12月4日,也就是下周一,一年一度的NIPS就要正式召开了。这届NIPS从售票(提前2个月售完)到赞助(赞助商太多关闭赞助通道),屡屡创下新高。待到正式开幕,数千名研究人员和参会者“挤挤一堂”,绝非夸张。
那么,作为新智元NIPS系列报道的第一篇,我们将在本文中做一个初步的全景式介绍,包括会议信息,比如大会的Chair、Tutorial和Workshop情况,大会亮点,比如受邀报告,以及DeepMind、Facebook这些顶级研究院的工作。
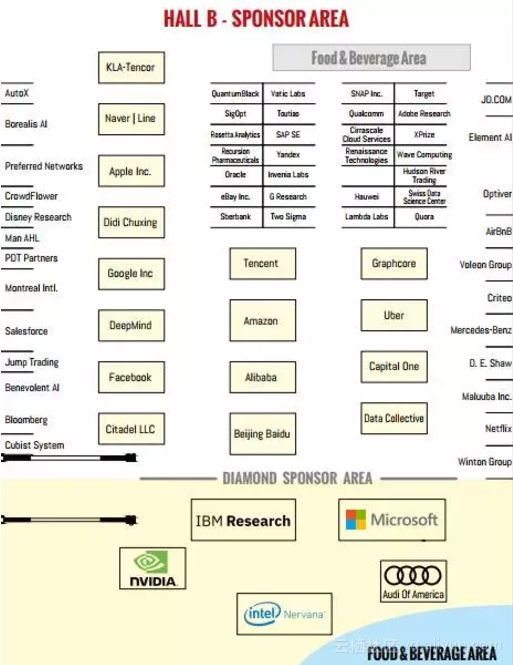
会议赞助:瞥见当前AI产业势力分布缩影
翻开大会手册(https://media.nips.cc/Conferences/NIPS2017/NIPS-2017-Conference-Book.pdf),首先是赞助商,会议手册用了整整6页将他们放下。NIPS 2017的钻石赞助商是:Intel Nervana、英伟达、奥迪、IBM Research和微软。

接下来的铂金赞助商,才出现了或许更能立刻让人想到的几个名字。

其他档位的赞助商中,熟悉的名字包括京东、Juergen Schmidhuber的Renaissance、Maluuba、Yoshua Bengio做顾问的Element AI,华为、今日头条,360,以及Eric Xing教授联合创立的Petuum。
这个赞助商展位图似乎让人瞥见了当前AI产业的一个缩影。
程序主席谷歌、微软、Facebook和亚马逊四家凑一桌,会议组织管理层尚无华人
好,回到会议本身。本届NIPS由Isabelle Guyon(U. Paris-Saclay & ChaLearn)和Ulrike von Luxburg(U. of Tübingen)两位学者坐镇担任大会主席(General Chair),程序主席(Program Chair,PC)是谷歌大脑的Samy Bengio,其他三位联合PC分别来自微软、Facebook和亚马逊:Hanna Wallach(MSR NYC)、Rob Fergus(FAIR/NYU),以及S.V.N. Vishwanathan(UCSC & Amazon),可谓凑齐一桌。
虽然目前没有确切的统计数据,但根据NIPS官网给出的论文信息,我们知道投稿论文作者以及随之的参会者,有将近40%是华人以及来自中国大陆的学生和学者,但是,在会议的组织和管理层(Organizing Committee),还没有华人。
不过,在领域主席中,有Eric Xing(Senior Area Chair)、沙飞、李航、虞晶怡、邓力、刘铁岩和周志华等。
大会亮点:Tutorial和Workshop,关注新智元V直播现场互动
如果说NIPS有不能错过的东西,那么一定是各种Tutorial和Workshop。据不完全统计,本届NIPS一共有50多个tutorial和workshop,从贝叶斯学习到理解人类行为,覆盖了各方各面。例如,
周一上午的《深度学习:实践与趋势》(周一,Hall A,上午8:00),组织者是Nando de Freitas, Scott Reed, Oriol Vinyals。
周一下午,《几何深度学习》(Geometric Deep Learning on Graphs and Manifolds),也是在Hall A,组织者是 Michael Bronstein, Joan Bruna, Arthur Szlam, Xavier Bresson, Yann LeCun。
关于Tutorial和Workshop,新智元会专门出报道,敬请期待。同时,新智元智库专家、CMU计算机学院副教授马坚老师将在美国长滩带来现场直播,关注新智元小程序或加入直播群,参与直播互动,第一时间了解马坚教授带来的NIPS前沿资讯。扫码入群详见文末。
