
摘要:在2017杭州云栖大会机器学习平台PAI专场上,阿里巴巴高级算法专家杨军结合具体案例分享了端到端GPU性能优化在深度学习场景下的应用实践。
本文内容根据嘉宾演讲视频以及PPT整理而成。
目前深度学习和GPU已经成为了人工智能的基础,一软一硬的结合能够帮助我们实现图像识别、语音识别以及视频的处理,那么如何优化深度学习框架与GPU资源也是机器学习平台的一个研究方向。
本次分享主要分为以下5个部分:
1. 背景介绍
2. 优化思考
3. 案例1
4. 案例2
5. 总结
一、背景介绍
下图中左侧是深度神经网络的发展历史,这张图来自邓力的Slide。可以看到深度学习不是非常新鲜的事物,深度学习大概在1980年被提出,当时也被寄予了很高的期望,那个时候大家希望使用两层的神经网络拟合任何一个复杂的函数,但是由于当时的数据和计算能力的限制,逐渐发现虽然想法非常美好,但是并不能实现实际的目的,所以随着SVM这样的方法的兴起,神经网络也进入了低潮期。大概在2009年,Hinton的学生在谷歌把深度学习带入改进了第一版的Voice Search系统,然后发现效果非常不错,从此深度学习又一次进入人们的视野。在2012年左右,在一次Image比赛中,Alex Krizhevsky设计了一个非常强大的模型,一举打败了近十年的模型的改善结果,于是神经网络也开始一马平川获得人们的关注。
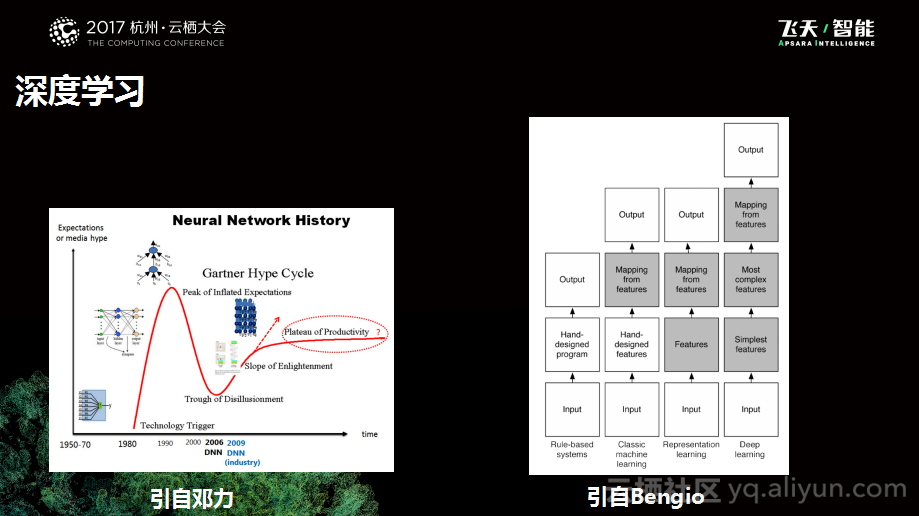
上图中右侧是一个对比图,这张图来自Bengio的一本教科书。其实,深度学习本质上也是一个机器学习的方法,和其他的机器学习没有本质上的区别,都是需要学习X和Y的映射关系,只不过中间怎样获得映射的讲究不一样。对于普通的机器学习方法而言,会有一个人工特征设计的过程,人们会在数据的基础上做一些特征抽取以及变换处理,这可能是我们耳熟能详的方法。而在深度学习框架中,则会将人工的负担从特征设计上推到模型设计的层面,也就是将一些更加精细化的工作从由人工完成变成由机器实现,希望能够解放人工的负担,并获得更好的普适性。
