前言
CycleGAN 是发表于 ICCV17 的一篇 GAN 工作,可以让两个 domain 的图片互相转化。传统的 GAN 是单向生成,而 CycleGAN 是互相生成,网络是个环形,所以命名为 Cycle。
并且 CycleGAN 一个非常实用的地方就是输入的两张图片可以是任意的两张图片,也就是 unpaired。
单向GAN
读者可以按照原论文的顺序理解 CycleGAN,这里我按照自己的思路解读。CycleGAN 本质上是两个镜像对称的 GAN,构成了一个环形网络。其实只要理解了一半的单向 GAN 就等于理解了整个CycleGAN。
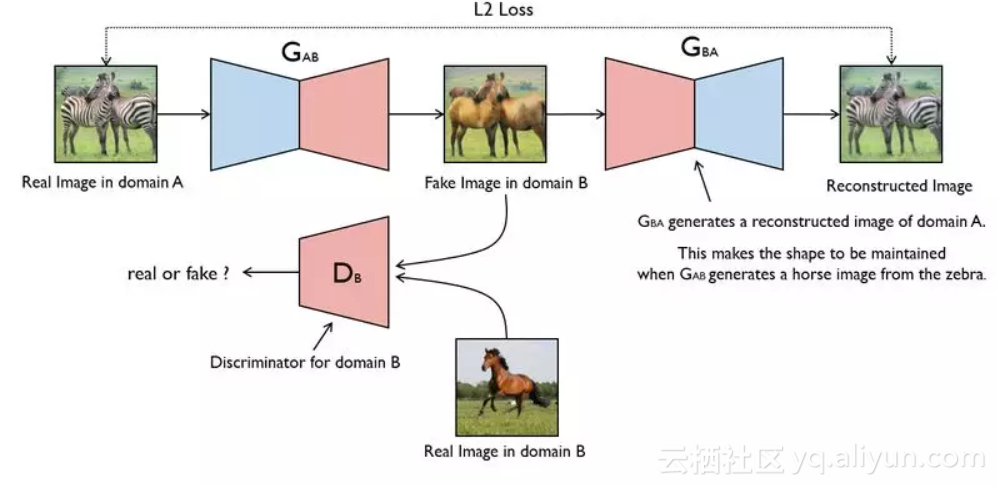
上图是一个单向 GAN 的示意图。我们希望能够把 domain A 的图片(命名为 a)转化为 domain B 的图片(命名为图片 b)。
为了实现这个过程,我们需要两个生成器 G_AB 和 G_BA,分别把 domain A 和 domain B 的图片进行互相转换。
图片 A 经过生成器 G_AB 表示为 Fake Image in domain B,用 G_AB(a) 表示。而 G_AB(a) 经过生辰器 G_BA 表示为图片 A 的重建图片,用 G_BA(G_AB(a)) 表示。
最后为了训练这个单向 GAN 需要两个 loss,分别是生成器的重建 loss 和判别器的判别 loss。
判别 loss:判别器 D_B 是用来判断输入的图片是否是真实的 domain B 图片,于是生成的假图片 G_AB(A) 和原始的真图片 B 都会输入到判别器里面,公示挺好理解的,就是一个 0,1 二分类的损失。最后的 loss 表示为:
生成 loss:生成器用来重建图片 a,目的是希望生成的图片 G_BA(G_AB(a)) 和原图 a 尽可能的相似,那么可以很简单的采取 L1 loss 或者 L2 loss。最后生成 loss 就表示为:
