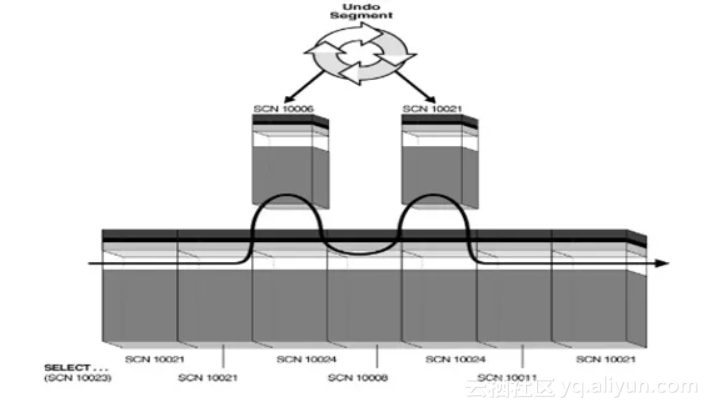
实际上,我们所说的保证同一时间点一致性读的概念,其背后是物理层面的 block 读,Oracle 会依据你发出 select 命令,记录下那一刻的 SCN 值,然后以这个 SCN 值去同所读的每个 block 上的 SCN 比较,如果读到的块上的 SCN 大于 select 发出时记录的 SCN,则需要利用 Undo 得到该 block 的前镜像,在内存中构造 CR 块(Consistent Read)。
一致性读(Consistent Gets,CG)是反映 SQL 语句性能的一项重要数据。它通常作为我们语句调优的指标。一般情况下,通过该数据可以比较两条语句或者同一语句的不同执行计划之间的性能。然而,某些情况下,它并不会完全反映出语句的性能。
分析探讨
我们先看两份性能统计数据:
| SQL代码 SQL 1: Statistics ----------------------- 0 recursive calls 0 db block gets 460 consistent gets 0 physical reads 0 redo size 1203583 bytes sent via SQL*Net to client 3868 bytes received via SQL*Net from client 306 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 4563 rows processed SQL 2: Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 167 consistent gets 0 physical reads 0 redo size 267325 bytes sent via SQL*Net to client 3868 bytes received via SQL*Net from client 306 SQL*Net roundtrips to/from client 1 sorts (memory) 0 sorts (disk) 4563 rows processed |
可以看到,第一条语句的 CG 是第二条语句的近3倍,看起来应该是第二条语句的性能更好。是否真是如此?
那再看看这两条语句是如何构造执行的:
| SQL代码 HelloDBA.COM> create table t1 as select * from dba_tables; Table created. HelloDBA.COM> create table t2 as select * from dba_users; Table created. HelloDBA.COM> exec dbms_stats.gather_table_stats('DEMO', 'T1'); PL/SQL procedure successfully completed. HelloDBA.COM> exec dbms_stats.gather_table_stats('DEMO', 'T2'); PL/SQL procedure successfully completed. HelloDBA.COM> set timing on HelloDBA.COM> set autot trace HelloDBA.COM> select * from t1; 4563 rows selected. Elapsed: 00:00:00.10 Execution Plan ---------------------------------------------------------- Plan hash value: 3617692013 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 4563 | 1078K| 49 (0)| 00:00:01 | | 1 | TABLE ACCESS FULL| T1 | 4563 | 1078K| 49 (0)| 00:00:01 | -------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 460 consistent gets 0 physical reads 0 redo size 1203583 bytes sent via SQL*Net to client 3868 bytes received via SQL*Net from client 306 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 4563 rows processed HelloDBA.COM> select * from t1, t2 where t2.username='SYS'; 4563 rows selected. Elapsed: 00:00:00.23 Execution Plan ---------------------------------------------------------- Plan hash value: 1323614827 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 4563 | 1581K| 52 (0)| 00:00:01 | | 1 | MERGE JOIN CARTESIAN| | 4563 | 1581K| 52 (0)| 00:00:01 | |* 2 | TABLE ACCESS FULL | T2 | 1 | 113 | 3 (0)| 00:00:01 | | 3 | BUFFER SORT | | 4563 | 1078K| 49 (0)| 00:00:01 | | 4 | TABLE ACCESS FULL | T1 | 4563 | 1078K| 49 (0)| 00:00:01 | ----------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - filter("T2"."USERNAME"='SYS') Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 167 consistent gets 0 physical reads 0 redo size 267325 bytes sent via SQL*Net to client 3868 bytes received via SQL*Net from client 306 SQL*Net roundtrips to/from client 1 sorts (memory) 0 sorts (disk) 4563 rows processed |
这两条语句并不复杂。如果我们忽略性能统计数据,我们很容易就从其语句逻辑结构或者执行计划判断出它们的性能谁优谁劣。
但是为什么第二条语句的 CG 更少呢?