当然,这也提出了相应的要求,因为存在一个基本的常识:当一个工作需要机器工作5天的话,通常会存在一定的冗余和过度开销。这也是为什么深度学习需要更高的计算能力以及更多数据的原因,这也是为什么到了这几年随着IoT的兴起,随着GPU的兴起,人们发现深度学习可以更好地解决实际的问题的原因。
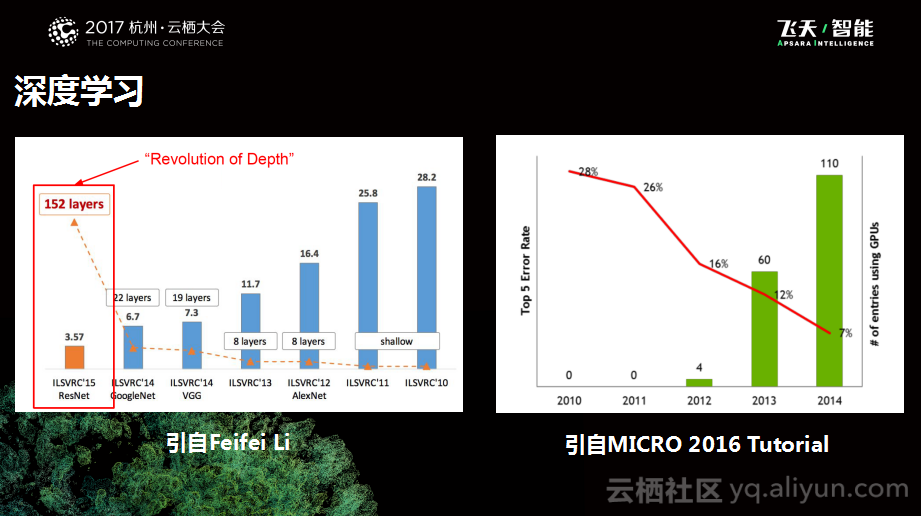
下图中左侧是深度学习在Image大赛里面的趋势图,右侧比较好玩,它是MICRO 2016 的Tutorial图。MICRO属于计算机体系结构领域的顶会了,其实近两年出现了一个趋势,就是像深度学习作为算法的应用,它会和计算机体系结构等出现更多的交互。这张图左边显示的是Error Rate的情况,从图中可以看到从2010年到2014年, Error Rate有一个明显的下降趋势。右边这一列表示的是GPU的采用率,在图中可以发现2011年的时候还是0个任务采用了GPU,而当到了2014年就有110个任务使用了GPU,这是非常明显的变化。当然这里面也存在一个问题,就是为什么会选择使用GPU解决问题,这一定是存在某些原因导致了深度学习和GPU更匹配一些,所以才会导致这样的情况。
下图也是深度学习经典教科书中的一张图,图中的X轴是OP类型,也就是说神经网络本质上是由一个个小的操作函数构成的。Y轴表示一些比较流行的模型,可以看到不同的模型在不同OP里面计算耗时的分布是不同的,比如对于AlexNet而言,主要耗时在卷积这个地方,但是其他的模型可能在其他的操作里面耗时比较多。这就给了我们很多信息,包括卷积、矩阵乘法以及加法等的特性都是与GPU高度契合的。

下图是CPU和GPU的对比图。CPU的设计图在左边,其设计比较有意思,下面是一些访存的体系,上面和中间这一大部分是Cache的逻辑,左上角是一个控制逻辑。因为如果大家对于计算机体系结构比较了解就会知道CPU中往往会有一些非常复杂的分支预测和流水线这样的逻辑,希望能够以此来提升单核的计算吞吐率,而因为这样使得计算相关的资源在整个芯片里面所占的面积是比较低的。而图中右边是典型的GPU的示意图,可以看到其中有大量的计算核,只有很少的一些控制逻辑以及Cache逻辑,这也就是为什么GPU更加适合于做一些并行计算的本质原因,也就是因为GPU通过削减自己的target domain来获得预期的收益。

