昨天在python给你的圣诞帽上意犹未尽的动手党(点击查看相关文章),今天的话题依然和圣诞节有关。
前几天,文摘菌发现了一个Kaggle上的圣诞歌曲数据礼包。这里有你能想到所有的圣诞歌曲,总计超过5万首。而Kaggle上的数据科学家用各种方式要把它们玩儿坏了,一起看看有哪些有趣的结论!
又是圣诞节,有没有被大街小巷的圣诞歌曲洗耳朵?有没有想过这些圣诞歌曲到底有什么魔力?他们的歌词又有什么共同点?
我们把所有跟圣诞有关的歌曲都打包起来,总计超过5万首歌曲。在这篇文章里,文摘菌将首先用朴素贝叶斯对这些歌曲文本进行全面分析,来快速识别出,到底什么样的歌曲才能被成为真正意义上的圣诞歌曲。
之后,我们还可以一起看看,kaggle上的数据科学家用这个数据包分析出了的这些有趣的结论:
与圣诞关系最密切的歌词TOP20;圣诞歌产量最高的歌手TOP20;
圣诞歌词中,什么样的双音节词最受欢迎?

这个数据集取自55000多段歌词,同时涵盖了超过55000首歌曲。你能想到的全都有,包括Jinglebell :)如下:这是一个有55000多行和4列的数据框:
- 艺术家
- 歌曲
- 链接
- 文本
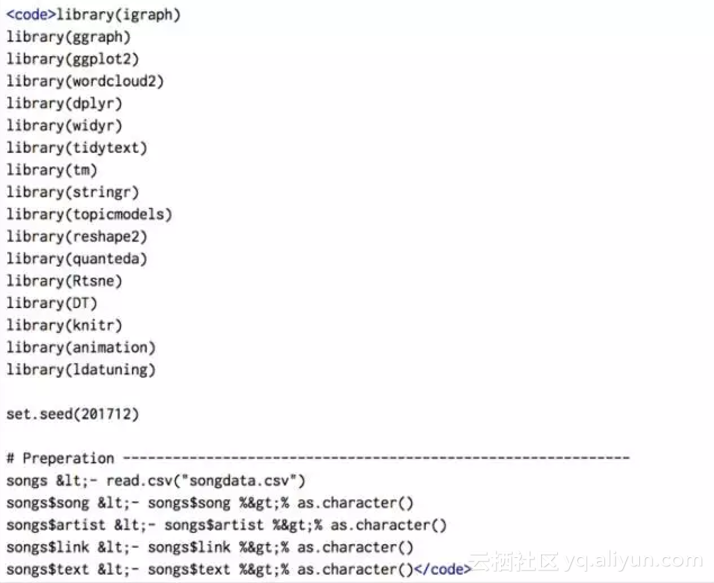
我们的目标是对歌曲文本进行全面分析,帮助我们快速识别出圣诞歌曲。为此,我们首先在数据框中添加一个额外的列,给每首歌曲一个“圣诞”或“非圣诞”的标签,也就是歌词中包含“Christmas”,“Xmas”或“X-mas”的歌曲将被标记为“圣诞”,不包含的则标成“非圣诞”。
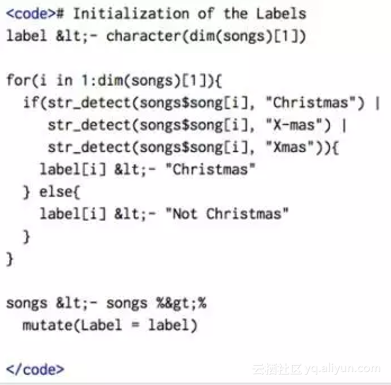
这还只是标签的初始化,我们之后会将朴素贝叶斯应用于一组训练集以识别其他圣诞歌曲。但现在,我们将通过一些直观的描述性方法来探索数据集。看看会得到一些什么有趣的结果。

