在全球人工智能领域不断发展的今天,包括Google、Facebook、Microsoft、Amazon、Apple等互联公司相继推出了自己的智能私人助理和机器人平台。 智能人机交互通过拟人化的交互体验逐步在智能客服、任务助理、智能家居、智能硬件、互动聊天等领域发挥巨大的作用和价值。
因此,各大公司都将智能聊天机器人作为未来的入口级别的应用在对待。今天随着市场的进一步发展,聊天机器人按照产品和服务的类型主要可分为:客服,娱乐,助理,教育,服务等类型。
下图截取了部分聊天机器人。
一些chat-bot的汇总
阿里小蜜在电商领域的状况
2015年7月,阿里推出了自己的智能私人助理-阿里小蜜,一个围绕着电子商务领域中的服务、导购以及任务助理为核心的智能人机交互产品。通过电子商务领域与智能人机交互领域的结合,带来传统服务行业模式的变化与体验的提升。
在去年的双十一期间,阿里小蜜整体智能服务量达到643万,其中智能解决率达到95%,智能服务在整个服务量(总服务量=智能服务量+在线人工服务量+电话服务量)占比也达到95%,成为了双十一期间服务的绝对主力。
电商领域下阿里小蜜的技术实践
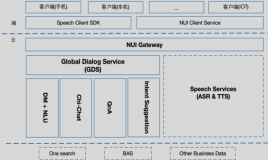
阿里小蜜技术的overview
智能人机交互系统,俗称:chatbot系统或者bot系统。下图是人机交互的流程图:
人机交互的流程
核心是NLU(自然语言理解),通过对话系统处理后,最后通过自然语言生成的方式给出答案。一段语言如何理解对于计算机来说是非常有难度的,例如:“苹果”这个词就具备至少两个含义,一个是水果属性的“苹果”,还有一个是知名互联网公司属性的“苹果”。
意图与匹配分层的技术架构体系
在阿里小蜜这样在电子商务领域的场景中,对接的有客服、助理、聊天几大类的机器人。这些机器人,由于本身的目标不同,就导致不能用同一套技术框架来解决。因此,我们先采用分领域分层分场景的方式进行架构抽象,然后再根据不同的分层和分场景采用不同的机器学习方法进行技术设计。首先我们将对话系统从分成两层:
1、 意图识别层:识别语言的真实意图,将意图进行分类并进行意图属性抽取。意图决定了后续的领域识别流程,因此意图层是一个结合上下文数据模型与领域数据模型不断对意图进行明确和推理的过程;
2、 问答匹配层:对问题进行匹配识别及生成答案的过程。在阿里小蜜的对话体系中我们按照业务场景进行了3种典型问题类型的划分,并且依据3种类型会采用不同的匹配流程和方法:
a) 问答型:例如“密码忘记怎么办?”→ 采用基于知识图谱构建+检索模型匹配方式
b) 任务型:例如“我想订一张明天从杭州到北京的机票”→ 意图决策+slots filling的匹配以及基于深度强化学习的方式
c) 语聊型:例如“我心情不好”→ 检索模型与Deep Learning相结合的方式
下图表示了阿里小蜜的意图和匹配分层的技术架构。
基于意图于匹配分层的技术架构
意图识别介绍:结合用户行为deep-learning模型的实践
通常将意图识别抽象成机器学习中的分类问题,在阿里小蜜的技术方案中除了传统的文本特征之外,考虑到本身在对话领域中存在语义意图不完整的情况,我们也加入了用实时、离线用户本身的行为及用户本身相关的特征,通过深度学习方案构建模型,对用户意图进行预测, 具体如图:
结合用户行为的深度学习意图分类
在基于深度学习的分类预测模型上,我们有两种具体的选型方案:一种是多分类模型,一种是二分类模型。多分类模型的优点是性能快,但是对于需要扩展分类领域是整个模型需要重新训练;而二分类模型的优点就是扩展领域场景时原来的模型都可以复用,可以平台进行扩展,缺点也很明显需要不断的进行二分,整体的性能上不如多分类好,因此在具体的场景和数据量上可以做不同的选型。
小蜜用DL做意图分类的整体技术思路是将行为因子与文本特征分别进行Embedding处理,通过向量叠加之后再进行多分类或者二分类处理。这里的文本特征维度可以选择通过传统的bag of words的方法,也可使用Deep Learning的方法进行向量化。具体图:
结合用户行为的深度学习意图分类的网络结构
匹配模型的overview:介绍行业3大匹配模型
目前主流的智能匹配技术分为如下3种方法:
1、 基于模板匹配(Rule-Based)
2、 基于检索模型(Retrieval Model)
3、 基于深度学习模型(Deep Learning)
在阿里小蜜的技术场景下,我们采用了基于模板匹配,检索模型以及深度学习模型为基础的方法原型来进行分场景(问答型、任务型、语聊型)的会话系统构建。
阿里小蜜的3大领域场景的技术实践
智能导购:基于增强学习的智能导购
智能导购主要通过支持和用户的多轮交互,不断的理解和明确用户的意图。并在此基础上利用深度强化学习不断的优化导购的交互过程。下图展示了智能导购的技术架构图。