7场受邀报告,重磅嘉宾:Hinton“向量学院”联合创始人、白宫AI研讨会主持人、谷歌应用科学部门负责人,话题覆盖AI基因编码、能源战略、学习大脑状态表示,以及贝叶斯深度学习

Brendan Frey是深度学习基因公司Deep Genomics联合创始人兼CEO,AI向量学院的联合创始人,多伦多大学工程和医学教授。他是国际公认的机器学习和基因组生物学领域的领导者,他的研究小组在Science, Nature 和 Cell等杂志上发表了十几篇论文。他因利用深度学习识别蛋白质-DNA相互作用而登陆Nature Biotechnology(2015)的封面。而他深度学习的研究可追溯到在Science 1995上发表的关于变分自编码器的论文。
演讲内容:为什么AI使人类基因重新编码变成可能
我们已经弄清楚了如何用DNA编辑技术来写基因,但我们不知道基因修改的后果是什么,这被称之为“基因型表型差异”。为了缩小差距,我们需要逆向工程遗传密码,这是非常困难的,因为对于人类的理解能力来说,生物学太复杂,干扰太大。机器学习和人工智能是必需的。数据?每个基因组有60亿对碱基母,成百上千种生物分子,数百种细胞类型,超过70亿人口。新一代的“生物IA”研究人员准备解决这个问题,但我们面临着非同寻常的挑战。我将讨论这些聚焦在人工智能和机器学习分支的挑战将产生的最大影响和原因。

Kate Crawford教授是主要研究者、学者和作者,他花了10年时间研究大数据、机器学习和人工智能的社会影响。她是纽约大学杰出的研究教授,纽约微软研究院的首席研究员,麻省理工学院媒体实验室的客座教授,2016,她主持了在白宫召开的有关未来十年人工智能对社会和经济影响的研讨会。她是AI和机器人的世界经济论坛全球议程委员会委员,最近被任命为Richard von Weizsaecker Fellow研究员。
演讲题目:偏差的烦恼
计算机科学家越来越关注机器学习可以复制和强化偏差形式的方法。当机器学习纳入到诸如医疗健康、刑事司法和教育等核心社会机构时,偏见和歧视问题可能极其严重。但是我们能做些什么呢?高风险决策产生的机器学习偏差部分麻烦是它可能是一个或多个因素导致的:培训数据、模型、系统目标,以及系统是否不适用于部分人群。理解机器学习如何产生一个特定的结果是非常困难的,偏差通常在系统已经产生不公平的结果后才被发现。但另外的问题是:对偏差的定义取决于你的行为举止,在其他领域还存在令人兴奋的方法尚未被计算机科技收纳。这个研究将讨论最近关于机器学习偏差的文献,思考我们如何结合社会科学的方法,来找到消除偏差的出路。

John Platt以机器学习而著称:支持向量机的SMO算法和模型的输出校准。是上世纪90年卷积神经网络的先驱。他在上世纪90年代的卷积神经网络的早期采用者。然而,约翰已经在许多不同的领域工作:数据系统、计算几何、物体识别、媒体研究、模拟计算、手写识别、数学与应用数学。他发现了两颗小行星,并因其计算机绘图工作获得2006年度奥斯卡金像奖。目前主持谷歌研究所的应用科学分支。
演讲内容:减少二氧化碳排放的能源战略
气候变化问题是很难解决的。一方面,化石燃料在人类文明中无处不在:我们通过燃烧化石燃料获得16兆瓦的电力。另一方面,根据气候模型,以当前的燃烧速度,我们还有不到30年的时间,能让全球平均升温保持在2℃以下。有很多策略来对抗气候变化。本次演讲将试图通过经济建模来澄清疑惑。首先,我要给大家一个关于能源系统的教程。然后,我将给出一个简单的经济模型,它可以预测发电所产生的成本和二氧化碳排放量。通过研究可能出现的场景来找到如何以最少的成本显著减少二氧化碳排放量的解决方案。从经济模型上的最大教训是,我们需要个强大的能量奇迹:一个7*24小时二氧化碳零排放的技术,可以产生比燃烧化石燃料产生更低成本的电力。目前,没有这样的技术。我将讨论这一可能成为强大能源奇迹的技术,并讨论实现这一目标的进展。