![]()
以上就是 A→B 单向 GAN 的原理。
CycleGAN
CycleGAN 其实就是一个 A→B 单向 GAN 加上一个 B→A 单向 GAN。两个 GAN 共享两个生成器,然后各自带一个判别器,所以加起来总共有两个判别器和两个生成器。一个单向 GAN 有两个 loss,而 CycleGAN 加起来总共有四个 loss。
CycleGAN 论文的原版原理图和公式如下,其实理解了单向 GAN 那么 CycleGAN 已经很好理解。
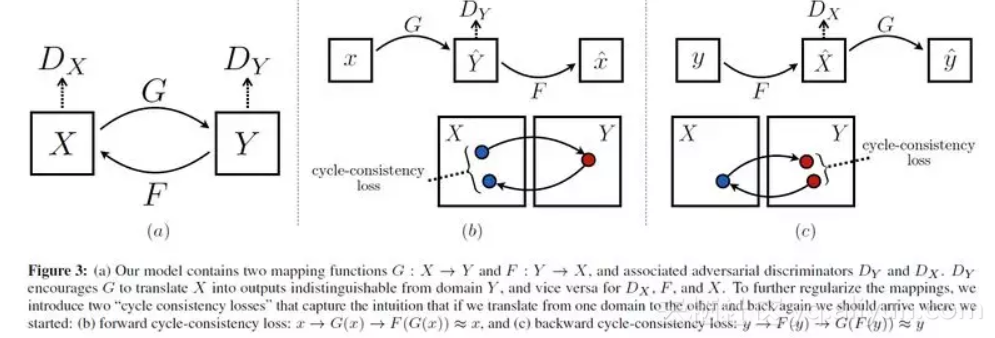
X→Y 的判别器损失为,字母换了一下,和上面的单向 GAN 是一样的:
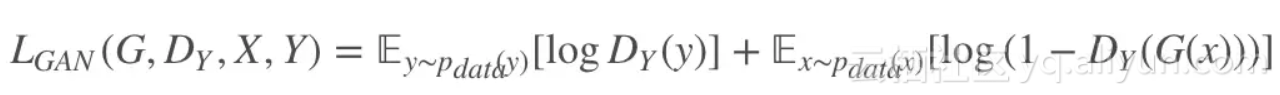
同理,Y→X 的判别器损失为:
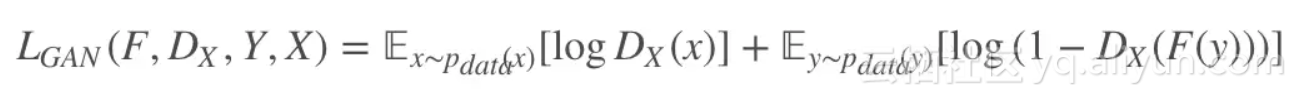
而两个生成器的 loss 加起来表示为:
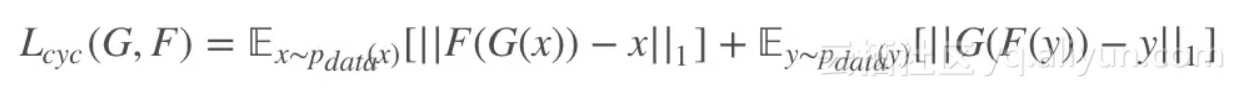
最终网络的所有损失加起来为:
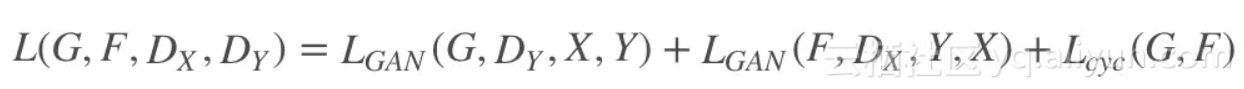
论文里面提到判别器如果是对数损失训练不是很稳定,所以改成的均方误差损失,如下:
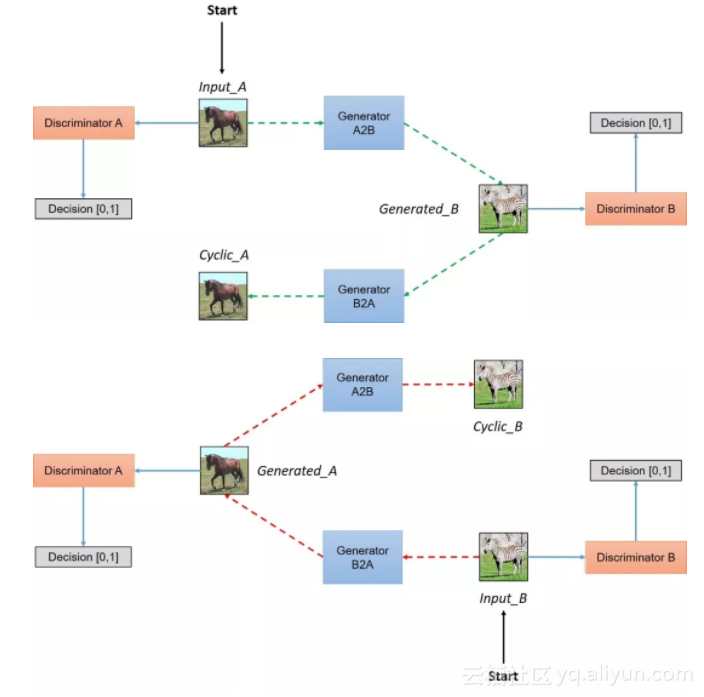
下面放一张网友们自制的 CycleGAN 示意图,比论文原版的更加直观。
效果展示
CycleGAN 的效果还是不错的,论文里给出了很多结果图,可以欣赏一下。

原文发布时间为:2018-03-14本文作者:罗浩本文来自云栖社区合作伙伴“ PaperWeekly”,了解相关信息可以关注“ PaperWeekly”微信公众号