接下来为大家简单介绍一些深度学习在阿里巴巴中的实际应用。因为阿里巴巴PAI的深度学习团队本身更加关注于底层的优化,所以也更加关心寻找一些场景来驱动优化的边界。

上图中第一个是机器翻译的场景,这个是应用在钉钉中的应用,其背后支持的是神经网络翻译的模型,在图中上面是中文,下面是对应翻译的英文。中间这幅图是阿里PAI团队和蚂蚁金服合作的信用建模,目前大家所使用的芝麻信用分背后的模型就是由它赋能的。最右边就是OCR场景下的做的模型训练以及模型量化预测等优化工作。
äºã 优化思考
为什么要进行优化呢?首先,优化需要解决一些实际的问题,当遇到某些挑战时需要进行优化。以下就罗列出了一些应用深度学习时遇到的挑战:
计算量。随着我们把更多的工作从人工转向机器的时候,会发现机器能够做很多事情,但是同时也会存在一些冗余,所以希望这些人工的事情被更加具有效率的硬件所代替。但是硬件却会存在一定的极限,这个硬件的极限就需要靠人来弥补。
显存。运行过GPU任务的同学会有印象,GPU的显存属于受限的资源,当任务超过显存限制就会出现out of memory的情况,这就会让建模的同学非常头痛。
多设备支持。因为我们往往希望当模型训练好之后,能够在各种适配机器上运行。这两年也有一个趋势,就是深度学习除了在离线训练以外,在线场景中也有很多的应用了。所以模型的多个设备支持也是一个非常有意思的课题。最近两年也有很多方案来解决这个问题,包括Google的XLA等。
模型可操控性。这是一个比较小众,但是在最近半年内广受大家关注的问题。其基本的原则就是现在已经有很多工具来做深度学习的建模了,包括TensorFlow、Caffe等工具,但是还是会存在一个问题,用户所描述的模型和底层实现之间还是存在Gap的,而这个Gap导致模型的性能、效果不是特别易用。所以这个层面的问题其实是语言设计的问题,需要设计一个更好的领域语言驱动用户建模更加高效。
可解释性。这是一个对于工业界比较有用的问题,因为机器学习相比于原来的确定性算法会引入一定的随机因素,而深度学习由于本身的特点会引入更多的黑盒因素,所以我们希望在一些更加严格的场景下能够对于模型的工作原理进行解释,这样才能够更加有信心地将模型部署在更加严格的场景中去。在这一点上,最近两年也有一些学术界和工业界的研究在推进。