智能导购的架构图
这里两个核心的问题
a):在多轮交互中理解用户的意图。
b):根据用户的意图结果,优化排序的结果和交互的过程。
下面主要介绍导购意图理解、以及深度增强学习的交互策略优化。
智能导购的意图理解和意图管理:
智能导购下的意图理解主要是识别用户想要购买的商品以及商品对应的属性,相对于传统的意图理解,也带来了几个新的挑战。
第一:用户偏向于短句的表达。因此,识别用户的意图,要结合用户的多轮会话和意图的边界。
第二:在多轮交互中用户会不断的添加或修改意图的子意图,需要维护一份当前识别的意图集合。
第三:商品意图之间存在着互斥,相似,上下位等关系。不同的关系对应的意图管理也不同。
第四:属性意图存在着归类和互斥的问题。
针对短语表达,我们通过品类管理和属性管理维护了一个意图堆,从而较好的解决了短语表示,意图边界和具体的意图切换和修改逻辑。同时,针对较大的商品库问题,我们采用知识图谱结合语义索引的方式,使得商品的识别变得非常高效。下面我们分别介绍下品类管理 和 属性管理。
基于知识图谱和语义索引的品类管理
智能导购场景下的品类管理分为品类识别,以及品类的关系计算。下图是品类关系的架构图。
品类管理架构图
品类识别:
采用了基于知识图谱的识别方案和基于语义索引及dssm的判别模型。
a):基于商品知识图谱的识别方案:
基于知识图谱复杂的结构化能力,做商品的类目识别。是我们商品识别的基础。
b):基于语义索引及dssm商品识别模型的方案:
知识图谱的识别方案的优势是在于准确率高,但是不能覆盖所有的case。因此,我们提出了一种基于语义索引和dssm结合的商品识别方案兜底。
基于语义索引和dssm的商品识别方案
语义索引的构造:
通常语义索引的构造有基于本体的方式,基于LSI的方式。我们用了一种结合搜索点击数据和词向量的方式构造的语义索引。主要包括下面几步:
第一步:利用搜索点击行为,提取分词到类目的候选。
第二步:基于词向量,计算分词和候选类目的相似性,对索引重排序。
基于dssm的商品识别:
dssm是微软提出的一种用于query和doc匹配的有监督的深度语义匹配网络,能够较好的解决词汇鸿沟的问题,捕捉句子的内在语义。本文以dssm作为基础,构建了query和候选的类目的相似度计算模型。取得了较好的效果,模型的acc在测试集上有92%左右。
dssm模型的网络结构图
样本的构造:训练的正样本是通过搜索日志中的搜索query和点击类目构造的。负样本则是通过利用query和点击的类目作为种子,检索出来一些相似的类目,将不在正样本中的类目作为负样本。正负样本的比例1:1。
品类关系计算
品类关系的计算主要用于智能导购的意图管理中,这里主要考虑的几种关系是:上下位关系和相似关系。举个例子,用户的第一个意图是要买衣服,当后面的意图说要买水杯的时候,之前衣服所带有的属性就不应该被继承给水杯。相反,如果这个时候用户说的是要裤子,由于裤子是衣服的下位词,则之前在衣服上的属性就应该被继承下来。
上下位关系的计算2种方案:
a):采用基于知识图谱的关系运算。
b):通过用户的搜索query的提取。相似性计算的两种方案:
a):基于相同的上位词。比方说小米,华为的上位词都是手机,则他们相似。
b):基于fast-text的品类词的embedding的语义相似度。
基于知识图谱和相似度计算的属性管理
下图是属性管理的架构图:
属性管理架构图
整体上属性管理包括属性识别和属性关系计算两个核心模块,思路和品类管理较为相似。这里就不在详细介绍了。
深度强化学习的探索及尝试
强化学习是agent从环境到行为的映射学习,目标是奖励信号(强化信号)函数值最大,由环境提供强化信号评价产生动作的好坏。agent通过不断的探索外部的环境,来得到一个最优的决策策略,适合于序列决策问题。图11是一个强化学习的model和环境交互的展示。
env-model的交互图
深度强化学习是结合了深度学习的强化学习,主要利用深度学习强大的非线性表达能力,来表示agent面对的state和state上决策逻辑。
目前我们用DRL主要来优化我们的交互策略。因此,我们的设定是,用户是强化学习中的env,而机器是model。action是本轮是否出主动反问的交互,还是直接出搜索结果。
状态(state)的设计:
这里状态的设计主要考虑,用户的多轮意图、用户的人群划分、以及每一轮交互的产品的信息作为当前的机器感知到的状态。
state = ( intent1, query1, price1, is_click, query_item_sim, …, power, user_inter, age)
其中intent1表明的是用户当前的意图,query1表示的用户的原始query。price1表示当前展现给用户的商品的均价,is_click表示本轮交互是否发生点击,query_item_sim表示query和item的相似度。power表示是用户的购买力,user_inter表示用户的兴趣, age 表示用户的年龄。