我们对它们作 SQL 运行跟踪,再看格式化的跟踪结果:
| SQL代码 Rows (1st) Rows (avg) Rows (max) Row Source Operation ---------- ---------- ---------- --------------------------------------------------- 4563 4563 4563 MERGE JOIN CARTESIAN (cr=167 pr=0 pw=0 time=38433 us cost=52 size=1619865 card=4563) 1 1 1 TABLE ACCESS FULL T2 (cr=3 pr=0 pw=0 time=78 us cost=3 size=113 card=1) 4563 4563 4563 BUFFER SORT (cr=164 pr=0 pw=0 time=22958 us cost=49 size=1104246 card=4563) 4563 4563 4563 TABLE ACCESS FULL T1 (cr=164 pr=0 pw=0 time=11815 us cost=49 size=1104246 card=4563) |
这是第二条语句的计划统计数据。显然,它包含两个部分:对 T1 和 T2 的全表扫描访问。
在该执行计划当中,T1 的全表扫描的 CG 为 164,当时为什么在第一条语句中对其的全部扫描产生的 CG 为 466 呢?这是因为数据获取数组大小(fetch array size)设置的影响。
如下,在 SQLPlus 当中,该设置默认值为15,如果我们将其设得足够大,CG 将变为165,没错。因为无论该数组大小设为多大,Oracle 总是在第一次读取时读取第一条记录。
| SQL代码 HelloDBA.COM> set arraysize 5000 HelloDBA.COM> set autot trace stat HelloDBA.COM> select * from t1; Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 165 consistent gets 0 physical reads 0 redo size 1147039 bytes sent via SQL*Net to client 524 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 4563 rows processed |
关于全部扫描的 CG 可以参考该文章了解更多细节:http://www.hellodba.com/reader.php?ID=39&lang=EN
F2 是一张小表,它的全表扫描访问产生的CG为3。
写到这是否可以结束了呢?现在将第二条语句的过滤条件移除看看。
| SQL代码 HelloDBA.COM> select * from t1, t2; 246402 rows selected. Statistics ---------------------------------------------------------- 1 recursive calls 0 db block gets 219 consistent gets 0 physical reads 0 redo size 14113903 bytes sent via SQL*Net to client 181209 bytes received via SQL*Net from client 16428 SQL*Net roundtrips to/from client 1 sorts (memory) 0 sorts (disk) 246402 rows processed |
仅仅 219 CG?这是一个笛卡尔乘积的关联(无关联条件),怎么会是如此少的 CG 呢?
再次产生 SQL 跟踪文件:
| SQL代码 Rows (1st) Rows (avg) Rows (max) Row Source Operation ---------- ---------- ---------- --------------------------------------------------- 246402 246402 246402 MERGE JOIN CARTESIAN (cr=219 pr=0 pw=0 time=957833 us cost=2553 size=87472710 card=246402) 54 54 54 TABLE ACCESS FULL T2 (cr=55 pr=0 pw=0 time=728 us cost=3 size=6102 card=54) 246402 246402 246402 BUFFER SORT (cr=164 pr=0 pw=0 time=433549 us cost=2550 size=1104246 card=4563) 4563 4563 4563 TABLE ACCESS FULL T1 (cr=164 pr=0 pw=0 time=10674 us cost=47 size=1104246 card=4563) |
T1 的全表扫描的 CG 并未变化,T2 的 CG 增加为 55。55 意味着什么?它是 T2 的数据记录数加一。
| SQL代码 HelloDBA.COM> select count(*) from t2; COUNT(*) ---------- 54 |
但是,笛卡尔乘积不是意味着 m×n 吗?为什么结果是 m+n?
实际上,Oracle 确实对 T1 做了多次重复访问。不过,第一次访问后,读取到的数据被缓存到了私有工作区,接下来的访问就是从私有内存而非共享内存中读取数据。因此,这些访问就没有被记入 CG 当中。
为了获取实际的访问次数,我们使用嵌套关联提示使其从共享内存中读取数据:
| SQL代码 HelloDBA.COM> select /*+use_nl(t1) leading(t1)*/* from t1, t2; 246402 rows selected. Elapsed: 00:00:07.43 Execution Plan ---------------------------------------------------------- Plan hash value: 787647388 ---------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 246K| 83M| 5006 (1)| 00:01:01 | | 1 | MERGE JOIN CARTESIAN| | 246K| 83M| 5006 (1)| 00:01:01 | | 2 | TABLE ACCESS FULL | T1 | 4563 | 1078K| 49 (0)| 00:00:01 | | 3 | BUFFER SORT | | 54 | 6102 | 4956 (1)| 00:01:00 | | 4 | TABLE ACCESS FULL | T2 | 54 | 6102 | 1 (0)| 00:00:01 | ----------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 4568 consistent gets 0 physical reads 0 redo size 16632868 bytes sent via SQL*Net to client 181209 bytes received via SQL*Net from client 16428 SQL*Net roundtrips to/from client 1 sorts (memory) 0 sorts (disk) 246402 rows processed |
尽管执行计划没有变化,但是 CG 的变化却相当明显。
研究收获
从这个例子中可以注意到两点:
1. 数据获取数组大小会影响 CG;
2. CG 仅包含从共享内存读取的次数;
原文发布时间为:2018-02-28
本文作者:黄玮