转自: 可看到它使用机器学习算法来识别DNS安全问题 http://logz.io/blog/machine-learning-log-analytics/
A Machine Learning Approach to Log Analytics
Opening a Kibana dashboard at any given time reveals a simple and probably overstated truth — there are simply too many logs for a human to process. Sure, you can do it the hard way, debugging issues in production by querying and searching among the millions of log messages in your system.
But this is far from being a methodological and productive method.
Kibana searches, visualizations, and dashboards are very effective ways to analyze a system, but a serious limitation of any log analytics platform, including the ELK Stack, is the fact that the people running them only know what they know. A Kibana search, for example, is limited to the knowledge of the operator who formulated it.
“Alexa/Cortana/Siri, What’s Wrong With My Production Environment?”
Asking a virtual personal assistant for help in debugging a production system may seem like a far fetched idea, but the notion of using a machine learning approach is actually very feasible and practical.
Machine learning algorithms have proven very useful in recent years at solving complex problems in many fields. From computer vision to autonomous cars to spam filters to medical diagnosis, machine learning algorithms are providing solutions to problems and solving issues where once expert humans were required.
Supervised Machine Learning
Among the various approaches to machine learning, supervised machine learning stands out as one of the most powerful tools in the data scientist’s toolbox.
Supervised machine learning is based on the idea of learning by example. The algorithm is fed with data that relates to the problem domain and meta data that attributes a label to the data. For example, the domain-specific data may be an image, essentially a set of pixels, and a label. This label may indicate that the set of pixels forms a car, a pedestrian, or an important traffic landmark. The process of assigning labels to data is referred to as “labeling,” and it plays a crucial part of obtaining good results from supervised machine learning.
Formulating the problem in this fashion enables machine learning algorithms to sift through huge amounts of data, making the necessary correlations and deducing the interdependencies between the data points.
Dealing with terabytes of log data, we at Logz.io pose this classification question: “Is this log interesting?”
An Ill-Posed Question
The question of log relevancy is not a trivial one. A log entry may prove very useful to one user and completely irrelevant to another. Moreover, in the process of data labeling, interesting logs may not get labeled correctly or at all because they were lost in the clutter.
To tackle the problem of data labeling, we at Logz.io are using the below methodologies:
-
Use implicit and explicit user behavior. We pay attention to the ways that our clients interact with our tools. Creating an alert, viewing a log, creating dashboards and other actions are all actions during which our users indicate what is important to them.
-
Inter-user similarities. All of our clients are unique, and we cherish every one of them. Our moms’ reassurances notwithstanding, we are also all very similar and use the same components and, therefore, share similar log entries. Consequently, similar users may draw benefits from common labeling.
-
Harvest public resources such as CQA (community questions and answers) sites and others. Sites such as Stack Overflow, GitHub, and even Wikipedia contain wealths of information and host a vast pools of knowledge that can be used to evaluate the importance of logs and even propose solutions to the root problems that are indicated by these logs.
Combining data from these resources enables us at Logz.io to create a very rich dataset of labeled logs, together with meta data on the log relevance, frequency and, in some cases, information that shows how to solve the underlying issue.
Training Your Classifier
Once the necessary data — log entries and corresponding labels — has been accumulated, it is possible to construct a log classifier.
Classification can be performed in many ways, and one such method is Linear Support Vector Machines (SVM). This type of classifier offers simple training and is easy to interpret by domain experts.
More information on SVM and its application to text classification can be found here:
- http://www.cs.cornell.edu/people/tj/publications/joachims_98a.pdf
- http://nlp.stanford.edu/IR-book/html/htmledition/support-vector-machines-and-machine-learning-on-documents-1.html
For this example, a feature vector needs to be constructed. Using short n-grams usually yields a feature space of a dimension of about 1M dimensions, which is feasible and rich enough to give good results.