Lise Getoor是加州大学圣克鲁兹分校计算机科学系的教授。 她的研究领域包括机器学习,数据整合和不确定性推理,重点在于图表和网络数据。她发表了超过250篇论文,拥有丰富的机器学习和图形和网络数据概率建模方法的经验。
演讲题目:结构的惊人有效性
我们收集,操纵,分析和处理大量数据的能力对社会的各个方面都产生了深远的影响。这些数据大部分是异构数据,并且通过无数复杂的方式相互联系。从信息集成到科学发现再到计算社会科学,我们需要机器学习方法,挖掘领域内的固有不确定性和内在结构。统计关系学习(SRL)是建立在概率论和统计学原理基础上的一个子领域,致力于解决不确定性问题,同时结合知识表示和逻辑的工具来表示结构。在这个演讲中,我将简要地介绍一下SRL,为常见的结构化预测问题提供模板,并描述混合逻辑,概率推理和潜在变量的建模方法。我将概述我们最近关于概率软逻辑(PSL)的工作。最后,我将强调实现知识发现的数据和结构有效性的机会(和挑战!!)。

Pieter Abbeel(加州大学伯克利分校副教授,OpenAI研究科学家,Gradescope联合创始人),从事机器学习和机器人技术,尤其是关于让机器人学习人类(学徒学习),让机器人如何通过自己的反复试验(强化学习)来学习的研究。
演讲题目:机器人技术中的深度学习
计算机科学家越来越关注机器学习在复制和强化偏见的很多方式。当ML系统被纳入医疗保健,刑事司法和教育等核心社会机构时,偏见和歧视问题可能非常严重。但是,我们可以做些什么呢?机器学习在高风险决策中存在偏差的部分原因可能有很多原因:训练数据,模型,系统目标以及系统对某些人群的工作是否不太好。鉴于理解机器学习系统如何产生特定结果十分困难,偏见往往是在系统产生不公平的结果之后才会被发现。但是,还有另外一个问题:偏见的定义会根据你的学科而有很大的变化,其他领域还有一些尚未被计算机科学所接受的令人兴奋的方法。这次演讲将着眼于最近关于机器学习偏见的文献,考虑如何整合社会科学的方法,并提出解决偏见的新策略。

Yael Niv获得特拉维夫大学精神生物学硕士学位,拥有希伯来大学博士学位。
演讲题目:学习状态表示
从表面上看,从强化学习机制的角度来看,大多数现实世界的任务都十分复杂。特别是由于“维度的诅咒”,即使是想穿过街道这样的简单工作,原则上也要经过数千次的尝试机器才能掌握。我们的大脑如何做呢?在这个演讲中,我认为,学习中最难的部分不是分配价值或学习策略,而是决定经验之间的相似性界限,这决定了我们所知的“状态”。我将展示人类和动物不断参与这个表示学习过程的行为证据,并且建议在不太远的将来,我们可以从脑中读出这些表示,从而找出大脑是如何掌握这个复杂的问题。我将使用无限容量模型的贝叶斯推理来形式化学习状态表示的问题,我认为理解表示学习的计算问题可以让我们对迁移学习的机器学习问题以及心理/神经科学问题关于记忆和学习之间的相互作用有所了解。

Yee Whye The是牛津大学统计系统计机器学习教授,DeepMind的研究员、艾伦·图灵研究所研究员以及ERCC会员。获得了多伦多大学哲学博士学位(与Geoffrey Hinton合作),并在加州大学伯克利分校做博士后站(与Michael Jordan搭档)和新加坡国立大学(Lee Kuan Yew博士后)工作,2017 ICML和2010 AISTATS联席主席。主要研究方向是计算和统计基础智能化,可扩展的机器学习,概率模型,贝叶斯非参数,以及深度学习。
演讲内容:贝叶斯深度学习和深度贝叶斯学习
概率和贝叶斯推理是我们理解机器学习首要的理论支柱之一。在过去的二十年中,它激发了一系列成功的机器学习方法,对许多研究人员在这一领域的思考产生了深远影响。另一方面,在过去的几年里,深度学习的兴起彻底改变了这个领域,并衍生出了诸如时代定义、成功等现象的定义。在这次演讲中,我将探讨机器学习中这两者之间的接口,通过参与一些项目,我发现了这些问题:概率思维如何帮助我们理解深度学习的方法,或带给我们更有趣的新方法?相反,深度学习技术如何帮助我们发展更先进的概率论?
