞察到行动的过程,将数据洞察的结论提炼出来,告诉运营同学如何去行动是when、where、who and whom,指导业务的行动方向。例如,在我们通过多指标相关性分析发现影响接通率变化的因素有1. 业务量变化;2. 预测准确率;3.排班准确率。这三个因素都是insights,但是只有第2个和第3个因素是Actionable insights,而第一个因素,业务量的变化,这个更多是受业务发展的影响,并不是我们客户服务及权益保障事业部能够采取行动而改变的。在运营方根据我们的分析结果,做出实际运营动作之后,我们的产品会通过数据回流,进行action前后效果对比,从而形成数据化运营的闭环。
更进一步的决策支持和决策自动化我们已经在规划,细节期待有共同发展方向的团队一起协作探讨。
心得和鸣谢
最后,说一点这些年做数据分析的感悟。数据分析师每天都会被大量的业务需求压得喘不过起来,如果不能做到真正的数据驱动运营,分析师们慢慢的会对手头的工作疲惫而倦怠。而做好数据运营的关键就是数据洞察,真正的通过现象看本质,只有这样,才能抓住重点,减少零散需求,形成产品化,解放自己,幸福业务,让分析师能够有一天面朝大海,春暖花开。
项目还在进行中,未来要做的事情还很多,非常感谢全程支持我们的业务同学,数据洞察来源于业务,应用于业务,感谢各服务线的运营同学在提供业务需求和场景上给予了大力的支持。
更感谢我们的技术同学在技术资源上的鼎力协助,加班加点。同时也感谢CTO 线数据平台部DeepInsight产品团队的通力协作,上文中截图里的图形是此次合作中沉淀在DeepInsight里的可视化组件,如果大家有需要,也可以申请试用。
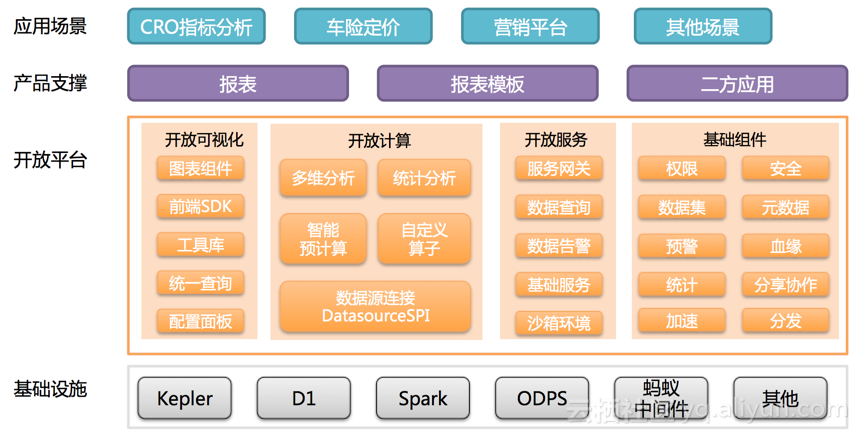
顺带也宣传下DeepInsight产品开放升级后的能力:DeepInsight不仅支持普通分析人员导入数据制作报表,而且支持业务线开发、算法同学进来,与DeepInsight可视化组件、底层数据集的计算能力接口对接,更高效完成业务的个性化解决方案。
DeepInsight产品开放能力模型图: