距离阿尔法狗元版本刷屏一个多月时间,阿尔法狗又进化了,这次不光可以玩围棋,不再是“狗”了。我一点也不惊讶。
在用阿尔法狗(AlphaGo)和阿尔法狗元(AlphaGo Zero)称霸围棋世界后,当地时间周二晚,DeepMind的研究组宣布已经开发出一个更为广泛的阿尔法元(AlphaZero)系统,它可以训练自己在棋盘,将棋和其他规则化游戏中实现“超人”技能,所有这些都在一天之内完成,并且无需其他干预,战绩斐然:
4个小时成为了世界级的国际象棋冠军;2个小时在将棋上达到世界级水平;
8个小时战胜DeepMind引以为傲的围棋选手AlphaGo Zero。
这不禁让文摘菌想到了落入乾坤一气袋的张无忌瞬间精进的场景:
在各路高手的真力激荡之下打通数十处玄关,练成了独步天下的九阳神功,从此化身武林学霸。短短几个时辰内就练成了第七层乾坤大挪移,无论是太极拳剑还是圣火令武功都手到擒来,成为武林的百科全书。

尽管如此,阿尔法元(AlphaZero)距离一个真正的通用目标,独立AI,还有一定的距离 。国际象棋和将棋是比较容易的测试,因为它们比围棋简单。而像“星际争霸2”这样复杂的视频游戏完全是另一码事,更不用说散步、艺术或抽象思维等模糊的概念了。
另外还有速度的问题:虽然用来学习棋盘游戏的时间少于24小时,但对于AI需要现场适应的情况,速度太慢。DeepMind报告也说,训练该软件使用了5064台功能强大的定制机器学习处理器(被称为TPU)。(简直野蛮暴力)
但仍然不可否认,这是人工智能迈出的重要一步。
回忆人工智能的历史,很多人的印象都是一堆“各类技能”冠军——井字棋、跳棋和国际象棋。几十年来,研究人员已经研制了一系列超级专业的程序,在越来越高难度的游戏中击败人类。近期在围棋上,Deepmind的阿尔法狗也超越了人类。但是,这些人造冠军们的共同弱点是——都只能玩某一种精心设计的游戏。而人类即使在某些技能上输了,在精通多种技艺这一点上,仍然完爆人工智能。
近日,DeepMind官方宣布了第一个多技能的AI棋类游戏冠军程序。当地时间周二晚,Deepmind发布的一篇论文描述了一款名为AlphaZero的软件,它可以在三种具有挑战性的游戏中自学,表现超越人类:国际象棋,围棋或将棋(亦称日本象棋)。
DeepMind在文章中描述了AlphaZero的学习过程。人类不再是国际象棋,围棋和将棋中最好的选手,所以AlphaZero就用最好的专业人工选手(计算机程序Stockfish、Elmo、AlphaGo Zero)进行测试。这个新程序很快就打败了这三个人工棋手:
只用了4个小时成为了世界级的国际象棋冠军;用2个小时在将棋上达到世界级水平;只花了8小时战胜DeepMind引以为傲、也是之前已知最好的围棋选手AlphaGo Zero。
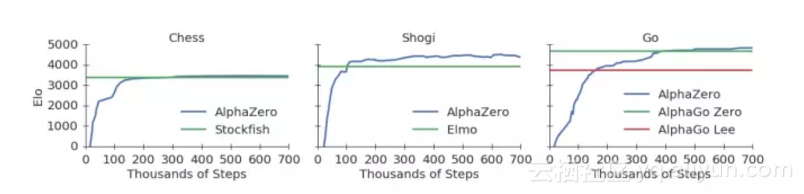
图:经过70万步训练的AlphaZero。它的对手是国际象棋的2016TCEC世界冠军程序Stockfish,将棋的2017CSA世界冠军程序Elmo,和大家都知道的AlphaGo Zero。每一手棋双方只有1秒的反应时间。