三、案例1
模型结构
第一个分享的案例是一个比较经典的案例,这里面糅合了很多的内容,包括分布式优化、显存优化、图优化以及计算优化等。下图是阿里巴巴机器翻译团队的Slide中的一个场景,如图所示的是一个典型的翻译结构图。这个结构图并不是非常复杂,大概输入层是Embedding层,中间加了Encoder层、Attention层和Decoder层,最后还有一个Beam Search层进行结果的预测输出。

这个模型给翻译团队带来了一些困扰,导致需要和深度学习团队合作做一些事情。首先的问题是训练时间很长,单卡训练耗时长达20天以上,基本上用户不可迭代。第二个问题就是模型结构非常复杂导致会出现显存用尽的情况,比如现在的model是两个Encoder层,如果换成四个Encoder层,显存就爆掉了,或者多加上一层Attention层,显存也会爆掉,正是因为这样的困扰,导致机器翻译团队不得不做一些妥协。此外,在线Inference延时很大,上线前相较Shallow模型延时达到了10倍,而这个延时是不能忍受的。
分布式优化
所以阿里巴巴深度学习团队围绕着上述三个方向做了一系列优化的工作。第一个就是分布式优化的工作,其思路比较直接是Model Average的思想,朴素而言,就是会将计算工作分配到不同的Worker里面去,每个Worker都会做完自己的工作负载,之后会进行Average汇总并push到中心存储里面去再拿回模型的参数。而这里面就存在一个小问题,虽然这样来做可以把硬件的资源打的更满一些,因为本质上而言减少了通讯的开销,但是相对而言也会对于模型的精度存在一定影响。所以为了配合这个策略,我们增加了一个Learning rate auto-tuning机制,通过这个机制可以动态地调整Learning Rate来更好地使用Model Average的情况。此外,为了更好地适应这一优化,我们增加了BMUF机制,BMUF这个算法本质上是为了当Worker数量增加的时候能够弥补对于模型精度所带来的影响。
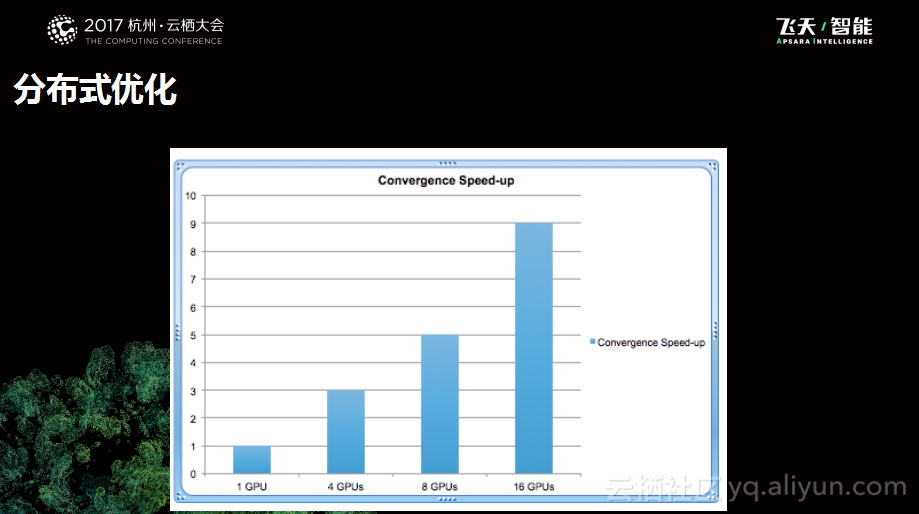
当进行分布式优化之后可以看到如下图所示的统计数据。当单个GPU时,收敛加速比是1,当4个GPU时的收敛加速比是3,16个GPU时收敛加速比则达到了9。
