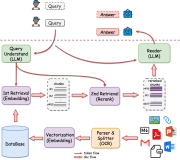
面向 open domain 的聊天机器人无论在学术界还是工业界都是个有挑战的课题,目前有两种典型的方法:一是基于检索的模型,二是基于 Seq2Seq 的生成式模型。前者回复答案可控但无法处理长尾问题,后者则难以保证一致性和合理性。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @britin。本文结合检索模型和生成模型各自的优势,提出了一种新的融合模型 — AliMe Chat。
阿里小蜜首先采用检索模型从 QA 知识库中找出候选答案集合,然后利用带注意力的 Seq2Seq 模型对候选答案进行排序,如果第一候选的得分超过某个阈值,则作为最终答案输出,否则利用生成模型生成答案。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:Britin,中科院物理学硕士,研究方向为自然语言处理和计算机视觉。
■ 论文 | AliMe Chat: A Sequence to Sequence and Rerank based Chatbot Engine
■ 链接 | https://www.paperweekly.site/papers/1302
■ 作者 | britin
论文动机
目前商用的 Chatbot 正在大量兴起,这种可以自然语言对话的方式来帮助用户解答问题比传统死板的用户界面要更友好。通常 Chatbot 包括两个部分:IR 模块和生成模块。针对用户的问题,IR 模块从 QA 知识库中检索到对应的答案,生成模块再用预训练好的 Seq2Seq 模型生成最终的答案。
但是已有的系统面临的问题是,对于一些长问句或复杂问句往往无法在 QA 知识库中检索到匹配的条目,并且生成模块也经常生成不匹配或无意义的答案。
本文给出的方法将 IR 和生成模块聚合在一起,用一个 Seq2Seq 模型来对搜索结果做评估,从而达到优化的效果。
模型介绍
整个方案如图所示:
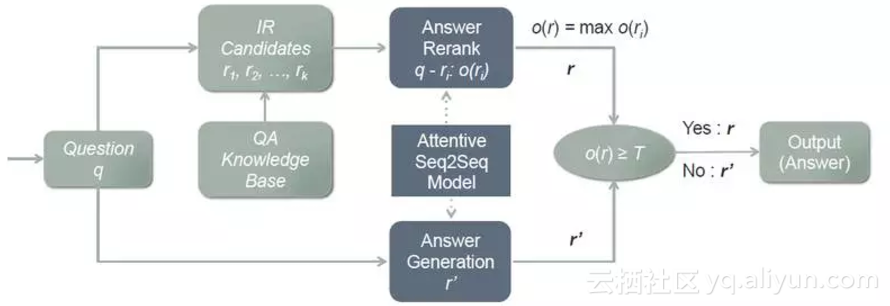
首先利用 IR 模型从知识库中检索到 k 个候选 QA 对,再利用 rerank 模型的打分机制计算出每个候选答案和问题的匹配程度。如果得分最高的那个大于预设好的阈值,就将其当作答案,如果小于阈值,就用生成模型生成答案。
整个系统是从单词层面上去分析的。
1. QA知识库
本文从在线的真人用户服务 log 里提取问答对作为 QA 知识库。过滤掉不包含相关关键词的 QA,最后得到 9164834 个问答对。
2. IR模块