DeepMind@NIPS 2017:16篇论文,模仿学习、关系推理,继续探索深度强化学习
这一节,新智元集中介绍DeepMind在本届会议的工作,展示地点在Pacific Ballroom,到现场的同学可以去看。
Day 1 (12月4日,周一)
《对不同行为的强大模仿》
作者: Ziyu Wang, Josh Merel, Greg Wayne, Nando de Freitas, Scott Reed, Nicolas Heess
“我们提出了一个建立在state-of-the-art生成模型之上的神经网络架构,它能够学习不同行为之间的关系,并模仿它所观察到的特定行为。训练结束后,系统可以编码一个单一的被观察的动作,并基于此创建一个新的动作。即使从来没有看到不同动作之间的转换,它也可以切换自如,例如在走路风格间切换。”想了解更多,请查看博客。
《神经网络的Sobolev训练》
作者: Wojtek Czarnecki, Simon Osindero, Max Jaderberg, Grzegorz Świrszcz, Razvan Pascanu
文给出了一种将目标函数导数的知识纳入深度神经网络训练的简单方法。我们证明基于ReLU的架构非常适合这样的任务,并评估了它们在三个问题上的有效性:low-dimensional regression,policy distillation和training with synthetic gradients。我们观察到训练效率的显著提高,特别是在低数据情况下,并且以接近state-of-the-art的准确度训练了第一个基于synthetic gradients的ImageNet模型。
Day 2 (12月5日,周二)
《过滤变分目标》
作者: Chris J. Maddison, Dieterich Lawson, George Tucker, Nicolas Heess, Mohammad Norouzi, Andriy Mnih, Arnaud Doucet, Yee Whye Teh
我们考虑将变分下界扩展到由粒子滤波器的边际可能性估计量定义的下界,即过滤变分目标。这些过滤目标可以利用模型的顺序结构,在深度生成模型中形成更紧密的边界和更好的模型学习目标。实验中,我们发现用滤波目标进行训练比使用变分下限训练相同的模型体系结构有了实质性的改进。
《视觉交互网络:从视频中学习物理模拟器》
作者: Nicholas Watters, Andrea Tacchetti, Theophane Weber, Razvan Pascanu, Peter Battaglia, Daniel Zoran
“在这项工作中,我们开发了视觉交互网络(Visual Interaction Network,VIN),这是一个基于神经网络的模型,在没有先验知识的情况下学习物理动力学。 VIN能够从几帧视频中推断出多个物理对象的状态,然后用这些来预测对象位置。它还能够推断隐形物体的位置,并学习依赖于物体属性(如质量)的动态。”请阅读博客以了解更多细节。
《神经离散表示学习》
作者: Aäron van den Oord, Oriol Vinyals, Koray Kavukcuoglu
在无监督的情况下学习有用表示仍然是机器学习中的关键挑战。在这项工作中,我们提出了一个简单而强大的生成模型,被称为矢量量化VAE (Vector Quantised Variational AutoEconder ,VQ-VAE),能够学习这种离散表示。当这些表示与先前的自回归配对时,该模型能够生成高质量的图像、视频和语音以及进行高质量的扬声器转换。
《生成模型中的变分内存addressing》
作者: Jörg Bornschein, Andriy Mnih, Daniel Zoran, Danilo Jimenez Rezende