显存优化
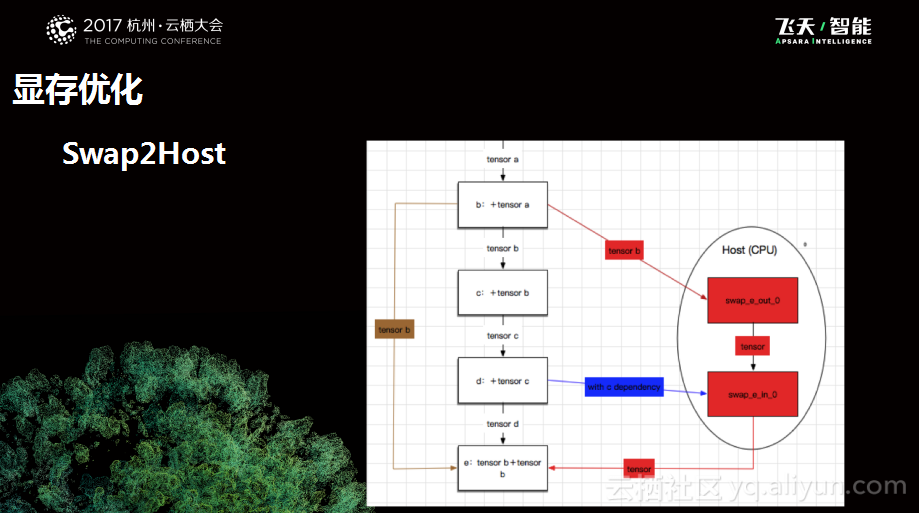
显存优化其实是一个比较好玩的工作。因为业务方在训练比较复杂的模型的时候总是会发现自己的模型在显存中放不下,这就导致业务方不得不将自己的模型变得更小。所以就思考能否利用一些技术的方法来弥补用户的建模需求和硬件显存之间的矛盾。我们将这个工作称之为Swap2Host,之所以叫这个名字是因为其本质上利用了CPU里面更大的内存,将一部分计算的内容放过去。下图是一个小示意图,白色的这个图是用户使用的原始计算图,带颜色的则是优化后的计算图,本质上是做切换的一些tensor和变量,把他们换到CPU里面去,等到需要的时候再换回来,通过这样一个换入换出的工作减少显存峰值的开销。这里就会涉及到几个问题,第一个就是什么时候换出去,其次就是什么时候换进来,都是有很精细的设计需要考量的。
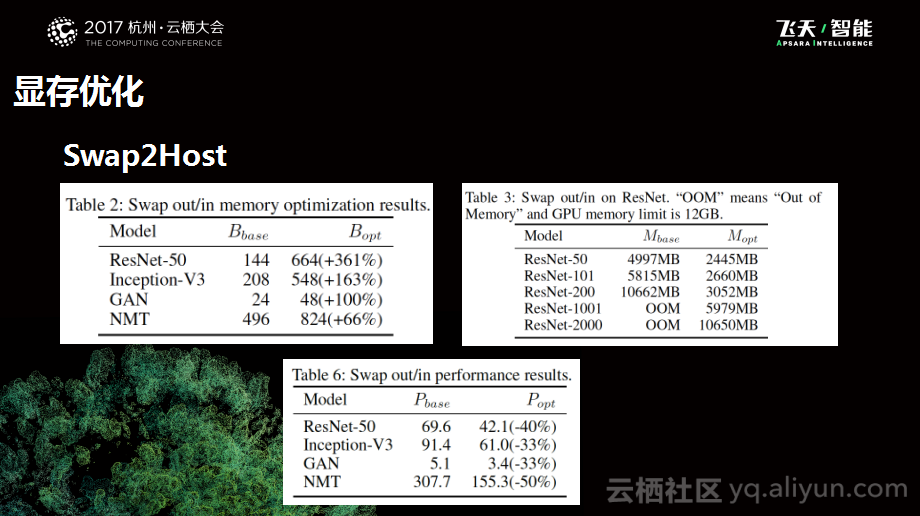
下图是一些统计数据,上面两个表格是显存优化的效果,下面的表格则是性能影响的结果。显存优化中存在两个尺度,一个是优化之后在模型不变的情况下,一个是在模型会变化但是基本结构不变的情况。下面的表则是优化之后对于性能的影响,各个计算模型可能会有少量的计算性能的损失,这一部分还在持续优化。
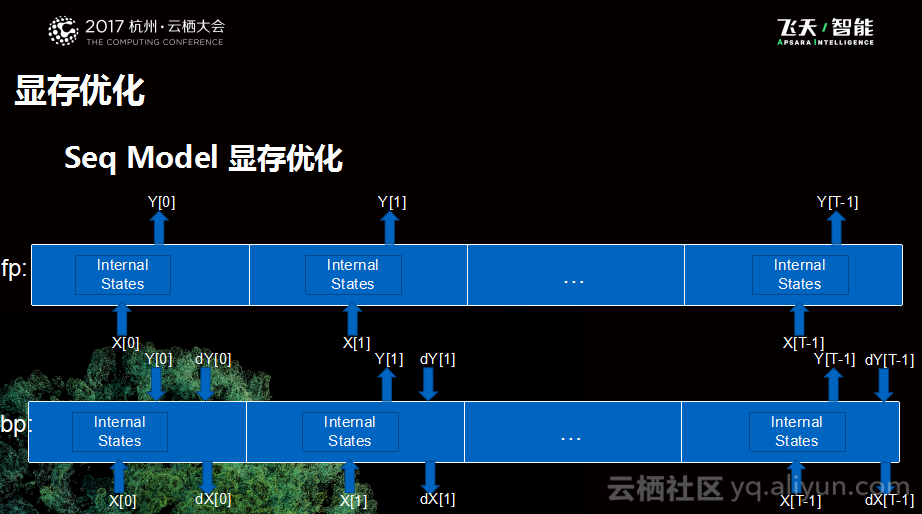
之前所提到的都是对于所有模型都有效的优化,但是效果并不是完全理想,并没有达到最好的预期。为了实现更好的优化,我们还针对于Seq Model本身进行了相应的优化。提到Seq Model,首先需要分享一下其基本的计算逻辑,Seq Mode将计算逻辑进行了拆分,分为前向和后向,前向用于Inference,后向则是训练会用到的逻辑。本质上来说,Seq Model会有很多个Step构成,每个Step会有一个输入和一个输出,后向类似。但是仔细思考中间的这些结果是否一定需要,是不是可以在做完前向之后丢弃掉,当后向需要用到的时候再重新进行计算,这就是针对于Seq Model优化的朴素原理。
下图是优化后的结果,可以看到在模型不变的情况下,显存性能有一个显著的提升。