DeepMind也表示,新程序AlphaZero模仿AlphaGo Zero,通过同样的自我对练机制学习。AlphaZero核心的算法是它的升级版本,能够搜索更广泛的可能策略以适应不同的游戏。
AlphaZero可以从头开始学习三个游戏中的每一个,尽管它需要按照每个游戏的规则进行编程。该程序通过与自己对练提高技能成为专家,尝试不同的玩法来发现获胜的途径。
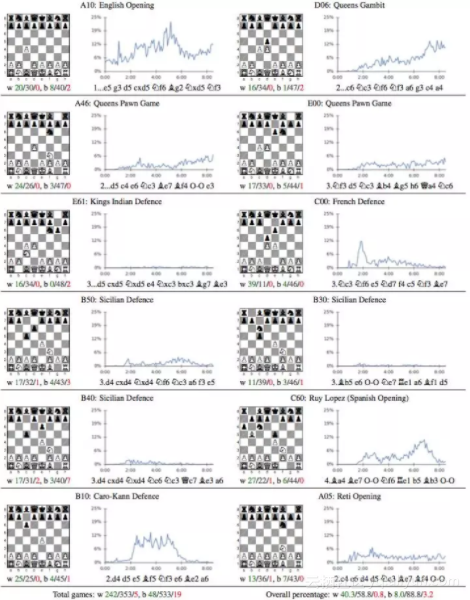
图:人类常用的国际象棋的12种开局方式解析
AlphaZero还没有办法学会同时参加三场比赛。但是,一个程序学习三种不同的复杂游戏,能达到如此高的水平,还是惊人的,因为AI系统——包括那些可以“学习”的——通常是非常专业的,需要经历磨练来解决特定的问题。即使是最好的人工智能系统也不能在两个问题之间进行泛化——因此,许多专家认为机器要取代人还有很长一段路要走。
AlphaZero可能是AI系统走向非专门化的一小步。纽约大学教授Julian Togelius在周二发布的推文中指出,真正泛化的AI还道阻且长,但称DeepMind的论文“非常出色”。
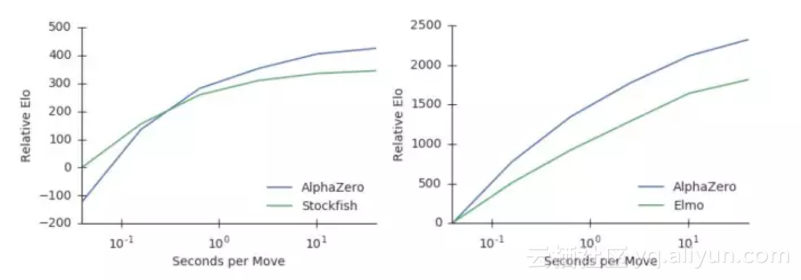
图:国际象棋和将棋中,AlphaZero每一手棋的思考时间,和相应的模型表现(Elo)
而DeepMind的这一研究进展对于业界来说也非常重要。更灵活的机器学习软件可以帮助谷歌加速在业务内部扩展人工智能技术。DeepMind最新发明中的技术也可能帮助团队挑战视频游戏“星际争霸”(StarCraft),后者已经成为它的下一个目标。一个流行的商业视频游戏似乎没有正式而抽象的棋盘游戏那么令人生畏。但“星际争霸”被认为复杂度更高,因为它各种变量和特征的安排自由度更大,玩家必须预见对手不可见的行为。
相比可以学习三个以上的棋盘游戏,并能解决各种空间,常识,逻辑,艺术和社会难题的人脑,AlphaZero的智力水平仍然有限。
DeepMind论文中显示,AlphaZero在三种游戏中使用了同样的算法设置、神经网络结构和超参数。训练过程包括70万步(4096大小的mini-batch),从随机生成的参数开始,使用了5000台TPU生成自对抗的棋局,接着使用64台TPU训练神经网络。
一共5064台TPU!文摘菌不得不感慨“何以解忧,唯有暴富”。

相较于阿尔法狗元(AlphaGo Zero)用到的64台GPU和19台CPU,AlphaZero的算力可谓得到了指数级提升。算法的训练时间也从阿尔法狗元的“几天”提升到了现在的“8小时”。
回头看看战胜了李世石和柯洁的惊天动地的阿尔法狗,已经显得像原始人了。它用到了1920台CPU和280台GPU,需要训练几个月。
人工智能的发展,有3个驱动力——数据、算法、算力。神经网络的“左右互搏”在数据和算法上做出了突破,而谷歌的TPU计算资源支持更是AlphaZero致胜的秘诀之一。
从10月底围棋超人阿尔法狗元的诞生,到12月进化成三种棋类超人阿尔法元,不过只用了短短一个多月的时间。
原文发布时间为:2017-12-7
本文作者:文摘菌