reward的设计:
由于最终衡量的是用户的成交和点击率和对话的轮数。因此reward的设计主要包括下面3个方面:
a):用户的点击的reward设置成1
b):成交设置成[ 1 + math.log(price + 1.0) ]
c):其余的设置成0.1
DRL的方案的选型:
这里具体的方案,主要采用了 DQN, policy-gradient 和 A3C的三种方案。
智能服务:基于知识图谱构建与检索模型的技术实践
智能服务的特点:有领域知识的概念,且知识之间的关联性高,并且对精准度要求比较高
基于问答型场景的特点,我们在技术选型上采用了知识图谱构建+检索模型相结合的方式来进行核心匹配模型的设计。
知识图谱的构建我们会从两个角度来进行抽象,一个是实体维度的挖掘,一个是短句维度进行挖掘,通过在淘宝平台上积累的大量属于以及互联网数据,通过主题模型的方式进行挖掘、标注与清洗,再通过预设定好的关系进行实体之间关系的定义最终形成知识图谱。基本的挖掘框架流程如下:
知识图谱的实体和短语挖掘流程
挖掘构建的知识图谱示例如图:
具体的知识图谱的示例
基于知识图谱的匹配模式具备以下几个优点:
(1).在对话结构和流程的设计中支持实体间的上下文会话识别与推理
(2).通常在一般型问答的准确率相对比较高(当然具备推理型场景的需要特殊的设计,会有些复杂)
同样也有明显的缺点:
(1).模型构建初期可能会存在数据的松散和覆盖率问题,导致匹配的覆盖率缺失;
(2).对于知识图谱增量维护相比传统的QA Pair对知识的维护上的成本会更大一些;
因此我们在阿里小蜜的问答型设计中,还是融入了传统的基于检索模型的对话匹配。
其在线基本流程分为:
(1).提问预处理:分词、指代消解、纠错等基本文本处理流程;
(2).检索召回:通过检索的方式在候选数据中召回可能的匹配候选数据;
(3).计算:通过Query结合上下文模型与候选数据进行计算,通过我们采用文本之间的距离计算方式(余弦相似度、编辑距离)以及分类模型相结合的方式进行计算;
(4).最终根据返回的候选集打分阈值进行最终的产品流程设计;
离线流程分为:
(1).知识数据的索引化;
(2).离线文本模型的构建:例如Term-Weight计算等;
检索模型整体流程如图:
检索模型的流程图
智能聊天:基于检索模型和深度学习模型相结合的聊天应用
智能聊天的特点:非面向目标,语义意图不明确,通常期待的是语义相关性和渐进性,对准确率要求相对较低
面向open domain的聊天机器人目前无论在学术界还是在工业界都是一大难题,通常在目前这个阶段我们有两种方式来做对话设计:
一种是学术界非常火爆的Deep Learning生成模型方式,通过Encoder-Decoder模型通过LSTM的方式进行Sequence to Sequence生成,如图:
seq2seq网络结构图
Generation Model(生成模型):
优点:通过深层语义方式进行答案生成,答案不受语料库规模限制
缺点:模型的可解释性不强,且难以保证一致性和合理性回答
另外一种方式就是通过传统的检索模型的方式来构建语聊的问答匹配。
Retrieval Model(检索模型):
优点:答案在预设的语料库中,可控,匹配模型相对简单,可解释性强
缺点:在一定程度上缺乏一些语义性,且有固定语料库的局限性
因此在阿里小蜜的聊天引擎中,我们结合了两者各自的优势,将两个模型进行了融合形成了阿里小蜜聊天引擎的核心。先通过传统的检索模型检索出候选集数据,然后通过Seq2Seq Model对候选集进行Rerank,重排序后超过制定的阈值就进行输出,不到阈值就通过Seq2Seq Model进行答案生成,整体流程图如下:
小蜜的闲聊模块
未来技术的展望
目前的人工智能领域任然处在弱人工智能阶段,特别是从感知到认知领域需要提升的空间还非常大。智能人机交互在面向目标的领域已经可以与实际工业场景紧密结合并产生巨大价值,随着人工智能技术的不断发展,未来智能人机交互领域的发展还将会有不断的提升,对于未来技术的发展我们值得期待和展望:
1、 数据的不断积累,以及领域知识图谱的不断完善与构建将不断助推智能人机交互的不断提升;
2、 面向任务的垂直细分领域机器人的构建将是之后机器人不断爆发的增长点,open domain的互动机器人在未来一段时间还需要不断提升与摸索;
3、 随着分布式计算能力的不断提升,深度学习在席卷了图像、语音等领域后,在NLP(自然语言处理)领域将会继续发展,在对话、QA领域的学术研究将会持续活跃;
在未来随着学术界和工业界的不断结合与积累,期待人工智能电影中的场景早日实现,人人都能拥有自己的智能“小蜜”。