基于注意力的内存可用于增强神经网络,以支持少量学习、快速适应性和更通用地支持非参数扩展。我们不使用流行的可区分的soft-attention机制,而是使用随机hard-attention来生成模型中的内存内容。这使得我们可以将变分推理应用于内存addressing,能够使用目标信息获得更精确的内存查找,特别是在内存缓冲区大且内存条目混杂的模型中。
Day 3 (12月6日,周三)
《REBAR:离散潜变量模型的低方差、无偏差梯度估计》
作者: George Tucker, Andriy Mnih, Chris J Maddison, Dieterich Lawson, Jascha Sohl-Dickstein
由于具有高方差梯度估计量,对具有离散潜变量的模型进行学习具有挑战性。以前的方法会产生高方差、无偏差梯度,或产生低方差,有偏差梯度。 REBAR使用控制变量和重新参数化技巧来获得两者中最好的结果:低方差,无偏差的梯度,使得收敛更快,效果更好。
《想象力增强代理深度强化学习》
作者: Sébastien Racanière, Théophane Weber, David P. Reichert, Lars Buesing, Arthur Guez, Danilo Rezende, Adria Puigdomènech Badia, Oriol Vinyals, Nicolas Heess, Yujia Li, Razvan Pascanu, Peter Battaglia, Demis Hassabis, David Silver, Daan Wierstra.
我们描述了一个基于想象力的规划方法的体系,我们还介绍了为代理人学习和构建计划以最大化任务效率提供新方法的架构。 这些架构对于复杂和不完善的模型是有效稳健的,并且可以采取灵活的策略来利用他们的想象力。 代理受益于一个“想象编码器” ,这是一个神经网络,它学习提取任何对代理未来决策有用的信息,忽略那些不相关的信息。
《用于关系推理的简单神经网络模块》
作者:Adam Santoro, David Raposo, David Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, Timothy Lillicrap
我们演示了使用简单的即插即用的神经网络模块来解决需要复杂关系推理的任务。 这个称为关系网络的模块可以接收非结构化的输入,比如说图像或者故事,并且隐含地推理出其中包含的关系。
《使用深度集合的简单可扩展的预测不确定性估计》
作者: Balaji Lakshminarayanan, Alexander Pritzel, Charles Blundell
量化神经网络中的预测不确定性是一个具有挑战性但尚未解决的问题。大部分工作集中在贝叶斯解决方案上,但这些都是计算密集型的,需要对训练pipeline进行重大修改。 我们提出了一个贝叶斯神经网络的替代方案,易于实现,易于并行,只需很少的超参数调整,并产生高质量的预测不确定性估计。 通过一系列关于分类和回归基准的实验,我们证明了这一方法产生良好校准的不确定性估计,其与近似贝叶斯神经网络一样好或更好。
《自然价值逼近者:学习何时相信过去的估计》
作者:Zhongwen Xu, Joseph Modayil, Hado van Hasselt, Andre Barreto, David Silver, Tom Schaul
基于典型的近似值随输入而平滑变化的观察,我们重新回顾RL的价值逼近器的结构,但是当一个回报到达时,true value会突然变化。 我们提出的方法被设计来适应这种不对称的不连续性,使用插值与预测值估计。
《强化学习转移的后继特征》
作者: Andre Barreto, Will Dabney, Remi Munos, Jonathan Hunt, Tom Schaul, David Silver, Hado van Hasselt.