当完成以上优化之后,我们认为还存在优化的空间,所以继续深挖细节问题。后来发现Attention机制本身会有一个比较好的特性,可以更好地捕捉一些用户的上下文,这对于建模很友好,但是这个特性对于显存开销是比较庞大的,因为其本质上每一个Attention的计算都会需要Encoder Step的所有输出和Decoder Step的一个输出来为每个Decoder的输入做准备,这样就是N方的复杂度,N为Step的数量。所以就考虑将Attention的Operator进行优化,下图所示的就是优化的大致思路,左边是优化前的图,计算出中间结果输出一个Attention Score,后向将中间结果送过去,这时候就会想能够将中间砍掉,不要中间结果,当后向需要就重新进行计算。而后向计算本质上只需要做一个加法,这是非常轻量的,所以想要获得好的收益只需要非常少的开销。而且经过实际测试发现,因为减少了显存的访问,实际上计算反而变得更快了,这也是一个意料之外的收益。
下图是做完Attention优化之后的最终数据,从表格中可以看到随着模型的Time Step增加,出现了显著的优化效果。

图优化
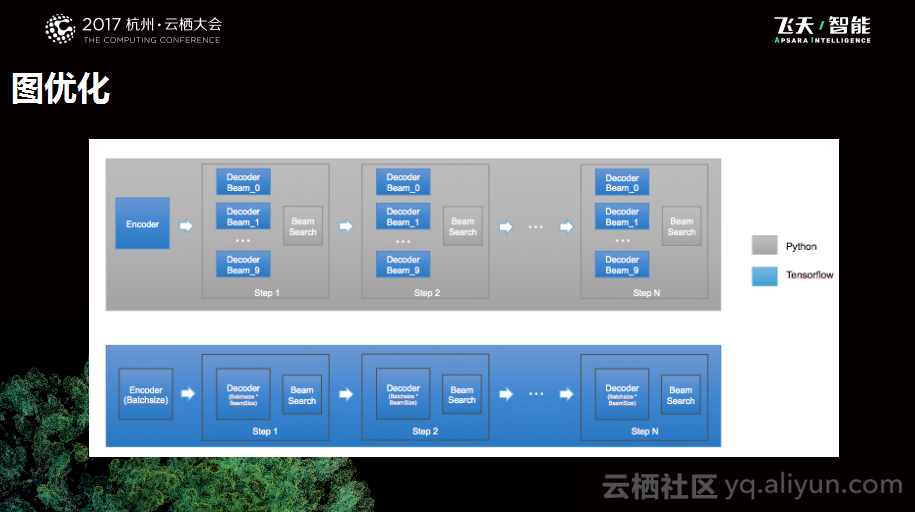
下图是与Inference相关的优化,这是个比较通用的图优化工作。图中下侧是一个用户自己描述的TensorFlow的计算图,因为翻译逻辑比较复杂,所以会需要遍历很多的子图,每一个Step都需要遍历子图,搜索出结果之后再进行下一个Step,一直到最后N个Step。这样就会出现问题了,每个子图都会有一些访存、中间结果的保存等的开销问题,所以我们做了图转化器,这样就减少了中间的开销,获得了性能收益。
计算优化
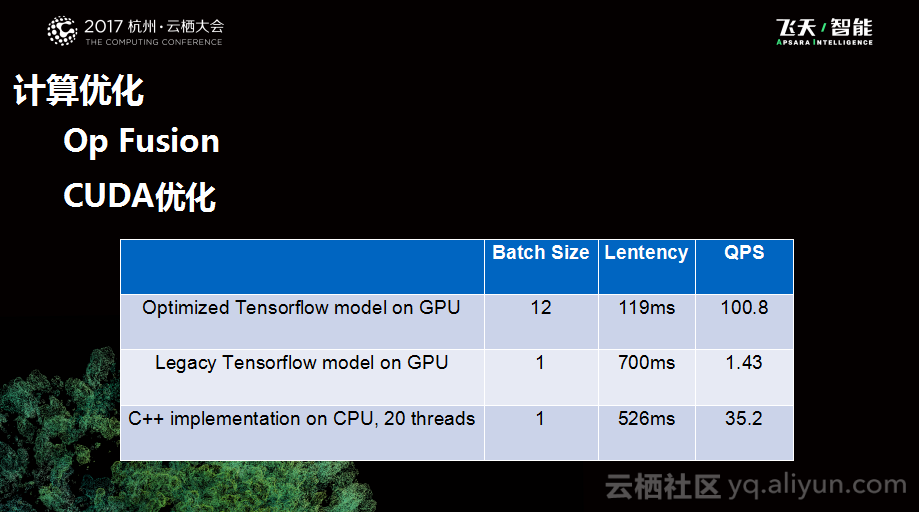
与此同时,我们也做了一些Op Fusion的优化,通过把一些Softmax OP进行融合替换成一个大的OP,并实现了一些定制的扩大优化。下图展示了测试数据,可以看到在优化前用户自己写的模型运行在GPU上面Batch Size大概为1,延迟大概700毫秒,QPS只有1,在优化之后,延迟缩短到了119毫秒,QPS达到100,所以在性能上是极大的提升,目前阿里巴巴也在部署相应的工作。