探索初始的圣诞歌曲
清理 & 标记化
首先我们从数据清理和标记化开始~随后,圣诞歌曲将被选中并被保存为一个变量。

相关性分析
现在我们可以从不同的角度由相关性来分析原始的圣诞歌曲。接下来,我们运用networkD3 html widget将相关性可视化:具有相同总连接数的节点将被赋予相同的颜色,而边的颜色意味着由两个节点共享的公共邻居的数量。而且,一个节点的大小表明它的中心性,中心性由中间性(即通过它的最短路径的数量)定义。在两个节点之间的距离是1的最小最大变换减去相关度,这是有意义的,因为直观来说,相关性越高,两个节点应该越近。而且,距离越短,边缘越宽。
请注意,相关性永远要基于歌词才行
单词之间的相关性
出现超过100次的单词与至少另一个相关度大于0.55的单词相关。

歌曲之间的相关性
一首歌曲与其他至少3首相关的歌曲之间的相关性大于0.75-通过这个方法,我们可以检测到类似或被略微修改的歌曲。

特定的词之间的相关性

艺术家之间的相关性

词云
原始圣诞歌曲的词云

朴素贝叶斯
朴素贝叶斯是一种流行的监督机器学习算法,它能处理具有大量特征的分类问题。它是基于一个类,这个类的特征是被假定独立分布的,所以从这种意义上说,它是“朴素”的。在我们的例子中,我们想知道,给定一组特征之后,即文档中单词的tf-idf,一首歌曲是否应该被朴素贝叶斯分类为圣诞歌曲。
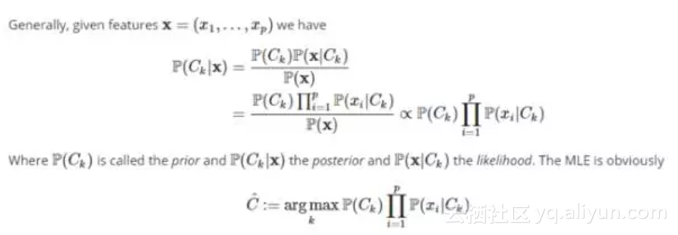
构造最大似然估计的难点是先验分布的选择,即类的概率分布。通常假定它是按类频率均匀分布或估计的。在我们的例子中,我们使用了先验分布的多项式分布和均匀分布,这意味着我们在没有进一步信息的情况下对歌曲的分类是没有偏见。
识别隐藏的圣诞歌曲

我们识别出2965首隐藏的圣诞歌曲,在最初的500首圣诞歌曲中,有2首歌曲被朴素贝叶斯拒绝认定为圣诞歌曲。
探索隐藏的圣诞歌曲

因此我们已经成功地识别出一些宗教圣诞歌曲,它们的标题通常不包含“Christmas”或“X-mas”单词。
潜在狄利克雷分布&t统计随机邻域嵌入
数据准备
只有包括隐藏在内的圣诞歌曲的前300项特征,将被用来计算Rtsne和LDA,否则存储空间会不足。

LDA
LDA是潜在狄利克雷分布,2003年在Blei, Ng, Jordan的论文中被提出。这是一个生成语料库的概率模型,其中的文档被表示为关于潜在主题的随机混合物,一个单独的文档通常只有几个主题,被分配了不可忽视的概率。此外,每个主题的特点是单词的分布,通常只有一小部分词被大概率分配给某个主题。变分期望最大化算法或吉布斯抽样用于参数的统计推断。
LDA需要固定数量的主题,也就是说,在应用该算法之前,应该先知道主题的数目。然而,有可能通过不同的性能度量来确定主题的最佳数量,比如Nikita,用ldatuning包。
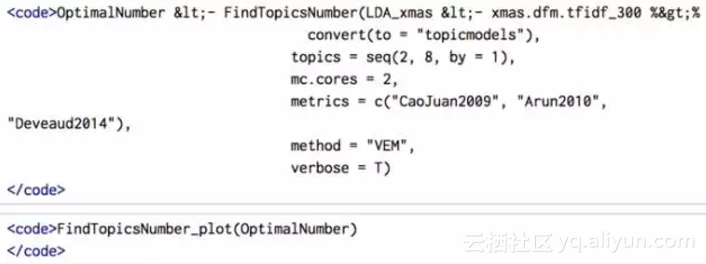
因此,我们将选择8作为主题的最佳数量。