我们提出一个强化学习的转移框架。我们的方法取决于两个关键点:“后继特征”,一种价值函数表示,将环境的动态与回报分离开来;“广义的决策改进”,一种动态编程决策改进步骤的一般化,能考虑到全部决策,而非单一决策。综合起来,这两点导致了强化学习间无缝衔接的方式,并允许在任务之间进行转移且不受任何限制。
《从人类偏好中学习的深度强化学习》
作者: Paul Christiano (Open AI), Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei (Open AI)
“人工智能技术安全的核心问题是如何告诉一个算法我们希望它做什么。与OpenAI合作,我们展示了一个新颖的系统,允许没有技术经验的人员教AI如何执行一个复杂的任务,如操纵一个模拟机器人手臂。”
《共享资源占用的多代理强化学习模型》
作者: Julien Perolat, Joel Z Leibo, Vinicius Zambaldi, Charles Beattie, Karl Tuyls, Thore Graepel
本文考察了共享资源占用问题的复杂性。渔业、放牧牧场或淡水等系统中,许多人或行动者可以获得相同的资源。社会科学的传统模式往往表明,获得资源的各方以自利的方式行事,最终导致不可持续的资源枯竭。但是,我们从人类社会知道,有很多可能的结果。有时像渔业这样的资源被过度开发,有时它们被可持续地收获。在这项工作中,我们提出了新的建模技术,旨在解释现实世界中观察到的与传统模型预测的差距。
《DisTraL:强大的多任务强化学习》
作者: Yee Whye Teh, Victor Bapst, Wojciech Czarnecki, John Quan, James Kirkpatrick, Raia Hadsell, Nicholas Heess, Razvan Pascanu
我们开发一个强化多任务学习的方法。 假定任务是彼此相关的(例如处于相同的环境或具有相同的物理属性),所以好的动作序列往往跨任务重复出现。 我们的方法通过将特定于任务的策略同时提炼为一个通用的默认策略,并通过将所有特定于任务的策略规则转化为违约策略来跨这些任务转移这些常识。 我们发现这将引导更快、更强大的学习。
《一个统一的博弈论的方法引导多主体强化学习》
作者:Marc Lanctot, Vinicius Zambaldi, Audrunas Gruslys, Angeliki Lazaridou, Karl Tuyls, Julien Perolat, David Silver, Thore Graepel
在这项工作中,我们首先观察到独立强化学习者产生可以共同关联的策略,在执行过程中未能与其他主体进行良好的互动。 我们通过提出一个称为联合策略关联的新度量来量化这种影响。 然后,我们提出了一个由博弈论基础所推动的算法,该算法概括了虚拟游戏,迭代最佳响应,独立RL和双重oracle等几种方法。 我们表明,算法可以在第一人称协调游戏中显著降低联合策略的相关性,并在普通的扑克基准游戏中找到强大的反策略。
Facebook@NIPS 2017
最后,我们简单介绍Facebook在本届NIPS的活动,包括田渊栋等人的ELF论文,以及贾扬清的workshop。
Best of Both Worlds: Transferring Knowledge from Discriminative Learning to a Generative Visual Dialog Model
Jiasen Lu, Anitha Kannan, Jianwei Yang, Devi Parikh, and Dhruv Batra
视觉对话(Visual Dialog)要求AI智能体以自然的、对话式的语言与人类就视觉内容进行有意义的对话。例如,考虑一下使用社交媒体的盲人用户。他们的朋友上传了一张图片,如果人工智能能够描述这张图片,那就对他们大有帮助。比如AI描述图片说:“约翰刚在夏威夷度假时上传了一张照片”。用户可能会问:“太好了,他在海边吗?”我们希望AI能够自然、准确地回应“不,在山上”。或者如果你正在与AI助理互动,你可能会问:“你可以从婴儿监视器中看到宝宝吗?”AI:“是的,我可以。”你:“他在睡觉还是在玩耍?”对于这些情况,我们想要一个准确的答案。或者想象一个人形机器人团队执行搜救任务的场景。人类:“你周围的房间里有烟吗?”AI:“是的,我在一个房间里。”人类:“去那里寻找人”。我们希望AI能够参照前面的对话来理解这条指令。在本文中,我们开发了最先进的神经模型,给出图像、对话历史和图像的后续问题,AI能够回答这个问题。
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
Yuandong Tian, Qucheng Gong, Wenling Shang, Yuxin Wu, and Larry Zitnick