四、案例 2
与第一个案例的全面优化不同,第二个案例更偏向于模型的优化,其主要是在算法层面做了模型的压缩以及模型结构的优化。而这个案例主要是与OCR项目合作的实施的。
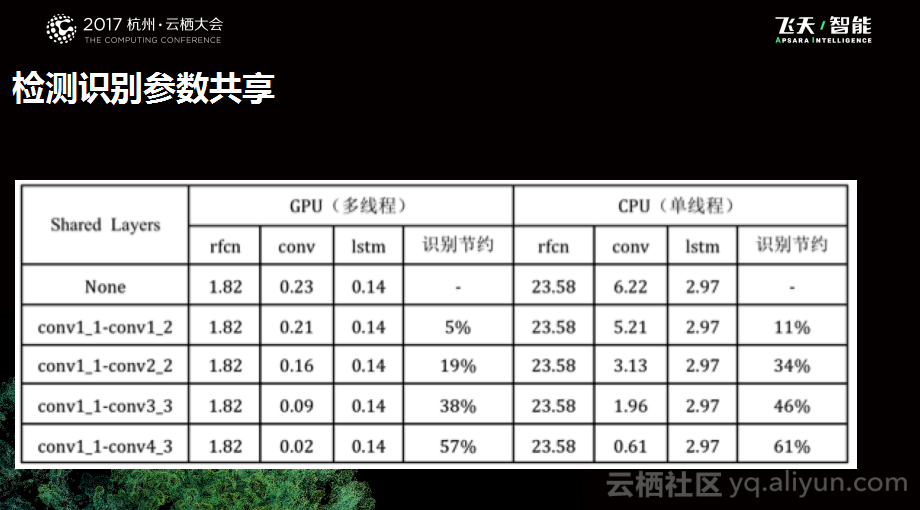
检测识别参数共享
第一个是模型结构的尝试,做OCR的识别需要两个工作,一个工作是检测,另外一个工作是识别。这两个工作都会涉及到特征提取的过程,这时候就在思考,是否能够通过一次的特征提取满足两次不同的需求,于是就做了检测识别参数共享的工作。这个工作主要需要满足三个要求,第一个就是保证精度不要下降,第二就是计算量足够显著,第三个就是调整足够泛化的,因为我们不希望更换模型之后就变得无法适用。
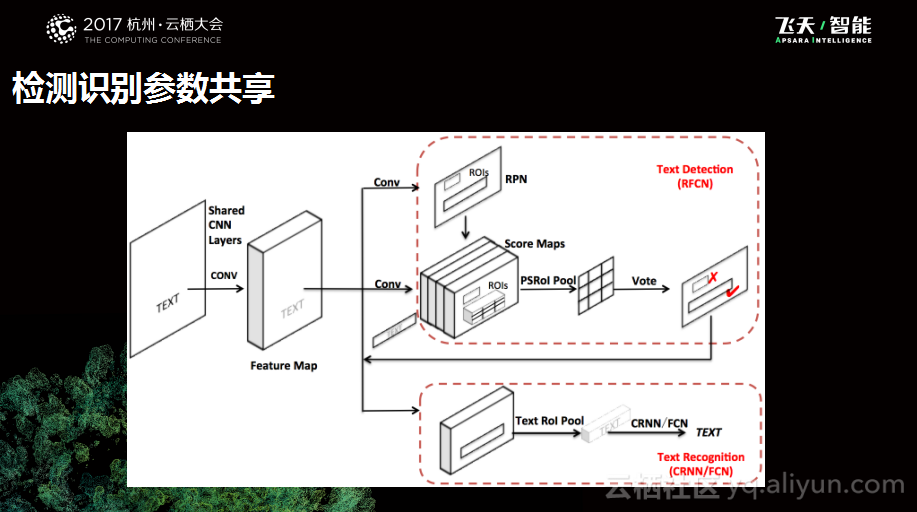
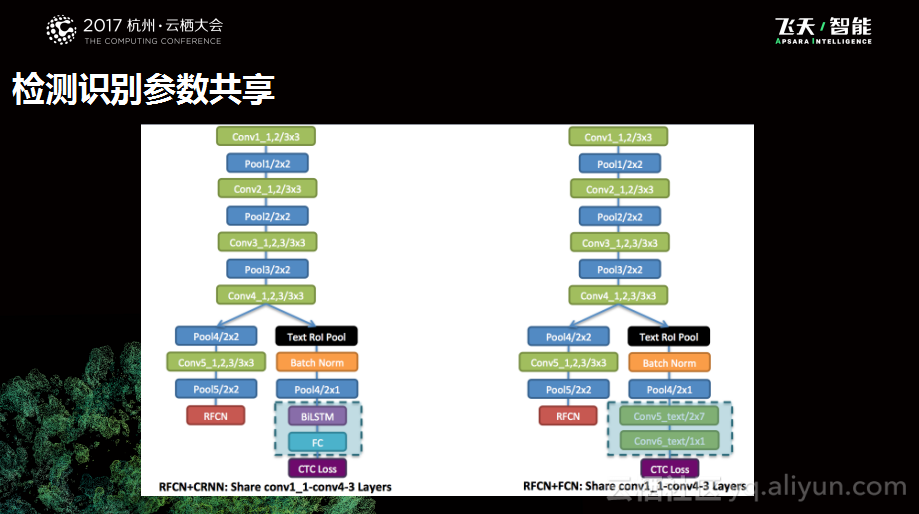
下图是深度学习团队所做的一些实验,左边是RFCN检测模型+CNN识别模型,右边是一个RFCN检测模型+FCN的识别模型,其实除此之外,还有很多组合方式,我们希望通过不同组合的验证优化方法是是普适的。
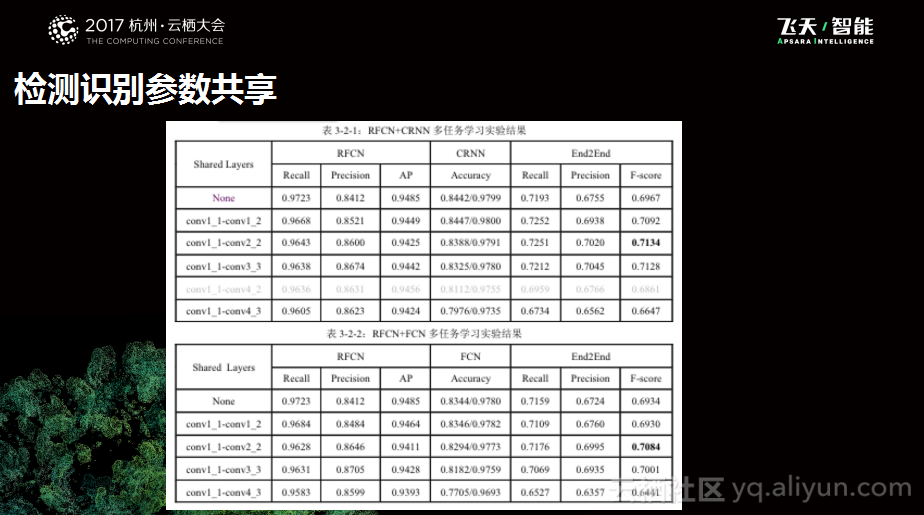
下图是一个统计数据,从数据中可以看出,检测识别参数共享方案基本上达到了所期望的结果。
除了精度之外,我们也关注性能节约情况,所以也做了一组对比实验,实验结果如下图所示。可以看到随着设置的layer不同,性能节约的量也不一样,大概从38%到46%。
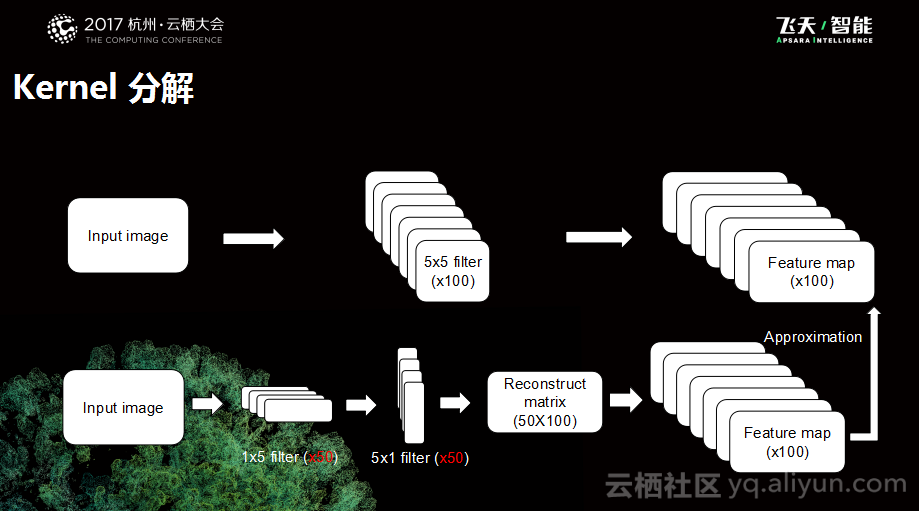
Kernel 分解
在OCR案例中,所做的第二个工作是矩阵分解的工作,会对于卷积和进行拆分。因为本质上神经网络会有一些冗余在里面,所以可以对其做一些相应的降维处理,在精度有限的情况下能够获得显著的计算量的提升。下图是一个原始的模型示意图,这是一个5*5*1000的卷积和,我们对于其进行了拆分,拆成两个低维的卷积核外加一个重建的矩阵再还原回去,这样拆分之后的计算量远远小于之前的情况,所以就能够获得相应计算量的提升。