我们可以使用tidytext包 来检查每个文档的主题分布,即对于每个文档,它属于从1到8某个主题的概率的总和等于1。
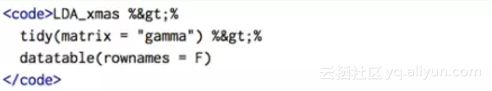
同样,我们也可以获得每个主题词的概率分布,即每个主题产生不同的单词的概率总和等于1。

每个主题的关键词是:

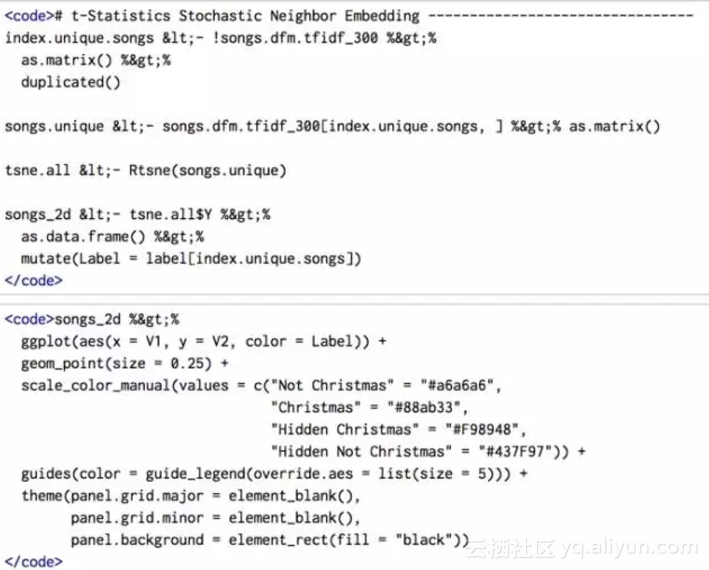
t-SNE
由van der Maaten和Hinton于2008年开发,t-SNE代表统计随机邻域嵌入,这是一种降维技术,用公式表示出捕获的原始数据点的局部聚类结构。它是非线性的和不确定性的。
下面的计算大约需要30分钟。
如果我们重复以上过程在不只一次迭代上呢?
到目前为止,我们只运行了一次迭代的朴素贝叶斯。然而,我们可以为多个迭代重复这个过程,即训练一个朴素贝叶斯分类器并重新标记所有的假阳性为隐藏圣诞/圣诞,所有的假阴性为隐藏非圣诞/非圣诞,一遍遍重复进行。
首先,我们再次准备数据以避免错误。

运行10次迭代。

然后,精度和f1得分开始时单调增长,然后收敛到大约0.95的值,这意味着没有遗留很多待检测的“隐藏圣诞歌曲”和“隐藏非圣诞歌曲”。然而,在这个过程中,我们始终相信朴素贝叶斯分类器是100%准确的,这实际上几乎是不可能的。因此,在每一次迭代中,有一些歌曲被朴素贝叶斯错误地分类为“圣诞节”,在训练集的下一个迭代中用于训练朴素贝叶斯分类器。有了这个不断累积的错误,我们可能会担心,随着迭代次数的增加,结果实际上会更糟。

最后,我们大约有一半的歌曲被归类为“圣诞节”,而另一半为“不是圣诞节”,这似乎是非常不可信的。这倒是引出了一个问题:是否存在一个最佳的迭代次数?我们不能简单地手动控制这57650首歌是否被正确分类。所以这仍然是一个有待回答的开放式问题!
还有哪些有趣的结论
之后,我们用这些数据,还分析出了以下这些有趣的结论,基于篇幅的原因,我们直接贴出kaggle上的一些有趣结论,不再在微信推文中po出实现代码,想亲手尝试的同学,请拉到文末查看kaggle上的代码和数据传送门~
原文发布时间为:2017-12-25
本文作者:文摘菌