ELF是一个扩展性、轻量级、灵活的平台,支持游戏环境的并行模拟。使用ELF,我们在几个游戏上实现了一个高度可定制的实时战略(RTS)引擎,比其他平台快了一个数量级。
Fader Networks: Manipulating Images by Sliding Attributes
Guillaume Lample, Neil Zeghidour, Nicolas Usunier, Antoine Bordes, Ludovic Denoyer, and Marc’Aurelio Ranzato
我们提出一种新的编码器 - 解码器架构,通过使用对抗训练直接在潜在空间中解构其显著信息和特定属性的值来重建图像。这种结构让我们可以操作这些属性,并产生变化的脸部图片,同时保持其自然。与现有技术相比,在像素空间中通过改变训练时间的属性值来训练对抗网络,我们的方法实现更简单的训练方案。
Gradient Episodic Memory for Continual Learning
David Lopez-Paz and Marc’Aurelio Ranzato
机器学习模型努力学习新的问题,而不会忘记以前的任务。在本文中,我们提出了新的学习指标来评估模型如何在一系列学习任务中传递知识。最后,我们提出了一种新的算法,即梯度情景记忆( Gradient Episodic Memory ,GEM),它允许学习机器在不忘记过去的知识的情况下学习新的任务技能。
Houdini: Fooling Deep Structured Prediction Models
Moustapha Cisse, Yossi Adi, Natalia Neverova, and Joseph Keshet
生成对抗样本是评估和提高学习机器鲁棒性的关键步骤。到目前为止,大多数现有的方法只能用于分类,而不是用来改变当前问题的真实性能指标。我们引入了一种名为Houdini的新颖、灵活的方法,用于生成专门针对所考虑的任务的最终性能度量而制定的对抗样本,无论样本是组合的还是不可分解的。我们成功地将Houdini应用于一系列应用,如语音识别,姿态估计和语义分割。在所有情况下,基于Houdini的对抗的成功率都高于传统的用于训练模型的方法。
One-Sided Unsupervised Domain Mapping
Sagie Benaim and Lior Wolf
2017年的一个主要发现是可以在没有任何匹配的训练样本的情况下学习两个视觉域之间的类比关系。例如,输入一个手袋的图像,这些方法可以找到与手袋匹配的鞋子,虽然它从来没有见过这样的匹配。最近的方法都需要学习从一个域到另一个域的映射。这项研究提出了一个不需要完成这个循环的解决方案,因此效率更高。我们还证明了这一方法所得到的映射比以前的更准确。
On the Optimization Landscape of Tensor Decompositions
Rong Ge and Tengyu Ma
论文分析了随机ove complete 张量分解问题图景,这在非监督学习,尤其是学习潜变量模型方面有很多应用。在实践中,它可以通过非凸目标上的梯度上升来有效地解决。我们的理论结果显示,对于任意小常数ε> 0,函数值为(1 +ε) - 因子集大于函数期望的集合中,所有局部最大值都是近似的全局最大值。
Poincaré Embeddings for Learning Hierarchical Representations
Maximilian Nickel and Douwe Kiela
表示学习已经成为建模诸如文本和图形等符号数据的宝贵方法。这类数据往往表现出潜在的等级结构:例如,所有的海豚都是哺乳动物,所有的哺乳动物都是动物,所有的动物都是生物,等等。捕获这种层次结构对于人工智能中的许多核心问题是有利的,例如推理或建模复杂关系。我们引入了一种学习表示的新方法,同时捕获关于层级和相似性的信息。我们通过改变嵌入空间的基本几何条件来实现这一点,并引入一种有效的算法来学习这些分层嵌入。我们通过实验表明,所提出的模型在表示能力和泛化能力方面都明显优于标准方法。
Unbounded Cache Model for Online Language Modeling with Open Vocabulary
Edouard Grave, Moustapha Cisse, and Armand Joulin
现代机器学习方法中,数据分布的变化,训练和测试之间的变化并不稳健。例如,在维基百科上训练模型并在新闻数据上测试时,会出现这个问题。在这项工作中,我们提出了一个大规模的非参数内存组件,用于动态地将模型适应新的数据分布。我们将这种技术应用于语言建模,其中训练和测试数据来自两个不同的领域(如维基百科和新闻)。
VAIN: Attentional Multi-agent Predictive Modeling
Yedid Hoshen