利用倒排索引的方法将每个单词隐射到包含这个单词的一组问句中,并且对这些单词的同义词也做了索引,然后利用 BM25 算法来计算搜索到的问句和输入问句的相似度,取最相似问句的答案。
3. 生成模型
生成模型是一个 attentive seq2seq 的结构,如图所示:
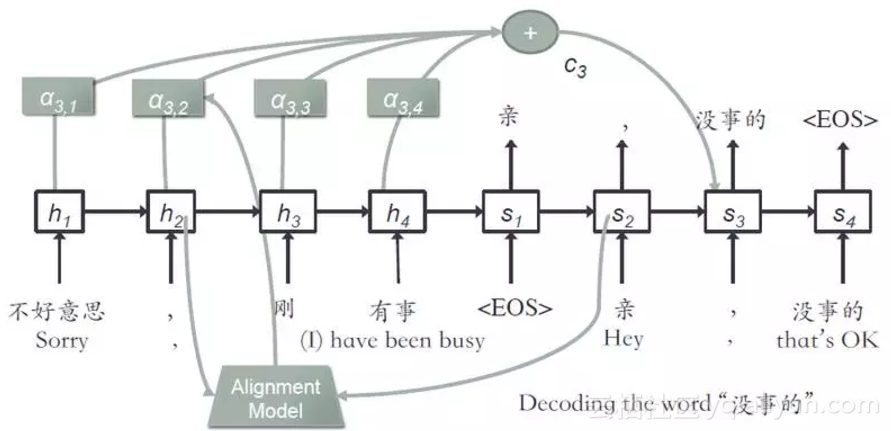
采用了一个 GRU,由 question 生成 answer,计算生成单词的概率:
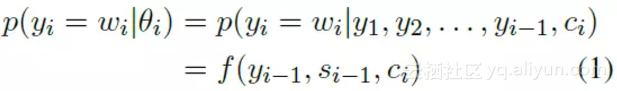
其中加了 context 向量,他是由图中的 α 求得的,α 表示的是当前步的输入单词,和上一步的生成单词之间的匹配度,用了一个 alignment 模型计算。
要注意,对于各个 QA 长度不等的情况,采用了 bucketing 和 padding 机制。另外用了 softmax 来随机采样词汇表中的单词,而不使用整个词汇表,从而加速了训练过程。还是用了 beam search decoder,每次维护 top-k 个输出,来取代一次一个输出的贪心搜索。
4. rerank 模块
使用的模型和上面是一样的,根据输入问题来为候选答案打分,使用平均概率作为评分函数:
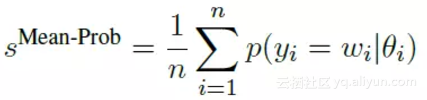
实验结果
本文对结果做了详细的评估,首先评估了 rerank 模块平均概率的结果。然后分别对 IR,生成,IR+rerank,IR+rerank+ 生成这些不同组合的系统做了性能评测。并对该系统和 baseline 的 Chatbot 做了在线 A/B 测试。最后比较了这个系统和已经上市的 Chatbot 之间的差别。
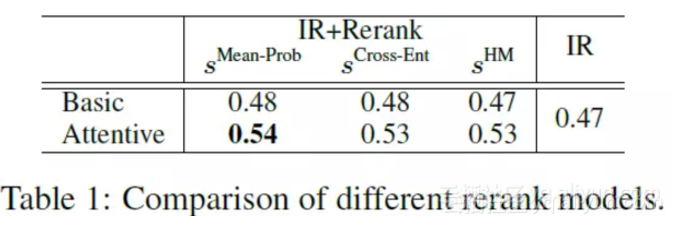
不同 rerank 模型的效果:
不同模块组合的结果:

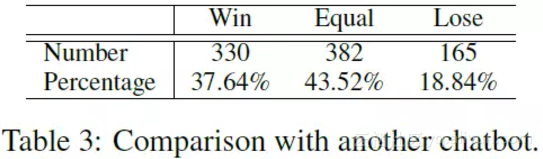
和 baseline 对比的结果:
文章评价
本文给出了一种 attentive Seq2Seq 的模型来结合 IR 和生成模块,从而对原结果进行 rerank 优化。阿里已经把这个投入了阿里小蜜的商用。
总的系统还是比较简单的,符合商用的需求。但由于函数设计过于简单,不排除是靠数据堆起来的系统,毕竟阿里有大量的真实用户数据,所以算法价值层面比较一般,没有合适的数据恐怕很难达到预期的效果。
原文发布时间为:2017-12-13
本文作者:Britin
本文来自云栖社区合作伙伴“PaperWeekly”,了解相关信息可以关注“PaperWeekly”微信公众号