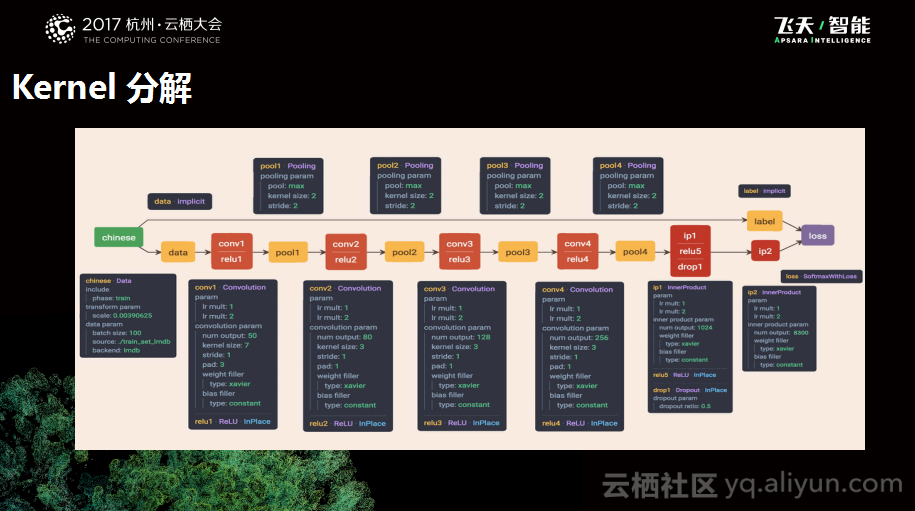
下图是基于单个OCR进行试验的模型,这个模型不是特别复杂,大概是四个卷积核、一个全连接层加一个输出层。
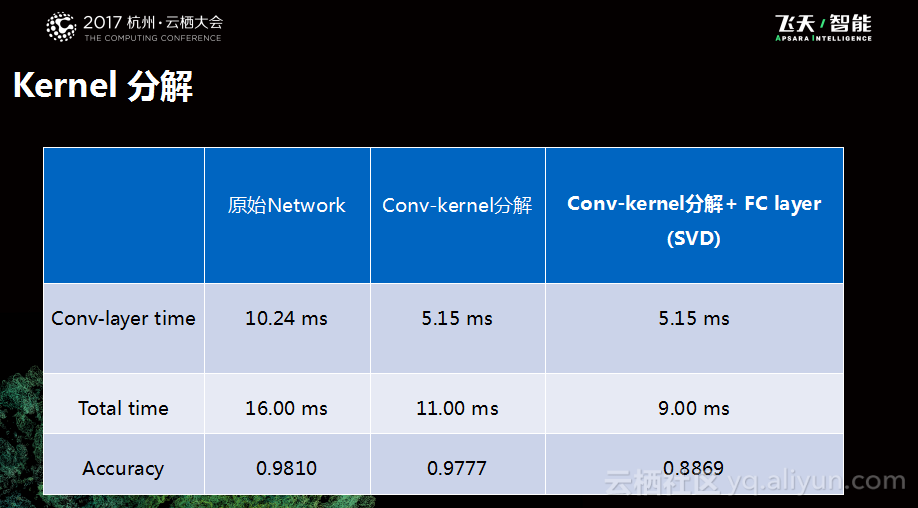
同样,我们也做了不同的实验来验证效果,分别是针对卷基层进行分解和针对全连接层进行分解,只不过分解的策略则会有一些小的区别。第一层只prune了filter number,而后三层同时做了filter pruning和低秩矩阵分解,相比而言更加激进一些。

下图是测试实验所得到的实验结果,我们能够看到如果只去分解卷积核,能够看到卷积时间能够省去一倍的样子,而精度下降很有限。如果FC层也进行分解,精度下降则会明显一些,因为FC层距离输出更近一些,冗余更少一些,这就是当时的情况。最近,我们也在推进卷积核自动化拆解等任务的开展。
五、总结

简单总结一下,可以将GPU性能优化分成以下四个面向:
面向Performance,这包括了计算性能、显存性能以及离线性能和在线性能等,这个维度的工作会包括不同的角度,比如可以从System角度来做,也可以从算法角度来做,可以进行矩阵优化、显存优化以及OP优化等等,而算法优化则可以做检测识别共享,Kernel分解、优化模型等等。也可以从另外的角度来拆分、比如OP的Library优化,可以写更有效的ops以及把这个问题变成编程语言设计的问题,甚至可以做RunTime优化。
面向Productivity,因为我们认为深度学习是一种建模语言,它为我们提供了一种描述问题的手段,所以我们希望这个手段越高效越好,希望用户可以很容易地写出自己的模型,而不用关心底层的细节,就可以成功运行。
面向Portability,也就是怎样做到写一份模型在不同设备中能够高效运行,这个里面主要涉及到对于Runtime和compiler等的一些可移植要求。
面向Precision,这一点与业务的关系更加密切,也就是如何更好地优化模型的边界,从而更好地优化模型的精度。

阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
---阿里大数据博文,问答,社群,实践,有朋自远方来,不亦说乎……