预测大型社会系统或物理系统的行为需要对智能体之间的交互进行建模。通过将每个交互作为神经网络进行建模,最近这样的方法的预测结果已经有显著改进,然而这种方法成本过高。在这项工作中,我们用一个简单的注意力机制取代昂贵的交互模型,达到相似的准确性,但成本却低得多。我们的方法的线性复杂性可以让精确的多智能体预测模型在更大的范围内运行。
Facebook在 NIPS 2017的其他活动
在各个活动中,机器学习系统论坛是重头戏,其中包括了贾扬清主题演讲Caffe2、还有Sarah Bird ,Dmytro Dzhulgakov介绍联盟其他巨头的ONNX,以及 Soumith Chintala介绍PyTorch – Soumith Chintala。
Tutorials
Geometric Deep Learning on Graphs and Manifolds
讲者:Arthur Szlam 和 Yann LeCun
Workshops & Symposiums
Black in AI Workshop
参与组织:Moustapha Cisse, Facebook organizer
Deep Learning at Supercomputer Scale Workshop
主题:一个小时训练ImageNet
讲者: Priya Goyal
Deep Reinforcement Learning 论坛
讲者:Joelle Pineau
Emergent Communication Workshop
参与组织:Kyunghyun Cho ,Douwe Kiela
Interpretable Machine Learning论坛
Attentive Explanations: Justifying Decisions and Pointing to the Evidence
论文展示:Marcus Rohrbach,
Learning Disentangled Representations: from Perception to Control Workshop
参与组织:Diane Bouchacourt
Learning in the Presence of Strategic Behavior Workshop
主题演讲:Alexander Peysakhovich
Machine Learning on the Phone and other Consumer Devices Workshop
参与组织:Joaquin Quiñonero Candela
Machine Learning Systems Workshop
参与组织者:Sarah Bird ,Aparna Lakshmi Ratan
- An Open-Source Recipe for Real-Time, Adaptive Classifiers in a Planetary-Scale Network – Dejan Curcic and Chris Kappler, 主题演讲
- Caffe2 –贾扬清, 主题演讲
- ONNX – Sarah Bird, Dmytro Dzhulgakov,主题演讲
- PyTorch – Soumith Chintala,主题演讲
Optimization for Machine Learning Workshop
主题演讲: Non-Uniform Stochastic Dual Coordinate Ascent for Conditional Random Fields
讲者:Remi Le Priol, Ahmed Touati, Simon Lacoste-Julien, Poster
Women in Machine Learning (WiML) workshop
讲者:Joelle Pineau
圆桌: Joelle Pineau 、Devi Parikh
Workshop on Automated Knowledge Base Construction (AKBC)
主题演讲:Learning Hierarchical Representations of Relational Data
讲者:Maximilian Nickel
Workshop on Conversational AI: Today’s Practice and Tomorrow’s Potential
参与组织:Antoine Bordes
讲者:Joelle Pineau
Workshop on Visually-Grounded Interaction and Language (ViGIL)
参与组织:Devi Parikh, Dhruv Batra,
主题演讲:Embodied Question Answering
讲者: Devi Parikh
原文发布时间为:2017-12-2
本文作者:新智元编辑部
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号