Examples of such n-grams and corresponding weight coefficients are presented below. As can be seen, it is very easy to interpret the results and verify them for sanity. Positive values indicate some sort of system failure, whereas negative values indicate a log entry that does not contain an actionable, relevant, state.
unable: 0.671539714688
topic: 0.678756599452
error: 0.788508324168
connected: -0.157199772246
to provider: -0.15319903564
connected successfully: -0.15319903564
Another possibility for training a classifier is to use Random Forests, which are very useful in cases where the features are categorical (non-numerical) and do not fit linear models very well. More information about using Random Forests for classification can be found here:
While seemingly trivial, this process is very powerful. It may not take a rocket scientist to tell you that “error” is a phrase that may indicate a production issue, but it is virtually impossible for even the best DevOps group in existence to find the correlations and relations between a million phrases that occur in log data. The process of feeding these vast amounts of data to supervised ML algorithms enables the machine to learn from the accumulated knowledge of hundreds of DevOps teams and hundreds of thousands of contributors to knowledge sites.
At Logz.io, we use a set of machine learning algorithms that are able to collect bits and pieces of data — mostly on what users care about in their log data — and fuse all of them together into a supervised process that trains our machine learning code. One of the most powerful parts of the Logz.io learning system is that it learns from the way in which users react to these highlighted events, enabling ongoing supervision and continuous learning.
Integration
Once the classifier was trained, it was integrated into the Logz.io pipeline. We used tools including Spark and Hadoop to run the classifier and machine learning at the scale that was required. The logs that pass the entire classification stage are labeled as “Cognitive Insights” and additional information that has been gathered in the labeling stage is attached to them. This enables Logz.io not only to highlight relevant logs to our customers but also to enrich the logs with additional information.
A Classification Example
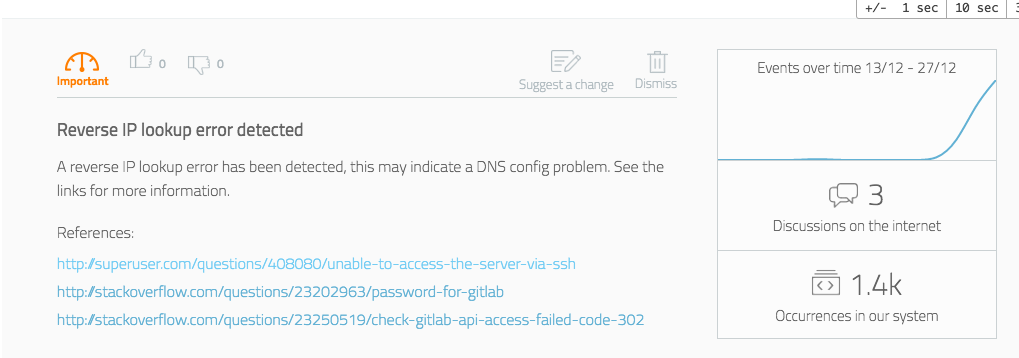
Obviously, the Logz.io learning technology is much more complicated and includes a multi-vector analysis, but we thought to share a simplified example. The following log was analyzed in our system (note that specific values have been obfuscated):
|
1
|
“
Address <strong>IP_OCTET</strong> maps to <strong>URL</strong>, but this does not map back to the address - POSSIBLE BREAK-IN ATTEMPT!”
|
The log level for this log was not high, it did not contain any of the usual, trivial, error phrases (“error”, ”fatal”, “exception”, etc’), but it was classified as interesting.
The log was then passed through the augmentation module, and several relevant threads on knowledge sites were found:
- http://superuser.com/questions/408080/unable-to-access-the-server-via-ssh
- http://stackoverflow.com/questions/23202963/password-for-gitlab
- http://stackoverflow.com/questions/23250519/check-gitlab-api-access-failed-code-302
These online resources indicate that contrary to the log text, it is more likely to be a DNS issue than an actual security threat.
The system then displays the log and the data to the user in an informative way:
Summary
Utilizing a machine learning approach to log analytics is a very promising way to make life easier for DevOps engineers. Classifying relevant and important logs using supervised machine learning is just the first step to harnessing the power of the crowd and Big Data in log analytics. Adaptive log clustering, log recommendation, and some other cool features are coming soon, so stay tuned!
Logz.io is an AI-powered log analysis platform that offers the open source ELK Stack as a cloud service with machine learning technology. Learn more about ourCognitive Insights technology or create a free demo account to test drive the entire platform for yourself.
本文转自张昺华-sky博客园博客,原文链接:http://www.cnblogs.com/bonelee/p/6349538.html,如需转载请自行联系原作者
